1.TiDB 基础架构
1.1TiDB 的架构和基本原理文章:
2. 进阶学习资料
2.1 内核
TiDB 内核包括了 TiDB 和 TiKV 所有组件。选手可以在项目中为 TiDB 性能、稳定性、易用性等各方面做出提升。
2.1.1 TiDB
各模块解析
TiDB 是集群的 SQL 层,承担了与客户端通讯(协议层)、语法解析(SQL Parser)、查询优化(Optimizer)、执行查询计划等工作。
Protocol Layer
TiDB 的协议兼容 MySQL,具体 MySQL 的协议细节可以参考 MySQL Protocol 。
SQL Parser
TiDB 的 Parser 分为两块,第一部分是 Lexer,是用 Golang 手动写的;第二部分是 Parser,用 goyacc 实现。Parser 实现阅读这篇文章:TiDB 源码阅读系列文章(五)TiDB SQL Parser 的实现 ,如果想要深入理解 yacc 的语法,推荐阅读 《flex & bison》 。
Schema 管理 & DDL
TiDB 实现了 Google F1 的 在线 Schema 变更算法 ,这个算法比较复杂,可以参考这篇解读文章 。TiDB 的实现可以参考 TiDB 的异步 schema 变更实现 ,源码解析可以参考:TiDB 源码阅读系列文章(十七)DDL 源码解析
表达式
这篇 为 TiDB 重构 built-in 函数 文章,描述了如何利用新的计算框架为 TiDB 重写或新增 built-in 函数。
SQL Optimizer
SQL 优化器大多数逻辑都在 plan 这个包下,与之相关的还有统计信息以及 Range 计算模块。统计信息在下一章节描述。Range 计算在 ranger 包下。文章可以参考:
- TiDB 源码阅读系列文章(六)Select 语句概览
- TiDB 源码阅读系列文章(七)基于规则的优化
- TiDB 源码阅读系列文章(二十一)基于规则的优化 II
- TiDB 源码阅读系列文章(八)基于代价的优化
- TiDB 源码阅读系列文章(十二)统计信息(上)
- TiDB 源码阅读系列文章(十三)索引范围计算简介
- TiDB 源码阅读系列文章(十四)统计信息(下)
执行引擎
执行器由两部分组成,一部分在 TiDB 端 ,另一部分在 TiKV(或 Mock-TiKV ) 中,Mock-TiKV 主要用来做单元测试,里面部分实现了 TiKV 的逻辑。
这部分的作用是严格按照物理算子的要求,处理数据,产生结果。MPP and SMP in TiDB 这篇文章,介绍了一点执行器的架构。源码解析可以参考:
- TiDB 源码阅读系列文章(十)Chunk 和执行框架简介
- TiDB 源码阅读系列文章(九)Hash Join
- TiDB 源码阅读系列文章(十一)Index Lookup Join
- TiDB 源码阅读系列文章(十五)Sort Merge Join
- TiDB 源码阅读系列文章(二十二)Hash Aggregation
TiKV Client
TiKV Client 是 TiDB 中负责跟 TiKV 交互的模块,这里会有两阶段提交,Coprocessor 交互等等。目前 TiKV Client 有两个语言的版本,第一个是 Golang 的,代码位置在 store/tikv 。
这里有两个简单的例子,如何调用 ticlient 的 KV 接口:benchkv, benchrawkv
另一个版本是 Java 的,在 tikv-client-lib-java 中,主要是个 TiSpark 项目用。
Rust-client,在 client-rust,目前功能还不是很丰富,大家可以尝尝鲜。
源码解析:
分布式事务
TiDB 支持分布式事务,实现原理参考自 Percolator,是一个优化过的 2pc 算法。在 TiDB 中的实现参考 Transaction in TiDB。原始的 Percolator 是一个乐观的事务算法,在 3.0 里面 TiDB 引入悲观事务(实验性)特性,具体实现原理可以参考:TiDB 新特性漫谈:悲观事务。
TiDB 侧的事务逻辑可以参考 TiDB 源码阅读系列文章(十九)tikv-client(下) 。
TiDB 读写代码主流程
https://asktug.com/t/topic/752793
https://asktug.com/t/topic/695190
TiDB 常见问题(本地部署、性能调优等)
测试集群性能
TiDB/TiKV 性能调优
理解 TiDB 执行计划 介绍如何使用 EXPLAIN 语句来理解 TiDB 是如何执行某个查询的。
SQL 优化流程概览 介绍 TiDB 可以使用的几种优化,以提高查询性能。
控制执行计划 介绍如何控制执行计划的生成。TiDB 的执行计划非最优时,建议控制执行计划。
TiDB 性能调优 (视频)
调优工具
如果我们需要发现 TiKV 的性能瓶颈,我们首先要通过 Profile 工具来定位,这个给大家提供两个我们常用的 Profile 工具供大家参考。
- TiKV 火焰图工具
- VTune 分析 hotspots 指南
2.1.2 TiKV
TiKV 是 TiDB 的底层存储,这里有一个深入介绍 TiKV 原理的系列文章:Deep Dive Into TiKV 和 TiKV 源码解析系列文章 。
TiKV 内部可分为多层,每层有各自的功能,按从底向上排列:
- RocksDB
- Raft
- Raft KV
- MVCC
- TXN KV
- Coprocessor
RocksDB 是一个单机存储引擎,存放 TiKV 所有数据,提供单机存储的 KV API。详情参见 。
Raft 是一种一致性算法,在 TiKV 中代表了一致性层,使各个 TiKV 之间的状态能达成一致。负责 TiKV 副本之间的拷贝,是 TiDB 高可用的基石。详情参见。
RaftKV 在 RocksDB 和 Raft 之上,结合两者,提供了分布式强一致性的基础 KV API。
MVCC 顾名思义,提供了多版本并发控制的 API,此外还提供了事务 API。MVCC 层通过对 key 进行特殊编码(编进 Timestamp)实现了多版本和事务。
TXN KV 在 RaftKV 和 MVCC 之上,结合两者,提供了分布式事务和多版本并发控制。TiDB会调用它的 API。
Coprocessor 负责处理 TiDB 下推的部分算子,在更靠近数据的地方,承担部分的计算逻辑。Coprocessor 在 RaftKV 和 MVCC 层之上。TiDB 会将查询转化成一个 DAG,DAG 包含了下推的表达式,Coprocessor 根据表达式计算 TiKV 中的数据,将计算结果返回给 TiDB。
Placement Driver (PD)
PD 在集群中的地位是一个逻辑上的单点,类似于很多系统中都有的 master server 或者 meta server 之类的组件。PD 的内部结构是多种不同功能的复合体,功能简介可以参考 《PD 调度策略最佳实践》 这篇文章,还有基于源码的介绍 TiKV 源码解析系列 - Placement Driver 和 TiKV 源码浅析 - PD Scheduler 。
embed etcd
etcd 是基于 raft 的分布式 kv 数据库,可以认为是简化版的 tikv,区别是只有一个 raft group,只能存少量数据。
PD 使用了 etcd 提供的 embed 功能,将 etcd 以 library 的方式内嵌进同一进程内,并将 PD 所需要的 HTTP 和 gRPC 服务绑定到 etcd 所监听的端口。
多个 PD 会使用 etcd 的接口选出一个 leader 提供服务,leader 失效时其他 PD 会选出新的 leader 进行服务。
meta 管理及路由
PD 负责管理的元信息包括全局配置(clusterID,副本数等),tikv 节点的注册上下线,region 信息的创建等。
TiDB 要访问某个 region 的数据时,需要先向 PD 查询此 region 的状态和位置。各个 tikv 实例通过心跳把元信息同步给 PD,PD 将元信息缓存在本地,并要内存中组织成方便查询的结构来提供路由服务。
Timestamp 分配
分布式事务模型需要全局有序的时间戳,PD leader 负责提供 TS 的分配,通过 etcd 来保证即使 leader 切换等状况下 TS 也保持单调递增。
调度
调度主要分为两方面。其一是副本管理(replica placement),需要为数据维护期望的副本数(比如有主机挂了要补充新的),还要满足一些约束条件,比如要保证多个副本尽可能隔离,或是分布到特定的 namespace 等。
另一方面是均衡负载(load rebalance)。需要通过调整 region leader 或 peer 的位置来均衡负载,这部分我们做了多种不同的策略来适应不同的业务场景。
一致性协议 (Raft)
“一致性”是分布式系统要解决的核心课题之一。从 1990 年 paxos 算法的提出开始,基于消息传递的一致性协议成为主流,Raft 便是其中的一种。Raft 集群中的每个节点都处于以下三种状态:Leader,Follower 和 Candidate。在 Raft 协议的运行过程中,每个节点启动时都会进入 Follower 状态,并通过选举(Leader Election)产生一个新的 Leader。Raft 通过 term 的概念来避免脑裂,即任何一个 term 内,都有且只有一个 Leader。在产生 Leader 之后,对该 Raft 集群的读写请求都会走 Leader,其中,写请求的处理过程称为 Log Replication。Leader 除了会将客户端的写入请求持久化到自己的日志中之外,还会将日志同步给其他副本,也就是自己的 Follower,只有收到过半的确认之后,Leader 才会向客户端确认写入完成。之后,Raft 会将日志中的修改应用到自己的状态机中,这一步称为 Apply。这个机制同样适用于修改 Raft 集群本身的配置,比如添加节点、删除节点等。对于读请求,经典的 Raft 的实现与对写入请求的处理是完全相同的,但是可以有一些优化,例如 read index 和 read lease 等。
TiKV 使用 Raft 协议在 Rocksdb 的基础上再封装了一个 KV 引擎,通过这个引擎,对 TiKV 的写入便能够同步到多个副本上了,这样即使部分节点失败,集群仍然是可用的,并且数据仍然是一致的。
存储引擎 (LSM Tree & RocksDB)
LSM tree 是 Log-Structured Merge tree 的缩写,是一种写入速度很快的数据结构,所有的写入都是追加写入,包括插入、更新、删除。相应地,这是以牺牲一部分读取性能为代价的。这个 trade off 的背景是机械硬盘上顺序写入速度远高于随机写入,因此若所有写入操作都是顺序写入,则可以在机械硬盘上实现极高的写入效率。在 ssd 上由于顺序写入与随机写入差别没有那么大,因此优势便不那么显著。
LSM tree 通常由 write ahead log(WAL),memtable 和 sst files 三部分组成。WAL 的作用是保证写入的数据不会丢失,写入操作首先会将要写的内容 append 到 WAL。当写 WAL 完成之后,接下来就是写 memtable,为了优化 cache 以及实现无锁并发修改,memtable 通常实现为 skip list。当写入到 memtable 完成之后,一次写入就完成了。当 memtable 的数据量达到一定阈值之后,会将 memtable 的内容刷到盘上,以 sst (SSTable) 的格式存储下来。sst 会在后台进行 compaction 删除无用数据。
LevelDB 是 Google 开源的一种典型的 LSM tree 实现。RocksDB 是由 Facebook 开源的基于 LevelDB 开发的高性能单机 KV 存储。RocksDB 在 LevelDB 的基础增加了 column families、delete range、多线程 compaction、prefix seek 、user defined properties 等高级特性,功能和性能都有很大提升。
RocksDB (LevelDB) 架构如下图所示,其中 memtable 在写满之后会转化为 immutable memtable 等待 dump 到磁盘上。
RocksDB (LevelDB) 架构
TiKV 使用 RocksDB 作为单机的持久化存储。rust-rocksdb 是对 RocksDB 进行的 rust 封装,TiKV 通过 rust-rocksdb 来操作 RocksDB。
由于 RocksDB 是在 LevelDB 基础上改进优化而来的,大部分 LevelDB 特性得以保留,因此阅读 LevelDB 相关资料对于了解 RocksDB 也是非常有帮助的。
Reference:
LevelDB是Google传奇工程师Jeff Dean和Sanjay Ghemawat开源的KV存储引擎,无论从设计还是代码上都可以用精致优雅来形容,非常值得细细品味。接下来就将用几篇博客来由表及里的介绍LevelDB的设计和代码细节。本文将从设计思路、整体结构、读写流程、压缩流程几个方面来进行介绍,从而能够对LevelDB有一个整体的感知。
https://draveness.me/bigtable-leveldb
LSM Tree 有写放大 (Write Amplification) 和读放大 (Read Amplification) 的问题。在 SSD 上,减少写放大可以提升写入效率,有多篇论文对此进行优化:
-
WiscKey: https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf
-
PebblesDB: http://www.cs.utexas.edu/~vijay/papers/sosp17-pebblesdb.pdf
网络通讯(gRPC)
gRPC 是由 Google 开源的一个高性能的 RPC 框架。它基于 HTTP2 协议,提供全双工的流式接口,支持负载均衡、健康检查和认证功能。目前支持的语言有 C++, go 等 10 多种。我们基于 gRPC core 和 rust futures 实现了一套 rust 的框架 —— grpcio。
2.1.3 Cloud Optimized TiDB
在云上基础设施充分成熟的今天,让 TiDB 拥抱云的能力打造面向云优化的 TiDB。构建面向云优化的 TiDB 内核可以有以下几个 Hackathon 思路:
- TiDB 和云基础设施的适配,充分利用云上的弹性算力和成熟的分布式存储系统。让 TiDB 以更低的成本和更高效率运转在云上
- Serverless
-
AWS Spot Instance https://aws.amazon.com/ec2/spot
-
AWS EFS https://aws.amazon.com/efs/
2.1.4 Tiflash
解决方案
成为一栈式数据服务生态: TiDB 5.0 HTAP 架构设计与场景解析
《实时数据服务平台 — 金融行业实时 HTAP 场景实践》白皮书
场景案例
数据引擎助力车娱融合新业态 让秒杀狂欢更从容丨大促背后的 TiDB
造好新能源车需要想象力和技术,卖好新能源车则需要实时分析能力
TiDB HTAP 助力多点 DMall “业财一体化” 高效经营
TiDB x 某世界 500 强餐饮巨头 | “数据平台”的敏捷之旅
TiDB x 携程 | TiDB 助力携程实时标签处理平台提速
TiDB x Bigo | 选择 TiFlash 打造高效的实时分析平台
TiDB 在 eBay丨亿优百倍 : 商品数据服务 TiDB 性能优化
用户实践
专栏 - TiDB 4.0 试玩体验–Tiflash | TiDB 社区
性能测评
专栏 - TiDB升级、TiFlash测试及对比ClickHouse | TiDB 社区
专栏 - TiFlash5.0.1与4.0.10 对比测试 | TiDB 社区
专栏 - TiFlash 5.x 与 4.x 对比测试 | TiDB 社区
专栏 - TPC-H 下 TiFlash 的扩展性测试报告 - v5.1.0 | TiDB 社区
运维实践
专栏 - TiUP升级TiFlash重启失败解决方案 | TiDB 社区
2.2 工具
TiDB 提供了丰富的生态工具,可以帮助集群运维、诊断、数据流转(数据迁移、数据复制、全量导出、全量导入、备份恢复)和数据校验等。
2.2.1 部署运维
2.2.2 数据流转
2.2.3 集群容灾
2.2.4 数据校验
2.2.5 运维和可视化
2.2.6 工具代码仓库
2.3 生态
TiDB 生态是围绕 TiDB 上下游构建的,这个板块的资料将包括大数据生态接口、TiDB Cloud、应用开发接口等
2.2.1 大数据生态方向
大数据生态方向:TiDB 可以很好的兼容 mysql,所以大部分对 mysql 能用的接口对 TiDB 也适用,但是基于 tidb 独特的架构,社区也针对 TiDB 为各种大数据组件开发了效率更高的连接器。以下是常见的大数据连接器:
2.2.2 TiDB 云上应用开发
基于 TiDB Cloud 的生态集成和云上应用生态开发。
TiDB Cloud Developer Tier 快速上手
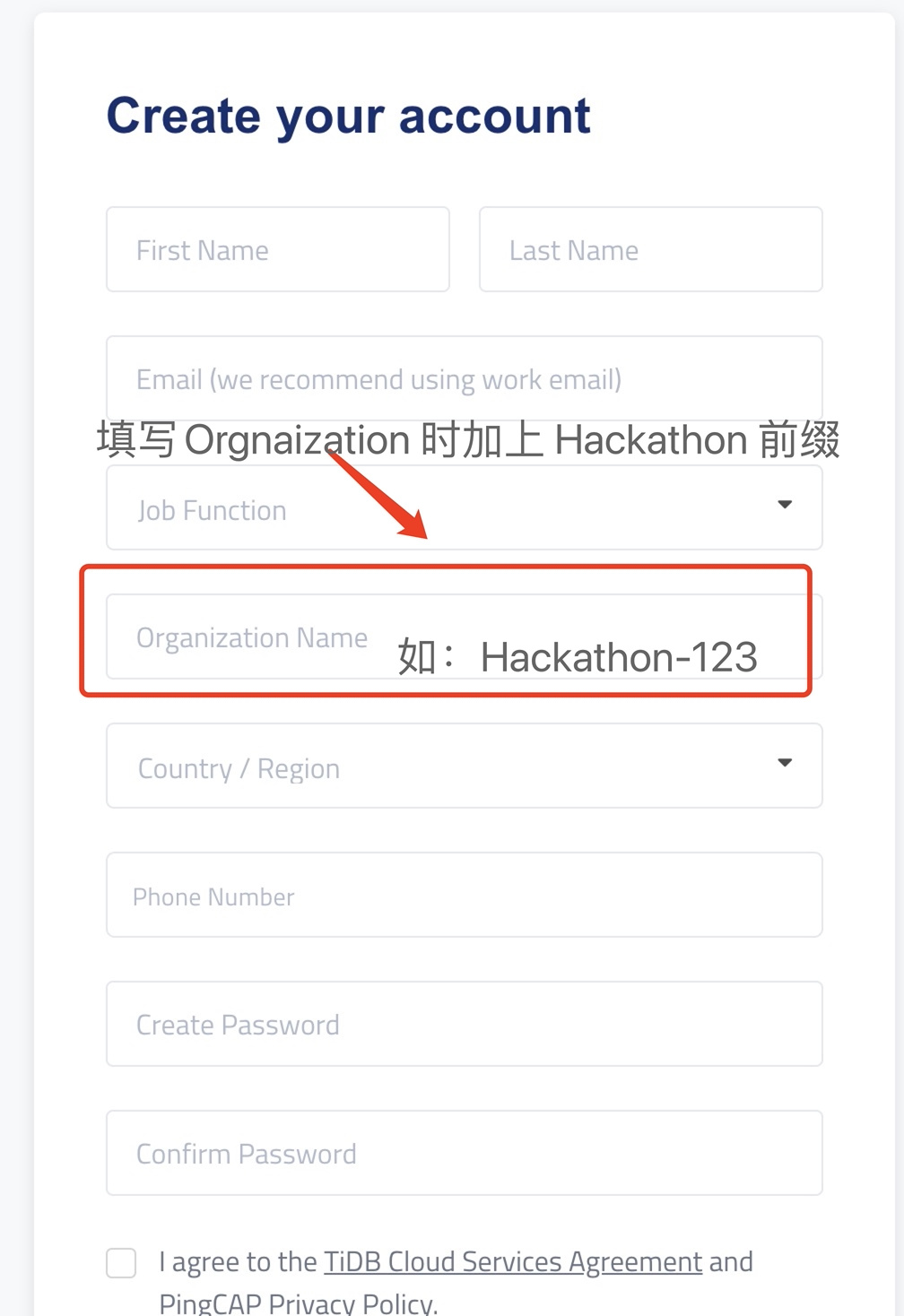
注:TiDB Cloud Tier 提供一年免费的试用套餐,在 Hackathon 比赛中注册使用的同学请在填写Organization 时加上 Hackathon 前缀便于区分,感谢大家~
https://asktug.com/t/topic/274095
2.2.3 TiDB 应用开发
TiDB 支持 MySQL 协议和大部分的 MySQL 特性。一般来说,为了开发基于 TiDB 的应用程序,你可以使用本地驱动/连接或流行的第三方框架,如 ORM 和迁移工具。
此文档是应用开发指南,告诉你如何建立基于TiDB的简单应用。
2.4 其他
2.4.1 chaosmesh
Chaos Mesh 简介
Chaos Mesh 是一个开源的云原生混沌工程平台,提供丰富的故障模拟类型,具有强大的故障场景编排能力,方便用户在开发测试中以及生产环境中模拟现实世界中可能出现的各类异常,帮助用户发现系统潜在的问题。Chaos Mesh 提供完善的可视化操作,旨在降低用户进行混沌工程的门槛。用户可以方便地在 Web UI 界面上设计自己的混沌场景,以及监控混沌实验的运行状态。
Chaos Mesh 的核心优势
Chaos Mesh 作为业内领先的混沌测试平台,具备以下核心优势:
- 核心能力稳固:Chaos Mesh 起源于 TiDB 的核心测试平台,发布初期即继承了大量 TiDB 已有的测试经验。
- 被充分验证:Chaos Mesh 被众多公司以及组织所使用,例如腾讯和美团等;同时被用于众多知名分布式系统的测试体系中,例如 Apache APISIX 和 RabbitMQ 等。
- 系统易用性强:图形化操作和基于 Kubernetes 的使用方式,充分利用了自动化能力。
- 云原生:Chaos Mesh 原生支持 Kubernetes 环境,提供了强悍的自动化能力。
- 丰富的故障模拟场景:Chaos Mesh 几乎涵盖了分布式测试体系中基础故障模拟的绝大多数场景。
- 灵活的实验编排能力:用户可以通过平台设计自己的混沌实验场景,场景可包含多个混沌实验编排,以及应用状态检查等。
- 安全性高:Chaos Mesh 具有多层次安全控制设计,提供高安全性。
- 活跃的社区:Chaos Mesh 为全球知名开源混沌测试平台,CNCF 开源基金会孵化项目。
- 强大的扩展能力:Chaos Mesh 为故障测试类型扩展和功能扩展提供了充分的扩展能力。
架构概览
Chaos Mesh 基于 Kubernetes CRD (Custom Resource Definition) 构建,根据不同的故障类型定义多个 CRD 类型,并为不同的 CRD 对象实现单独的 Controller 以管理不同的混沌实验。Chaos Mesh 主要包含以下三个组件:
- Chaos Dashboard :Chaos Mesh 的可视化组件,提供了一套用户友好的 Web 界面,用户可通过该界面对混沌实验进行操作和观测。同时,Chaos Dashboard 还提供了 RBAC 权限管理机制。
- Chaos Controller Manager :Chaos Mesh 的核心逻辑组件,主要负责混沌实验的调度与管理。该组件包含多个 CRD Controller,例如 Workflow Controller、Scheduler Controller 以及各类故障类型的 Controller。
- Chaos Daemon :Chaos Mesh 的主要执行组件。Chaos Daemon 以 DaemonSet 的方式运行,默认拥有 Privileged 权限(可以关闭)。该组件主要通过侵入目标 Pod Namespace 的方式干扰具体的网络设备、文件系统、内核等。
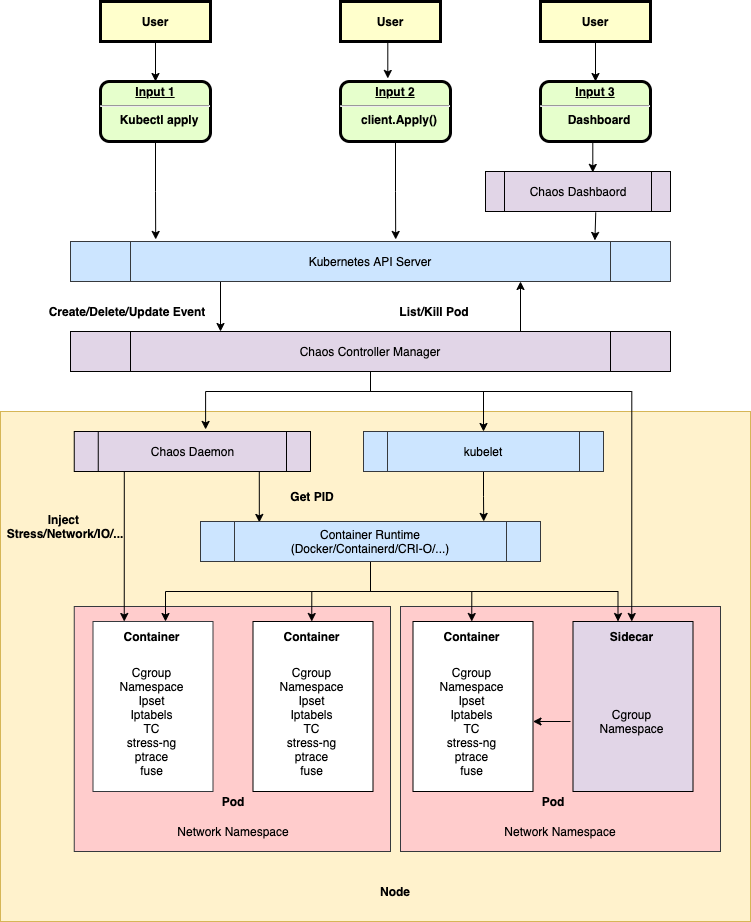
Chaos Mesh 的整体架构如上图所展示,可以自上而下分为三个部分:
- 用户输入和观测的部分。用户输入以用户操作 (User) 为起点到达 Kubernetes API Server。用户不直接和 Chaos Mesh 的 Controller 交互,一切用户操作最终都将反映为某个 Chaos 资源的变更(比如 NetworkChaos 资源的变更)。
- 监听资源变化、调度 Workflow 和开展混沌实验的部分。Chaos Mesh 的 Controller 只接受来自 Kubernetes API Server 的事件,这种事件描述某个 Chaos 资源的变更,例如新的 Workflow 对象或者 Chaos 对象被创建。
- 具体节点故障的注入部分。该部分主要由 Chaos Daemon 组件负责,接受来自 Chaos Controller Manager 组件的指令,侵入到目标 Pod 的 Namespace 下,执行具体的故障注入。例如设置 TC 网络规则,启动 stress-ng 进程抢占 CPU 或内存资源等。
更多介绍可看:https://chaos-mesh.org/website-zh/docs/next/
推荐阅读
-
基于 k8s 与 Chaos Mesh 构建数据库混沌实验日报系统
https://asktug.com/t/topic/94980
- Chaos Mesh® 在腾讯——腾讯互娱混沌工程实践
https://asktug.com/t/topic/93342
- Chaos Mesh 助力 Apache APISIX 提升稳定性
https://asktug.com/t/topic/93712
3. 视频学习资料
PingCAP Education 致力于打造专业而系统的 TiDB 课程内容和开放的全球认证体系,为 TiDB 用户和 IT 专业人员提供卓越的学习体验,服务于高校学生、社区开发者、合作伙伴、企业用户等 TiDB 技术人才群体。所有课程只需要 登陆官方页面 即可观看哦~
3.1 TiDB 快速起步
在 Get Started with TiDB 课程中,您将学习 TiDB 由来、发展与演进,理解 TiDB 5.0 数据库的体系架构、技术创新、关键特性、应用案例与适用场景。
3.2 TiDB 系统基础管理
在 TiDB 系统管理基础课程中,您将学习 TiDB 数据库的体系架构、设计理念与各个组件的运行原理。学习并掌握 TiDB 数据库的管理。掌握 TiDB 的数据迁移、同步、复制和备份恢复方法。熟悉主要生态工具的适用范围、场景和基本使用方法。
3.3 TiDB 高级系统管理
通过本课程,您将深入了解 TiDB 数据库的体系架构、设计理念与各个组件的运行原理。学习并掌握 TiDB 数据库的体系架构,设计实践,性能监控、参数优化、故障排除、SQL优化和高可用设计。
3.4 Talent Plan 之 TinyKV 学习营推荐课程
本课程可以帮助 TinyKV 学习营同学快速了解工业级产品 TiKV 的架构及核心组件,TiKV 上层组件 TiDB Server,帮助同学们快速理清 LSM 存储引擎,Raft 一致性协议,Multi-Raft 以及分布式事务在存储层的作用和位置。
Talent Plan 之 TinyKV 学习营推荐课程在线观看
4. 其他参考资料
专栏 TiDB 线上社区的用户在持续产出基于 TiDB 的实践案例、运维实战和测评文章,用经验说话,扫平实际使用过程中的障碍。
PingCAP 博客 PingCAP 官方博客围绕 TiDB、TiKV、Chaos Mesh® 及相关生态展开,收录来自 PingCAP 员工及社区成员的技术干货,包含原理解析、应用实践、架构思考等多种内容,已经推出了“TiDB 源码阅读”、“TiKV 源码解析”、“分布式系统前沿技术”等系列文章,带你饱览分布式、云原生领域前沿的创新实现。
常见问题解答 常见问题集合,没准儿能解决你的问题
数据库架构选型指南 帮你解决数据库架构选型的烦恼
更多材料:
PE brochure 2021.pdf (2.2 MB)
TiDB 产品与解决方案 2021.pdf (10.3 MB)
TiDB 数据库开发规范.pdf (5.5 MB)
TiDB行业案例集2021.pdf (10.2 MB)
白皮书-金融行业实时HTAP场景实践.pdf (8.7 MB)
基于TiDB 与 Flink 的实时数仓最佳实践白皮书.pdf (5.1 MB)
PCTA 考试资料:
TiDB 备份恢复.pdf (155.9 KB)
TIDB 数据同步复制.pdf (184.4 KB)
TIDB集群管理.pdf (309.9 KB)
TiDB数据迁移.pdf (141.2 KB)
TiDB体系架构.pdf (169.3 KB)
PCTP 考试资料:
PCTP.pdf (433.1 KB)