By Jinlong Liu
ps:内容稍微有些老旧, 参考一下大致的流程和勘误
1. 概述
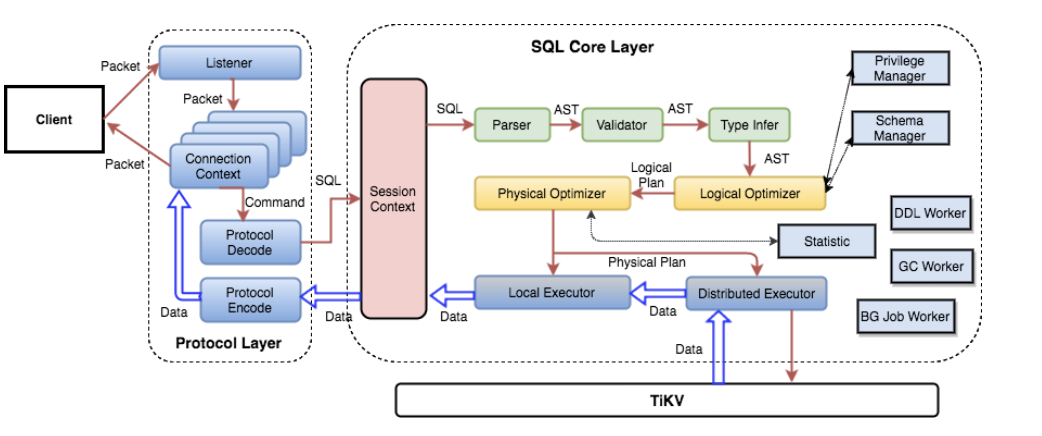
[TiDB]
-
建立链接 tidb 收到来自客户端的 select 请求。
-
tidb 分析该请求
-
与pd交互,tidb 向 pd 获取 start_ts 信息。
-
tidb 从缓存中获取 information_schema(启动的时候缓存这些信息),若没有,从 tikv 获取 information_schema。
-
tidb 从 information_schema 中获取到当前用户所操作的 table 的元信息。
-
tidb 根据准备好的执行计划,将 tidb 这边的 keyrange 带上 table 的元信息后组织成 tikv 的 keyrange。
-
tidb 从缓存或 PD 获取每个 keyrange 所在的 regions 信息。
-
tidb 根据 regions 对 keyrange 进行分组。
修改:第3步,因为我们是 Snapshot Isolation, 所以所有的 tidb 读写请求都有一个 start_ts作为当前事务的一个版本号。 现在我们只讨论需不需要跟 PD 获取实际的 tso 作为 start_ts.
理论上,所有的事务都会在事务 begin 时向 PD 获取一个 tso 作为当前的 start_ts. 只有符合以下所有条件的事务,才会直接使用 u64::MAX 作为当前事务的 start_ts(这算是一个小优化) :
-
单条语句 autoCommit
-
读语句
-
只涉及一个 key 的查询,也就是点查。
[TIKV]
-
grpc请求(server.grpc-concurrency),存在一个连接池属于长链接.
-
tidb 并发向所有 regions 对应的 tikv 分发 select 请求。
3.tikv 根据 tidb 的请求进行数据的筛选过滤,然后返回给 tidb。(readpool.storage readpool.coprocessor)
[TiDB]
-
tidb 收到所有结果后,整理数据。
-
tidb 执行下一个执行计划 5,或返回客户端数据。
修改:第2步,获取数据所对应的 region 定位信息后,需要通过 grpc 发送请求到对应 tikv 节点。并且如果涉及同一个 tikv 的 rpc请求会使用 Batch 的方式,也就是说对 Tikv 只发起一次 rpc 请求。
总结:简单的说,就是 TiDB 在收到客户端的查询请求后,切分成一个个以 Range 为单位的子任务, 并行下发到所在的 TIKV 上。
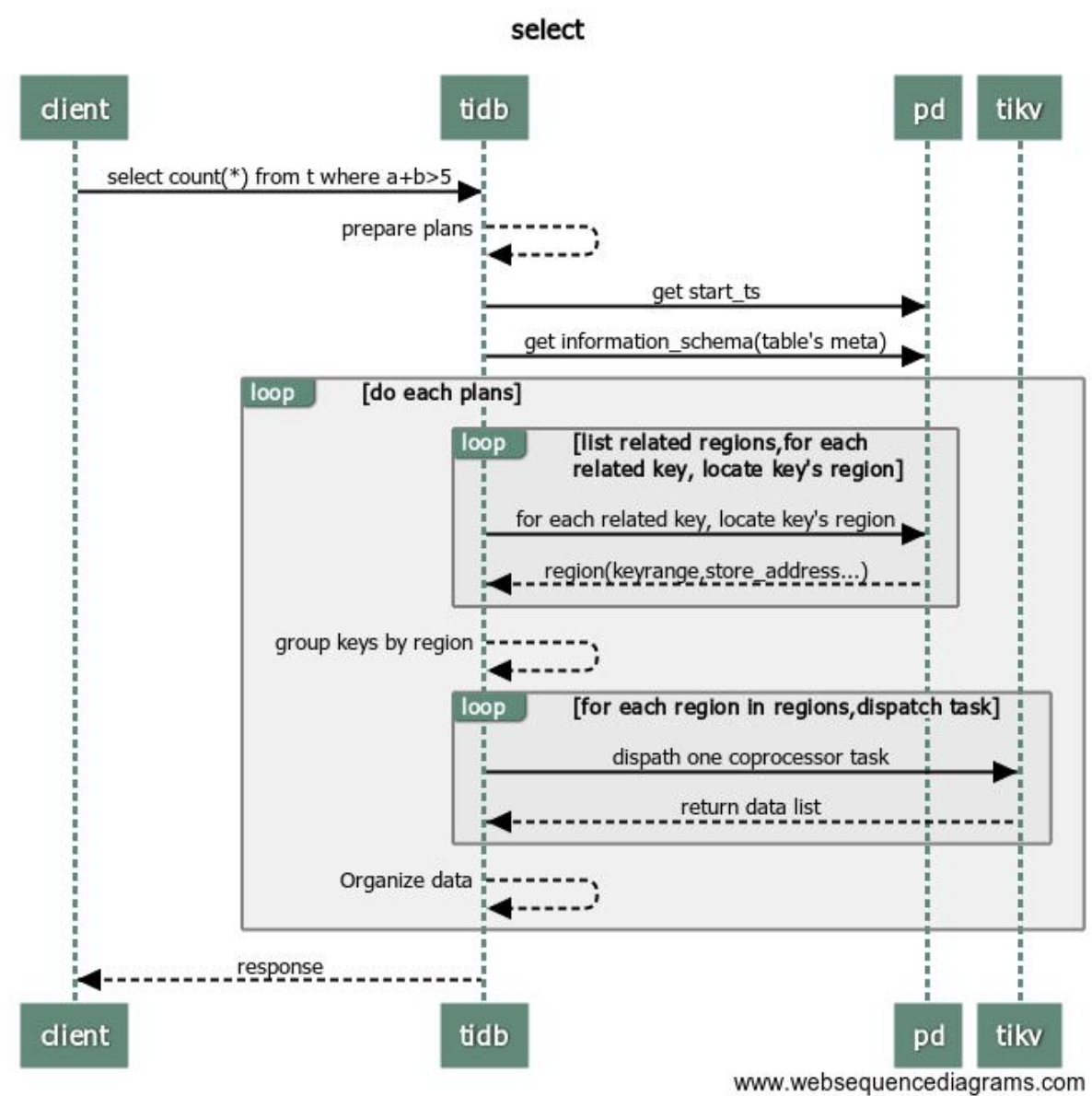
1. TiDB 层
1. 协议层入口
当和客户端的连接建立好之后,TiDB 中会有一个 Goroutine 监听端口,等待从客户端发来的包,并对发来的包做处理。使用 clientConn.Run() 在循环中,不断的读取网络包。然后调用 dispatch() 方法处理收到的请求,然后根据 Command 的类型,调用对应的处理函数。最常用的 Command 是 COM_QUERY,对于大多数 SQL 语句,只要不是用 Prepared 方式,都是 COM_QUERY。 对于 Command Query,从客户端发送来的主要是 SQL 文本,处理函数是 handleQuery()。
tidb 的监控上面有一个 goroutine 的数量,这个跟 connection 应该是正相关的。一个 connection 至少有一个 read 和 一个 write goroutine,但是系统中有一组其他模块固定使用的 goroutine,剩下的就是动态的 goroutine(主要是一些并行算子,回动态创建,算子结束后自动释放,所以可以结合 connection count 和 goroutine 的数量来看是否有多个并行算子,比如 connection count 没有变化,但是 gorontine 数量升高了,就有可能是有并行算子在执行)
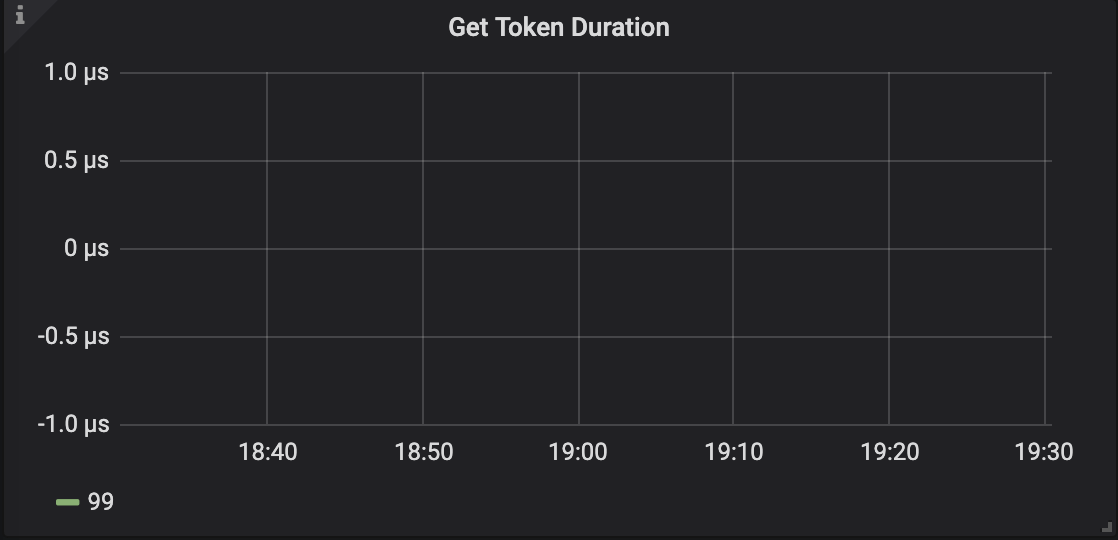
默认情况下,连接数限制为1000,由 token-limit 参数控制。如果这个参数设置过小,新建连接会花费更长的时间,正常情况下,”Get Token Duration” 应该小于 2us。
注: OLTP 场景下,建议连接数应该少于500个,并且需要密切关注不同 tidb-server 之间连接数的均匀分布。
注: OLTP 场景下,建议 99.9%的查询延迟都应该小于500ms。 Heap Memory,当本地 latch 启用的情况下,每个 TIDB server 使用的内存大小应该小于 3G ,如果禁用,则应该小于 1GB。
2. Parser 模块 (Lexer & Yacc)
TiDB使用词法分析器 lex 进行抽象+语法分析器 yacc 生成树形结构。这两个组件共同构成了 Parser 模块,调用 Parser,可以将文本解析成结构化数据,也就是抽象语法树 (AST)。
Grafana Metrics 提供了 SQL 解析成 AST 所消耗的时间,正常情况下应小于 10ms。
平均解析时间为:tidb_session_parse_duration_seconds_sum{sql_type=“general”}
/tidb_session_parse_duration_seconds_count{sql_type=“general”}

3. Compile 模块
有了 AST 后 TiDB会将其经过 buildSelect() 函数处理,之后 AST 会变成一个 Plan 的树状结构树。
拿到 AST 之后,就可以做各种验证(预处理,合法性验证,权限检验)、变换、优化,这一系列动作的入口在这里 Compile 函数,最重要的三个步骤:
- plan.Preprocess: 做一些合法性检查以及名字绑定;
- plan.Optimize:制定查询计划,并优化,这是最核心的步骤之一。这里有一个特殊的函数 TryFastPlan,如果这里判断规则可以符合 PointGet,会跳过后续的优化,直接走点查
- 构造 executor.ExecStmt 结构:这个 ExecStmt 结构持有查询计划,是后续执行的基础,非常重要,特别是 Exec 方法(后续会介绍)。
逻辑优化,主要依据关系代数的等价交换规则做一些逻辑变换。其由一系列优化规则组成,对于这些规则会按顺序不断应用到传入的 LogicalPlan Tree 中,详细见 logicalOptimize() 函数。 TiDB 的逻辑优化规则,包括列裁剪、最大最小消除、投影消除、谓词下推,子查询去关联化,外连接消除,聚合消除等等。
物理优化(dagPhysicalOptimize 函数),基于逻辑优化结果,会考虑数据的分布,决定如何选择物理算子。选择最优执行路径,这个选择过程取决于统计信息。TiDB 的物理优化规则,主要通过对查询的数据读取、表连接方式、表连接顺序、排序等技术进行优化。

注:对于 insert 语句可以参考 planBuilder.buildInsert() (补全对象信息、处理 lists 中的数据)insert 介绍逻辑 https://pingcap.com/blog-cn/tidb-source-code-reading-4/
Grafana Metrics 提供了 由 AST 解析成查询计划所消耗的时间,正常情况下应小于 30ms。
平均执行计划生成时间为:tidb_session_compile_duration_seconds_sum/tidb_session_compile_duration_seconds_count
4. 生成 Executor
在这个过程中,TiDB 会将 plan 转换成 executor,这样执行引擎即可通过 executor 执行优化器定下的查询计划,具体的代码见 ExecStmt.buildExecutor()。
5. 运行 Executor
TiDB 会将所有的物理 Executor 构成一个树状结构,每一层通过调用下一层的 Next/NextChunk() 方法获取结果。
例如:SELECT c1 FROM t WHERE c2 > 1;
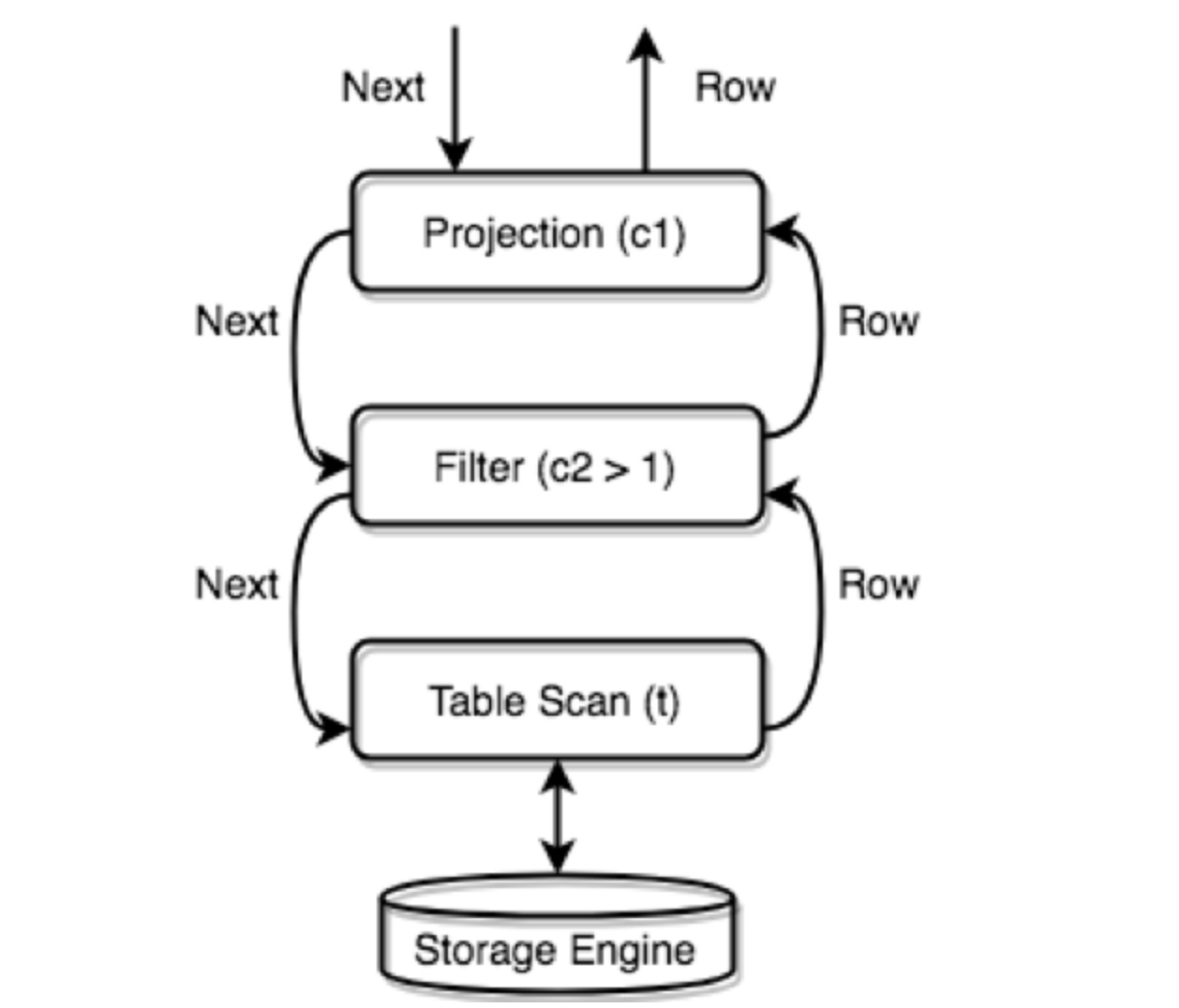
chunk 的大小可以由参数 tidb_max_chunk_size(session/global) 参数控制一次性取多少行。Executor 根据指定的行数请求执行一次性内存分配。建议值:
OLTP APP = 32
OLAP APP = 1024+
3.0版本好像做了一些调整,有两个参数,一个是 init_chunk_size,一个是max_chun_size,也就是说3.0版本可以不用调整了
6. 获取 Key 所在的 Region and TSO
TiDB 通过向 PD 发送请求实现 region 的定位及获取 TSO。PD client 实现了接口 GetRegion 通过调用这个接口,我们就可以定位这个 key 所在的 Region。
为了防止获取一个范围内的多个 Region,重复循环多次调用 GetRegion 这个接口每次读取数据的时候,都需要先去访问 PD,这样会给 PD 带来巨大压力,同时影响请求的性能。Tikv-client 实现了一个 RegionCache 的组件,缓存 Region 信息, 当需要定位 key 所在的 Region 的时候,如果 RegionCache 命中,就不需要访问 PD 。
RegionCache 的内部,有两种数据结构保存 Region 信息,一个是 map,另一个是 b-tree,用 map 可以快速根据 region ID 查找到 Region,用 b-tree 可以根据一个 key 找到包含该 key 的 Region。通过 region cache 提供的 LocateKey 方法,我们可以找到有哪些 region 包含了一个 key range 范围内的数据。如果因为 Region 分裂,Region 迁移导致了 Region 信息变化,请求的 Region 信息就会过期,这时 tikv-server 就会返回 Region 错误。遇到了 Region 错误,后清理 RegionCache(仅清理变化的信息),重新获取最新的 Region 信息,并重新发送请求。
region cache:
先访问 pd 获取 tso,然后访问 tidb-server 本地 region cache,然后按照获得的路由信息,将请求发给 Tikv,如果 Tikv 返回错误说明路由信息过旧,这个时候 tidb-server 会去 pd 重新取 region 的最新路由信息,并更新 region cache。如果,请求发送到 follower 了,Tikv 会返回 not leader 的错误并把谁是 leader 的信息返回给 tidb-server, 然后 tidb-sever 更新 region cache。
TSO获取:
Point Get 也会取 tso, 在 PrepareTxnCtx 时发送 tso 请求到 pd(有计划进行优化)。PrepareTxnCtx 执行阶段很早,在对 SQL 做 parse 之前就执行了。但是 Point Get 虽然去申请了 tso,但是并没有去调用 txnFuture.wait 去读取它。而有一些情况,是直接用 maxTs 构造了一个 Txn 对象,也就是 Point Get 并不会去等待 pd 的返回,但是依然对 pd 造成了一些压力(虽然会 batch)。其他情况,至少会拿一个 tso(start_ts),并且需要注意的是 start_ts 为 0 的情况并不代表没有发送 tso 请求到 pd。
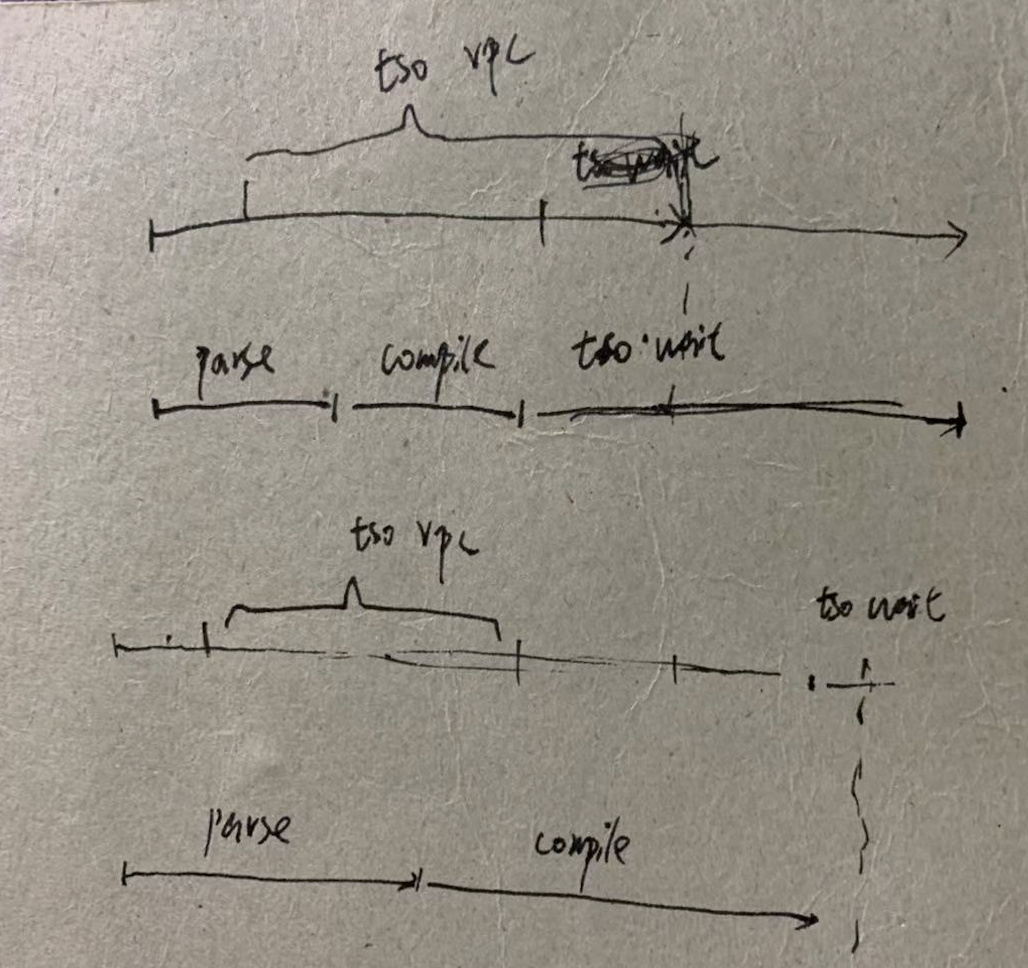
所有 TiDB 与 PD 交互的逻辑都是通过一个 PD Client 的对象进行的,这个对象会在服务器启动时创建 Store 的时候创建出来,创建之后会开启一个新线程,专门负责批量从 PD 获取 TSO,这个线程的工作流程大致流程如下:
- TSO 线程监听一个 channel,如果这个 channel 里有 TSO 请求,那么就会开始向 PD 请求 TSO(如果这个 channel 有多个请求,本次请求会进行 batch)
- 将批量请求而来的的 TSO 分配给这些请求
对于这些 TSO 请求,其实就被分为了三个阶段:
- 将一个 TSO 请求放入这个 channel,对应的函数为 GetTSAsync,调用这个函数会得到一个 tsFuture 对象
- TSO 线程从 channel 拿到请求向 PD 发起 RPC 请求,获取 TSO,获取到 TSO 之后分配给相应的请求
- TSO 分配给相应的请求之后,就可以通过持有的 tsFuture 获取 TSO(调用 tsFuture.Wait())
目前系统没有对第一个阶段设置相应的监控信息,这个过程通常很快,除非 channel 满了,否则 GetTSAsync 函数很快返回,而 channel 满表示 RPC 请求延迟可能过高,所以可以通过 RPC 请求的 Duration 来进一步分析。
- PD TSO RPC Duration : 反应向 PD 发起 RPC 请求的耗时,这个过程慢有两种可能:
- TiDB 和 PD 之间的网络延迟高
- PD 负载太高,能不能及时处理 TSO 的 RPC 请求
- TSO Async Duration: 拿到一个 tsFuture 之后到调用 tsFuture.Wait() 中间的时间消耗,拿到 tsFuture 之后,后续还需要进行 SQL Parse 和 Compile 成执行计划,真正执行的时候才会调用 tsFuture.Wait(),所以这部分延迟太多,可能因为:
- 这个 SQL 很复杂,Parse 花费了很长的时间
- Compile 花费了很长时间
- PD TSO Wait Duration: 我们 C可能拿到一个 tsFuture 之后,很快做完 Parse 和 Compile 的过程,这个时候去调用 tsFuture.Wait(),但是这个时候 PD 的 TSO RPC 还没有返回,我们就需要等,这个时间反应的是这一段的等待时间。
- PD TSO Duration:上面整个过程的时间
所以这一块的正确分析方式是先查看整个 TSO 是否延迟过大,再去查具体是某个阶段延迟过大。
kv get / batch get
[pdclient]
-
get tso
-
region cache
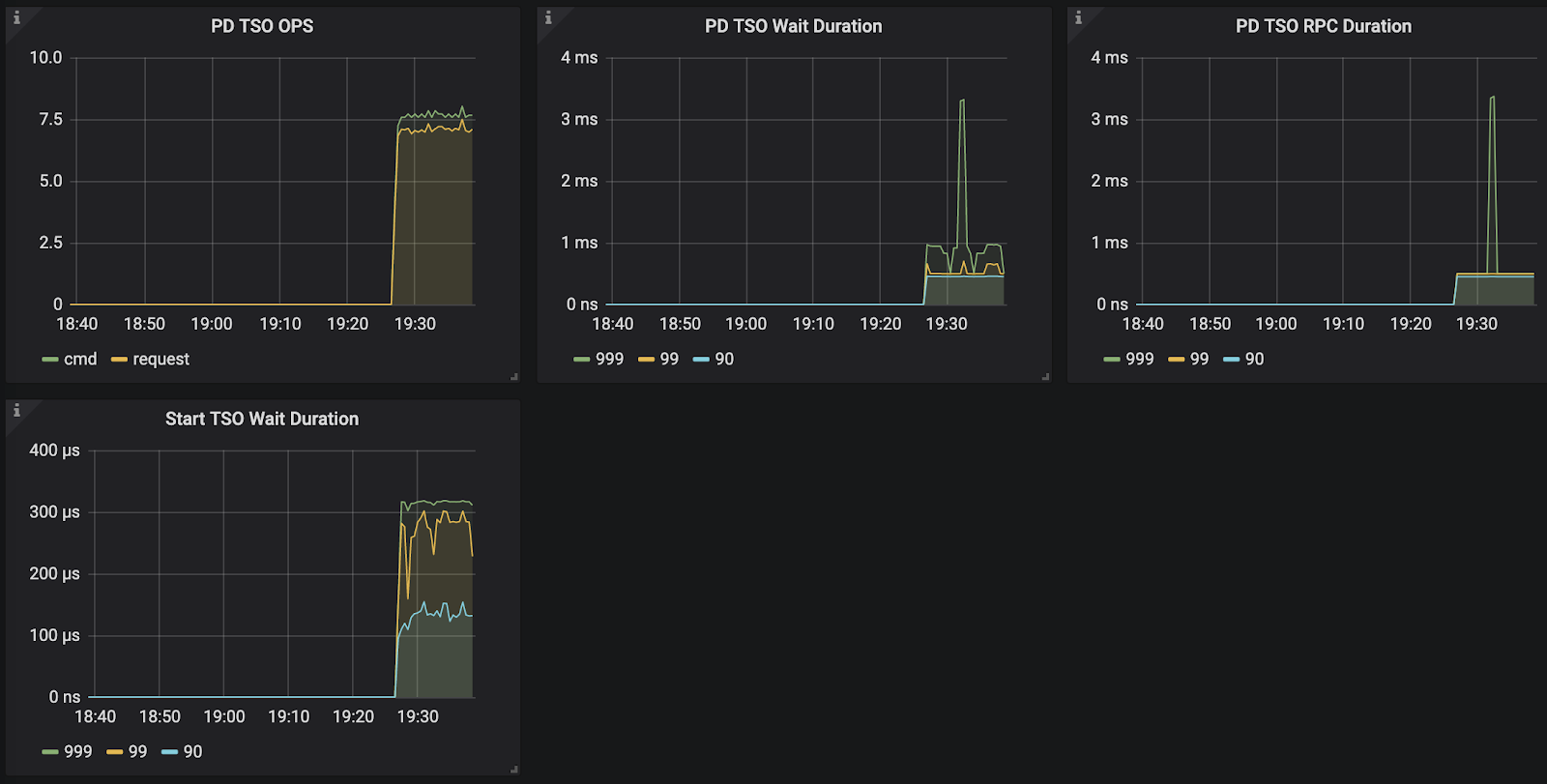
PD TSO Wait Duration : TiDB从PD获取时间戳的延迟时间。如果tidb-server的工作负载非常高,则此值将很高。(读取只向 PD拿一次 Tso 就够了。写入的话,需要拿两次。)
结论:符合预期,因为写流程两阶段提交,需要取两次 tso,包括:start_ts + commit_ts。并且暂时不会支持通过 start_ts 计算出 commit_ts 减少拿的次数。所以在压测场景下,写入场景一般会比读场景的 PD TSO Wait Duration 的指标值高很多。
PD TSO RPC Duration: TiDB的RPC延迟从PD获得时间戳。主要与TiDB和PD之间的延迟有关。参考值:在同一数据中心内小于30ms。
一般处理流程(简化版):
TSO RPC Duration 高:网络或 PD 的问题。建议值 4ms 以内。
TSO Async Wait 高,输入请求的问题,比如 replace into ()() SQL 太长。可以具体看一下 parse & compile 的耗时。从开始往 pd 发请求,到我们查看请求结果,这个是 tso async wait
机器负载高,Go 的 runtime 的问题
如自动提交的点查,是不需要获取 TSO 的,它慢不应该在 PD 监控里找原因。
https://docs.google.com/document/d/1nqtqC-Abh-37PU7KY_HDcGqKMbewgqSwM0hmEsQZ-Z0/edit

[tikv-client]
关于 tikv-client 配置参数:
max-batch-size = 15
批量发送 rpc 封包的最大数量,如果不为 0,将使用 BatchCommands api 发送请求到 TiKV,可以在并发度高的情况降低 rpc 的延迟,推荐不修改该值
grpc-connection-count = 16 跟每个 TiKV 之间建立的最大连接数。
7. DistSQL API
请求的分发与汇总会有很多复杂的处理逻辑,比如上小节说的出错重试、获取路由信息、控制并发度以及结果返回顺序,为了避免这些复杂的逻辑与 SQL 层耦合在一起,TiDB 抽象了一个统一的分布式查询接口,称为 DistSQL API,位于 distsql 这个包中。
DistSQL 是位于 SQL 层和 Coprocessor 之间的一层抽象,它把下层的 Coprocessor 请求封装起来对上层提供一个简单的 Select 方法。执行一个单表的计算任务。最上层的 SQL 语句可能会包含 JOIN,SUBQUERY 等复杂算子,涉及很多的表,而 DistSQL 只涉及到单个表的数据。一个 DistSQL 请求会涉及到多个 Region,我们要对涉及到的每一个 Region 执行一次 Coprocessor 请求。
Tidb-server 对每一个 Tikv-server 地址维护了多个连接,并以 round-robin 算法选择连接发送请求。连接的个数可以在 config 文件里配置,默认是 16 (grpc-connection-count)。
可以通过参数 tidb_distsql_scan_concurrency 参数控制用于同时向 TiKV 发送请求的worker 的数量。每个worker 只能向一个TiKV Region 发送一个 task 任务。

2. TiKV 层
1. gRPC 建立维护和 TiDB-sever 之间的连接
TiDB 和 Tikv-server 之间维护了一个连接池 connArray。TiDB 和 TiKV 之间通过 gRPC 通信,而 gPRC 支持在单 TCP 连接上多路复用,所以多个并发的请求可以在单个连接上执行而不会相互阻塞。 我们知道 当 PD 选举或者 region 分裂等情况出现时,Tidb-server 的请求是无法被及时响应(notleader/staleepoch/serverbusy)。为了解决这个问题,Backoffer 实现了 fork 功能, 在发送每一个子请求的时候,需要 fork 出一个 child Backoffer,child Backoffer 负责单个 RPC 请求的重试,它记录了 parent Backoffer 已经等待的时间,保证总的等待时间,不会超过 query 超时时间。
2. Coprocessor 框架
Task 的定义是能在单个节点上不依赖于和其他节点进行数据交换即可进行的一系列操作,目前只实现了两种 Task:
- CopTask 是需要下推到存储引擎(TiKV)上进行计算的物理计划,每个收到请求的 TiKV 节点都会做相同的操作。
- RootTask 是保留在 TiDB 中进行计算的那部分物理计划。
在 TiDB 中,计算是以 Region 为单位进行,SQL 层会分析出要处理的数据的 Key Range,再将这些 Key Range 根据 PD 中拿到的 Region 信息划分成若干个 Key Range,最后将这些请求发往对应的 Region。
SQL 层会将多个 Region 返回的结果进行汇总,再经过所需的 Operator 处理,生成最终的结果集。
[readpool.storage] kv get
high-concurrency = 4
normal-concurrency = 4
low-concurrency = 4
The CPU usage should be less than concurrency * 90%
[readpool.coprocessor] batch get
high-concurrency = 8
normal-concurrency = 8
low-concurrency = 8
三个优先级队列,最终可以用到 24颗 cpu。这样做的目的是为了隔离。即我们不希望当有很多点查时,阻塞掉全表 count 的请求,反之,也不希望有全表扫的请求阻塞掉所有的点查
The CPU usage should be less than concurrency * 90%
[TIKV Duration]
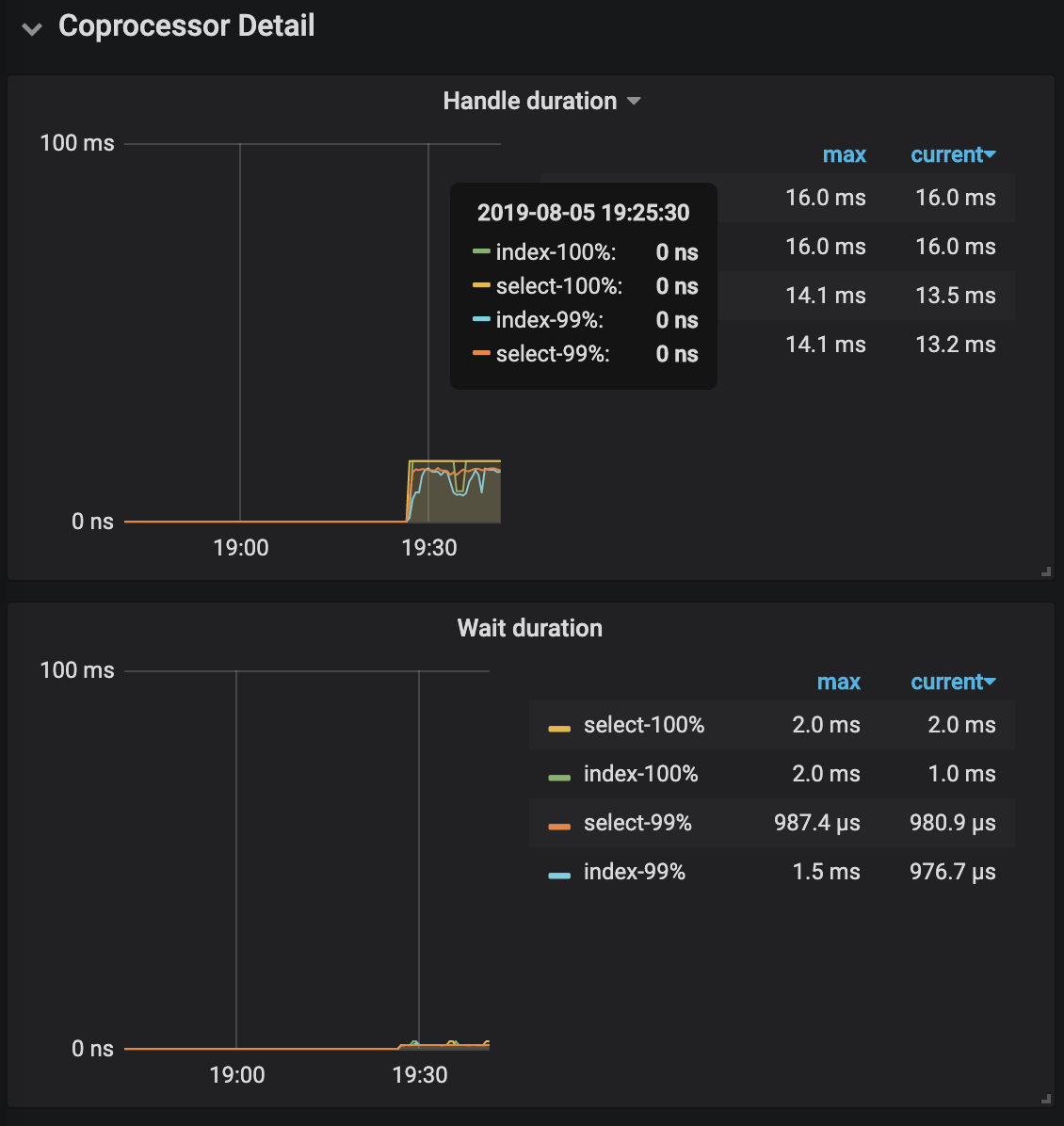
- async-snapshot duration
- coprocsssor handle duration
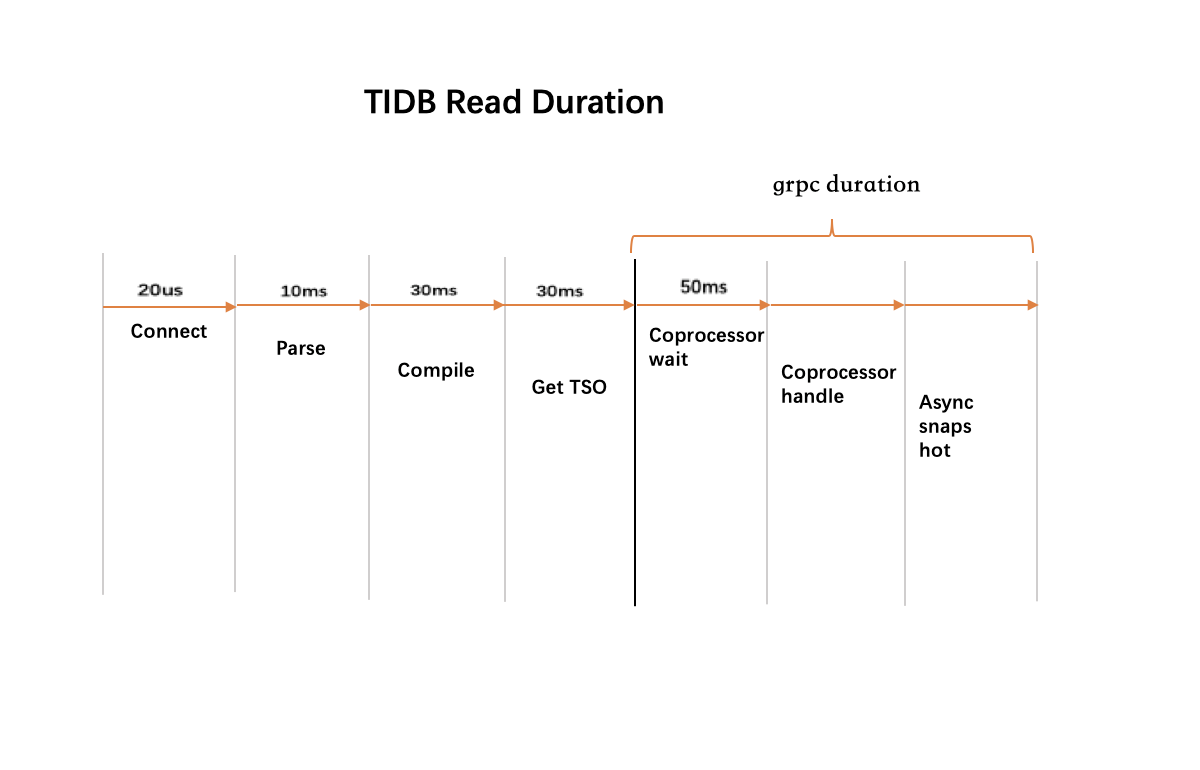
- coprocsssor wait duration 建议 99%的等待延迟应该在50ms以内。如果这个指标过高一般意味着 coprocessor 处于繁忙状态。

tikv 的 thread cpu 上各模块的具体工作内容
- Raft Store CPU:If
所有涉及 raft 相关的请求都需会统计到这,包括 raft group 之间的心跳、raft log 的写入和同步到 follow 节点,还有请研发帮忙补充
- Async apply CPU:
我们的 tikv 上有两个 rocksdb 实例,一个是 raft log 对应的实例,叫做 append log,另外一个是数据对应的实例,叫做 apply log,那这个监控项对应的是哪个?
结论: 我们的 tikv 上有两个 rocksdb 实例,一个是 raft log 对应的实例,叫做 append log,另外一个是数据对应的实例,叫做 apply log 对应的监控为 kvdb。
- Local reader CPU:
结论:2.1 版本中,这个指标表示,单独一个负责读请求线程的如下两个工作:1)判断是否是 leader,请求是否合法;2)拿 snapshot 给后续该读请求用。3.0 以后版本该项会取消。
- Scheduler CPU:
结论:负责写请求的调度工作,在 2.1 中是单线模式,3.0 以后版本该项取消。
- Scheduler worker CPU:
结论:负责事物写请求之前的事务约束校验等工作,比如是否有写写冲突等。
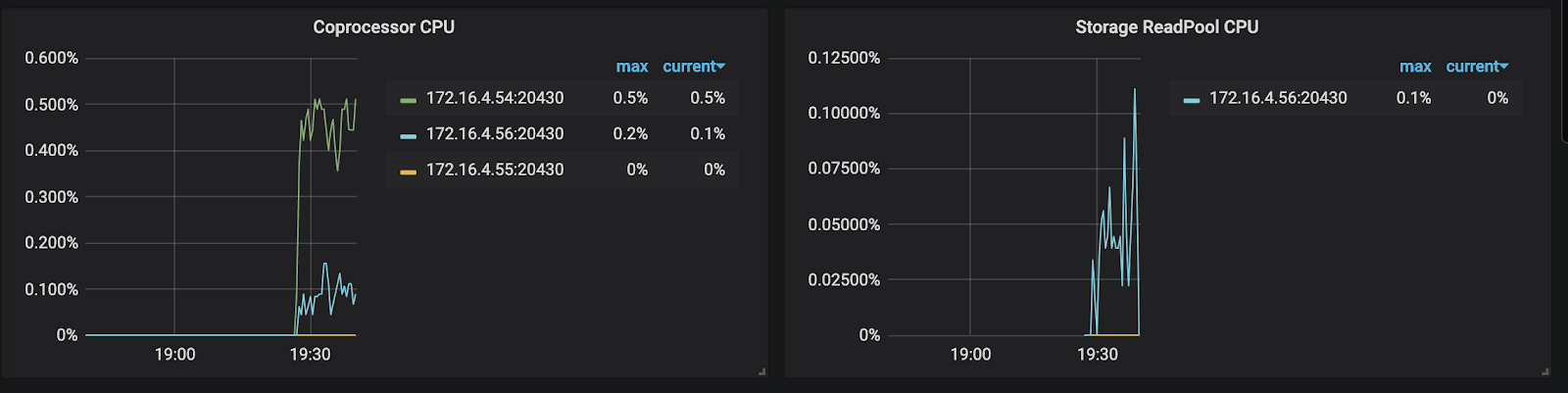
- Storage ReadPool CPU:
负责点查场景下的 key 读取操作: get & batch get & schema 获取
- Corprocessor CPU:
负责非点查场景下的 key 读取操作, 统计数据, checksum.
- Snapshot worker CPU:
涉及到region 迁移、补副本等操作时,需要该模块发起在 leader 节点产生 snapshot。
- Split check CPU:
看了3.0版本的参数,region-split-check-diff: "6MB” ,split-region-check-tick-interval: “10s”
每隔10s 运行 check,发现 region 的大小增长超过6MB ,并且满足region-max-size: “144MB” 或者 region-max-keys: 1440000 这两个条件之一时触发 split 操作,split 之后,新的 region 大小是96MB,max-keys 是960000。

- RocksDB CPU:
结论:负责 kvdb 和 raftdb 的后台数据整理工作( compaction)
- gRPC poll CPU:
grpc 相关的模块,默认值是4,而且目前的现象是很难打满,基本上发现 grpc 到350了就需要考虑调整上限值
3. Coplterator 框架
CopIterator 的任务就是实现 distsql 请求,执行所有涉及到的 Coprocessor 请求,并依次返回结果。
构造 coprocessor task
找到所有 KeyRange 包含的所有的 region 以后,我们需要按照 region 的 range 把 key range list 进行切分,让每个 coprocessor task 里的 key range list 不会超过 region 的范围。构造出了所有 coprocessor task 之后,下一步就是执行这些 task 了。
coplterator执行模式
在 copIterator 创建的时候,我们启动一个后台 worker goroutine 来依次执行所有的 coprocessor task,并把执行结果发送到一个 response channel,这样前台 Next 方法只需要从这个 channel 里 receive 一个 coprocessor response 就可以了。如果这个 task 已经执行完成,Next 方法可以直接获取到结果,立即返回。
当所有 coprocessor task 被 worker 执行完成的时候,worker 把这个 response channel 关闭,Next 方法在 receive channel 的时候发现 channel 已经关闭,就可以返回 nil response,表示所有结果都处理完成了
为了增大并行度,我们可以构造多个 worker 来执行 task,把所有的 task 发送到一个 task channel,多个 worker 从这一个 channel 读取 task,执行完成后,把结果发到 response channel,通过设置 worker 的数量控制并发度。
4. Coplterator 实现
理解上述执行模式之后,我们从源码的角度,分析一遍完整的执行流程。
前台执行流程
前台的执行的第一步是 CopClient 的 Send 方法。先根据 distsql 请求里的 KeyRanges 构造 coprocessor task,用构造好的 task 创建 copIterator,然后调用 copIterator 的 open 方法,启动多个后台 worker goroutine,然后启动一个 sender用来把 task 丢进 task channel,最后 copIterator 做为 kv.Reponse 返回。
前台执行的第二步是多次调用 kv.Response 的 Next 方法,直到获取所有的 response。
copIterator 在 Next 里会根据结果是否有序,选择相应的执行模式,无序的请求会从 全局 channel 里获取结果,有序的请求会在每一个 task 的 response channel 里获取结果。
后台执行流程
从 task channel 获取到一个 task 之后,worker 会执行 handleTask 来发送 RPC 请求,并处理请求的异常,当 region 分裂的时候,我们需要重新构造 新的 task,并重新发送。对于有序的 distsql 请求,分裂后的多个 task 的执行结果需要发送到旧的 task 的 response channel 里,所以一个 task 的 response channel 可能会返回多个 response,发送完成后需要 关闭 task 的 response channel。
3. TiDB 层
1. Root Executor
能推送到 TiKV 上的计算请求目前有 TableScan、IndexScan、Selection、TopN、Limit、PartialAggregation 这样几个,其他更复杂的算子,还是需要在单个 tidb-server 上进行处理。所以整个计算是一个多 tikv-server 并行处理 + 单个 tidb-server 进行汇总的模式
2. selectResult
实现 SelectResult 这个接口,代表了一次查询的所有结果的抽象,计算是以 Region 为单位进行,所以这里全部结果会包含所有涉及到的 Region 的结果。调用 Chunk 方法可以读到一个 Chunk 的数据,通过不断调用 NextChunk 方法,直到 Chunk 的 NumRows 返回 0 就能拿到所有结果。NextChunk 的实现会不断获取每个 Region 返回的 SelectResponse,把结果写入 Chunk。
chunk 的大小可以由参数 tidb_max_chunk_size(session/global) 参数控制一次性取多少行。Executor 根据指定的行数请求执行一次性内存分配。建议值:
OLTP APP = 32
OLAP APP = 1024+
3. 协议层出口
出口比较简单,使用的 writeResultset 方法,按照 MySQL 协议的要求,将结果(包括 Field 列表、每行数据)写回客户端。读者可以参考 MySQL 协议中的 COM_QUERY Response 理解这段代码。