By Jinlong Liu
ps:内容稍微有些老旧, 参考一下大致的流程和勘误
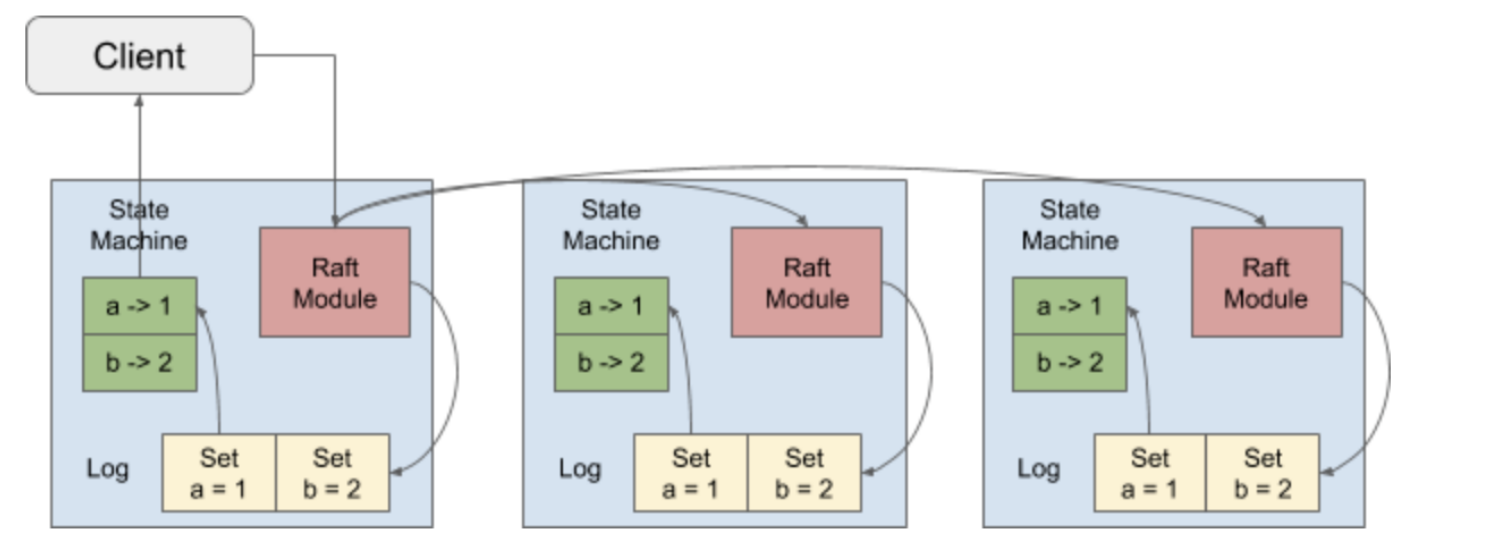
概述
-
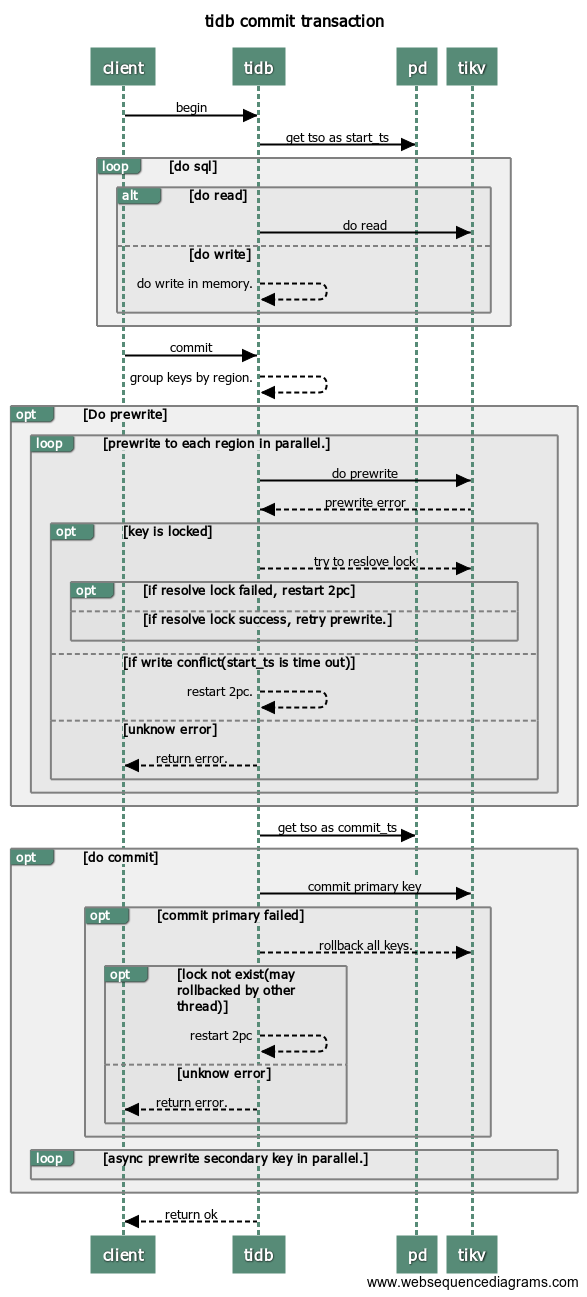
client 向 tidb 发起开启事务 begin
-
tidb 向 pd 获取 tso 作为当前事务的 start_ts
这部分流程可以参考读流程
「
-
tidb 分析该请求进行 Mysql 协议解析和转换;
-
将文本解析成结构化数据,也就是抽象语法树 (AST),拿到 AST 之后,就可以做各种验证(预处理,合法性验证,权限检验)、变换、优化。这两步是 parse 及 compile 的过程,异步执行的还有与 pd 交互,获取 start_ts 信息;
-
tidb 从缓存中获取 information_schema(启动的时候缓存这些信息),若没有,从 tikv 获取 information_schema。
-
tidb 从 information_schema 中获取到当前用户所操作的 table 的元信息。
-
tidb 准备好执行计划并且获取到 tso 后,tidb 根据 keyrange 带上 table 的元信息后组织成 tikv 的 KeyRange。
-
tidb 从 Region Cache 或 PD 获取每个 KeyRange 所在的 regions 信息。
-
tidb 根据 regions 信息对 KeyRange 进行分组。
[TIKV]
-
grpc请求(server.grpc-concurrency).
-
tidb 并发向所有 regions 对应的 tikv 分发 select 请求。
-
tikv 根据 tidb 的请求进行数据的筛选过滤,然后返回给 tidb。(readpool.storage readpool.coprocessor)
[TiDB]
-
tidb 收到所有结果后,整理数据。 」
-
client 向 tidb 执行以下请求:
读操作,从 tikv 读取版本 start_ts 对应具体数据.
写操作,写入 memory 中。(事务提交前,在客户端 buffer 所有 update/delete 操作)
-
client 向 tidb 发起 commit 提交事务请求
-
tidb 开始两阶段提交。
-
tidb 按照 region 对需要写的数据进行分组。
-
tidb 开始 prewrite 操作:向所有涉及改动的 region 并发执行 prewrite 请求。若其中某个prewrite 失败,根据错误类型决定处理方式:
KeyIsLock:尝试 Resolve Lock 后,若成功,则重试当前 region 的 prewrite[步骤7]。否则,重新获取 tso 作为 start_ts 启动 2pc 提交(步骤5)。
WriteConfict 有其它事务在写当前 key, 重新获取 tso 作为 start_ts 启动 2pc 提交(步骤5)。
其它错误,向 client 返回失败。
-
tidb 向 pd 获取 tso 作为当前事务的 commit_ts。
-
tidb 开始 commit:tidb 向 primary 所在 region 发起 commit。 若 commit primary 失败,则先执行 rollback keys,然后根据错误判断是否重试:
LockNotExist 重新获取 tso 作为 start_ts 启动 2pc 提交(步骤5)。
其它错误,向 client 返回失败。
-
tidb 向 tikv 异步并发向剩余 region 发起 commit。
-
tidb 向 client 返回事务提交成功信息。
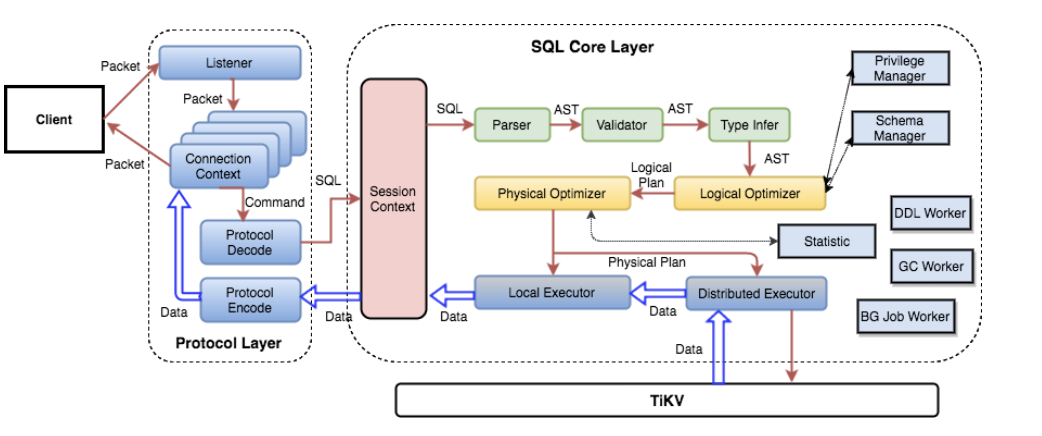
1. TiDB 层
1. 协议层入口
当和客户端的连接建立好之后,TiDB 中会有一个 Goroutine 监听端口,等待从客户端发来的包,并对发来的包做处理。使用 clientConn.Run() 在循环中,不断的读取网络包。然后调用 dispatch() 方法处理收到的请求,然后根据 Command 的类型,调用对应的处理函数。最常用的 Command 是 COM_QUERY,对于大多数 SQL 语句,只要不是用 Prepared 方式,都是 COM_QUERY。 对于 Command Query,从客户端发送来的主要是 SQL 文本,处理函数是 handleQuery()。
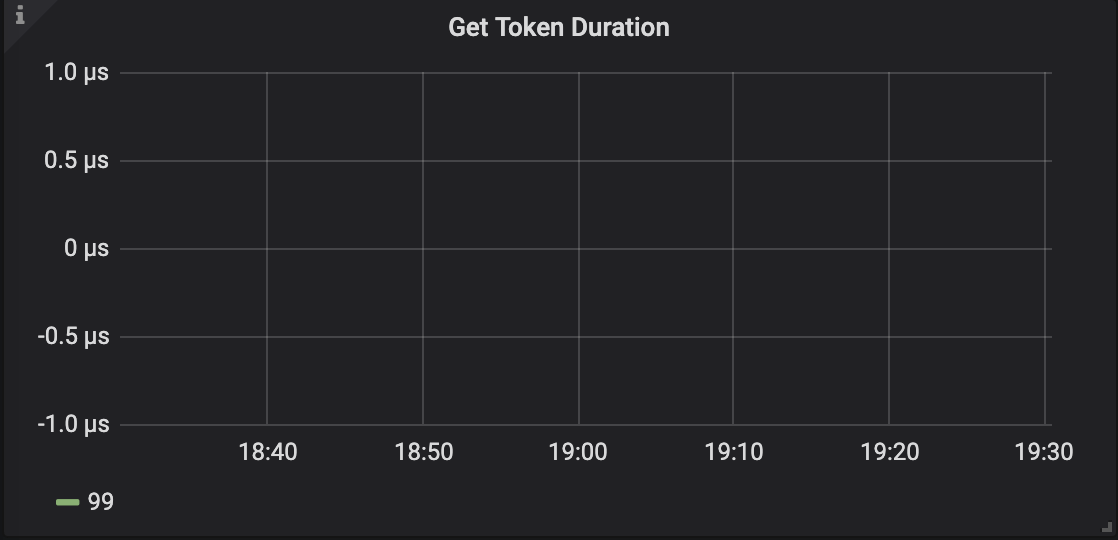
默认情况下,连接数限制为1000,由 token-limit 参数控制。如果这个参数设置过小,新建连接会花费更长的时间,正常情况下,”Get Token Duration” 应该小于 2us。
注: OLTP 场景下,建议连接数应该少于500个,并且需要密切关注不同 tidb-server 之间连接数的均匀分布。
注: OLTP 场景下,建议 99.9%的查询延迟都应该小于500ms。 Heap Memory,当本地 latch 启用的情况下,每个 TIDB server 使用的内存大小应该小于 3G ,如果禁用,则应该小于 1GB。
2. Parser 模块 (Lexer & Yacc)
TiDB使用词法分析器 lex 进行抽象+语法分析器 yacc 生成树形结构。这两个组件共同构成了 Parser 模块,调用 Parser,可以将文本解析成结构化数据,也就是抽象语法树 (AST)。
监控说明:
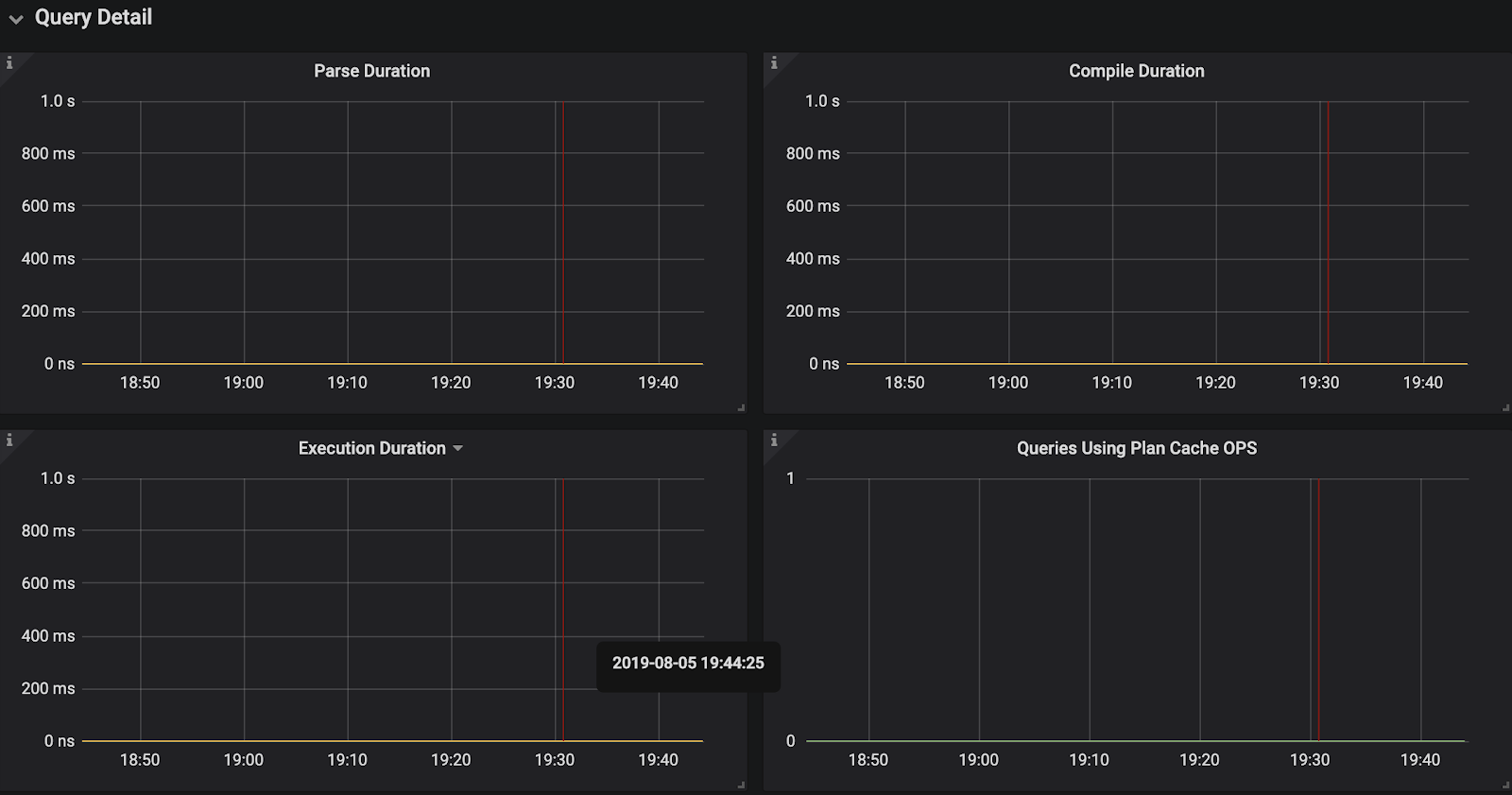
Grafana Metrics 提供了 SQL 解析成 AST 所消耗的时间,正常情况下应小于 10ms。
平均解析时间为:tidb_session_parse_duration_seconds_sum{sql_type=“general”}
/tidb_session_parse_duration_seconds_count{sql_type=“general”}

3. Compile 模块
有了AST 后 TiDB会将其经过 buildSelect() 函数处理,之后 AST 会变成一个 Plan 的树状结构树。
拿到 AST 之后,就可以做各种验证(预处理,合法性验证,权限检验)、变换、优化,这一系列动作的入口在这里 Compile 函数,最重要的三个步骤:
- plan.Preprocess: 做一些合法性检查以及名字绑定;
- plan.Optimize:制定查询计划,并优化,这是最核心的步骤之一。这里有一个特殊的函数 TryFastPlan,如果这里判断规则可以符合 PointGet,会跳过后续的优化,直接走点查
- 构造 executor.ExecStmt 结构:这个 ExecStmt 结构持有查询计划,是后续执行的基础,非常重要,特别是 Exec 方法(后续会介绍)。
逻辑优化,主要依据关系代数的等价交换规则做一些逻辑变换。其由一系列优化规则组成,对于这些规则会按顺序不断应用到传入的 LogicalPlan Tree 中,详细见 logicalOptimize() 函数。 TiDB 的逻辑优化规则,包括列裁剪、最大最小消除、投影消除、谓词下推,子查询去关联化,外连接消除,聚合消除等等。
物理优化(dagPhysicalOptimize 函数),基于逻辑优化结果,会考虑数据的分布,决定如何选择物理算子。选择最优执行路径,这个选择过程取决于统计信息。TiDB 的物理优化规则,主要通过对查询的数据读取、表连接方式、表连接顺序、排序等技术进行优化。

注:对于 insert 语句可以参考 planBuilder.buildInsert() (补全对象信息、处理 lists 中的数据)insert 介绍逻辑 https://pingcap.com/blog-cn/tidb-source-code-reading-4/
监控说明:
Grafana Metrics 提供了 由 AST 解析成查询计划所消耗的时间,正常情况下应小于 30ms。平均执行计划生成时间为:tidb_session_compile_duration_seconds_sum/tidb_session_compile_duration_seconds_count
4. 生成 Executor
在这个过程中,TiDB 会将 plan 转换成 executor,这样执行引擎即可通过 executor 执行优化器定下的查询计划,具体的代码见 ExecStmt.buildExecutor()。
5. 运行 Executor
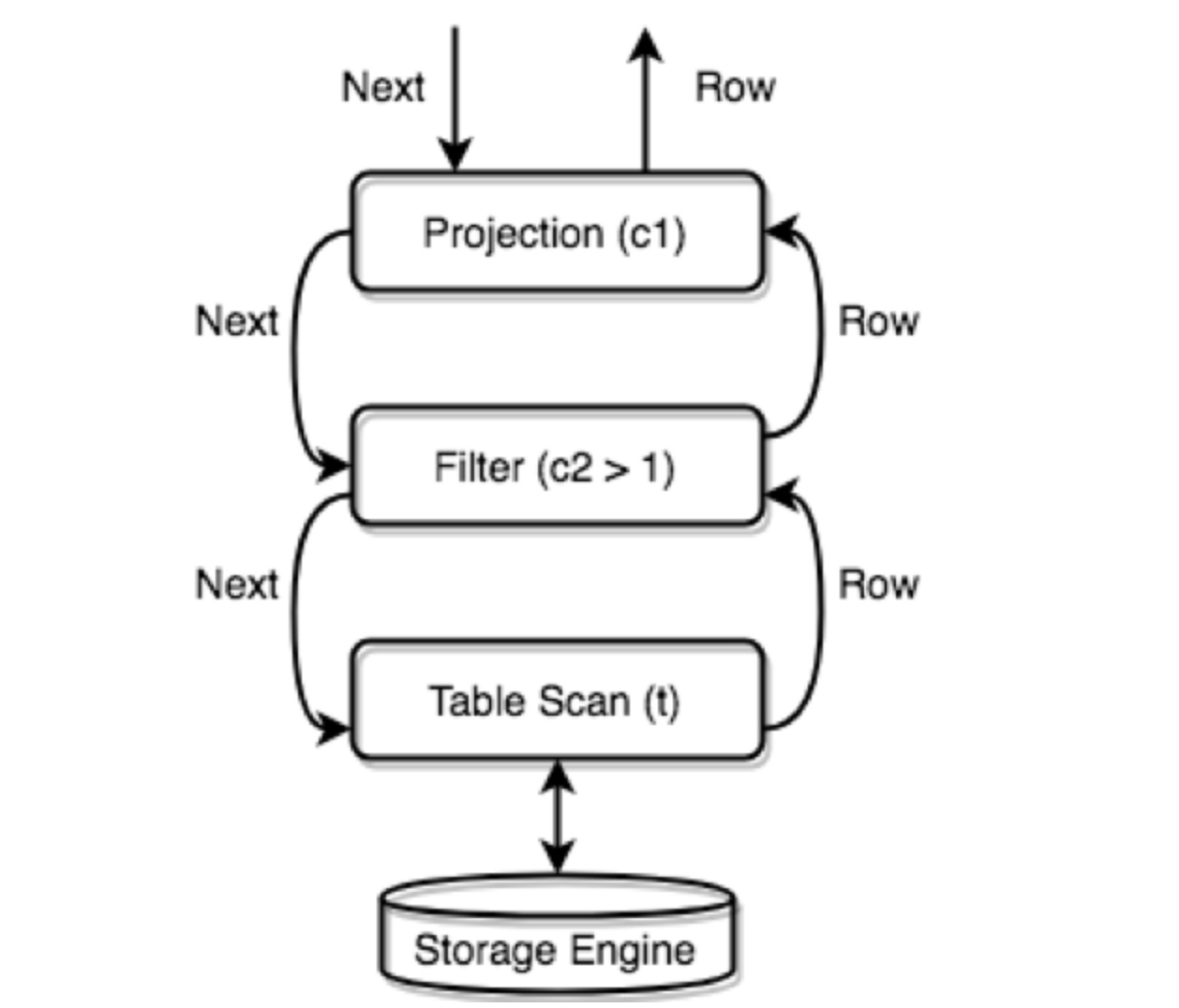
TiDB 会将所有的物理 Executor 构成一个树状结构,每一层通过调用下一层的 Next/NextChunk() 方法获取结果。
例如:SELECT c1 FROM t WHERE c2 > 1;
监控说明:
chunk 的大小可以由参数 tidb_max_chunk_size(session/global) 参数控制一次性取多少行。Executor 根据指定的行数请求执行一次性内存分配。建议值:
OLTP APP = 32
OLAP APP = 1024+
3.0 版本做了一些调整,有两个参数,一个是 init_chunk_size,一个是 max_chun_size,也就是说 3.0 版本可以不用调整。
6. 获取 Key 所在的 Region and TSO
TiDB 通过向 PD 发送请求实现 region 的定位及获取 TSO。PD client 实现了接口 GetRegion 通过调用这个接口,我们就可以定位这个 key 所在的 Region。
为了防止获取一个范围内的多个 Region,重复循环多次调用 GetRegion 这个接口每次读取数据的时候,都需要先去访问 PD,这样会给 PD 带来巨大压力,同时影响请求的性能。Tikv-client 实现了一个 RegionCache 的组件,缓存 Region 信息, 当需要定位 key 所在的 Region 的时候,如果 RegionCache 命中,就不需要访问 PD 。
RegionCache 的内部,有两种数据结构保存 Region 信息,一个是 map,另一个是 b-tree,用 map 可以快速根据 region ID 查找到 Region,用 b-tree 可以根据一个 key 找到包含该 key 的 Region。通过 region cache 提供的 LocateKey 方法,我们可以找到有哪些 region 包含了一个 key range 范围内的数据。如果因为 Region 分裂,Region 迁移导致了 Region 信息变化,请求的 Region 信息就会过期,这时 tikv-server 就会返回 Region 错误。遇到了 Region 错误,后清理 RegionCache(仅清理变化的信息),重新获取最新的 Region 信息,并重新发送请求。
Region Cache 更新机制:
TiDB 先访问 pd 获取 tso,然后访问 tidb-server 本地 region cache,然后按照获得的路由信息,将请求发给 Tikv,如果 Tikv 返回错误说明路由信息过旧,这个时候 tidb-server 会去 pd 重新取 region 的最新路由信息,并更新 region cache。如果,请求发送到 follower 了,Tikv 会返回 not leader 的错误并把谁是 leader 的信息返回给 tidb-server, 然后 tidb-sever 更新 region cache。
TSO 获取机制:
Point Get 也会取 tso, 在 PrepareTxnCtx 时发送 tso 请求到 pd(有计划进行优化)。PrepareTxnCtx 执行阶段很早,在对 SQL 做 parse 之前就执行了。但是 Point Get 虽然去申请了 tso,但是并没有去调用 txnFuture.wait 去读取它。而有一些情况,是直接用 maxTs 构造了一个 Txn 对象,也就是 Point Get 并不会去等待 pd 的返回,但是依然对 pd 造成了一些压力(虽然会 batch)。其他情况,至少会拿一个 tso(start_ts),并且需要注意的是 start_ts 为 0 的情况并不代表没有发送 tso 请求到 pd。
- 单条语句 autoCommit
- 读语句
- 只涉及一个 key 的查询,也就是点查。
所有 TiDB 与 PD 交互的逻辑都是通过一个 PD Client 的对象进行的,这个对象会在服务器启动时创建 Store 的时候创建出来,创建之后会开启一个新线程,专门负责批量从 PD 获取 TSO,这个线程的工作流程大致流程如下:
- TSO 线程监听一个 channel,如果这个 channel 里有 TSO 请求,那么就会开始向 PD 请求 TSO(如果这个 channel 有多个请求,本次请求会进行 batch)
- 将批量请求而来的的 TSO 分配给这些请求
对于这些 TSO 请求,其实就被分为了三个阶段:
- 将一个 TSO 请求放入这个 channel,对应的函数为 GetTSAsync,调用这个函数会得到一个 tsFuture 对象
- TSO 线程从 channel 拿到请求向 PD 发起 RPC 请求,获取 TSO,获取到 TSO 之后分配给相应的请求
- TSO 分配给相应的请求之后,就可以通过持有的 tsFuture 获取 TSO(调用 tsFuture.Wait())
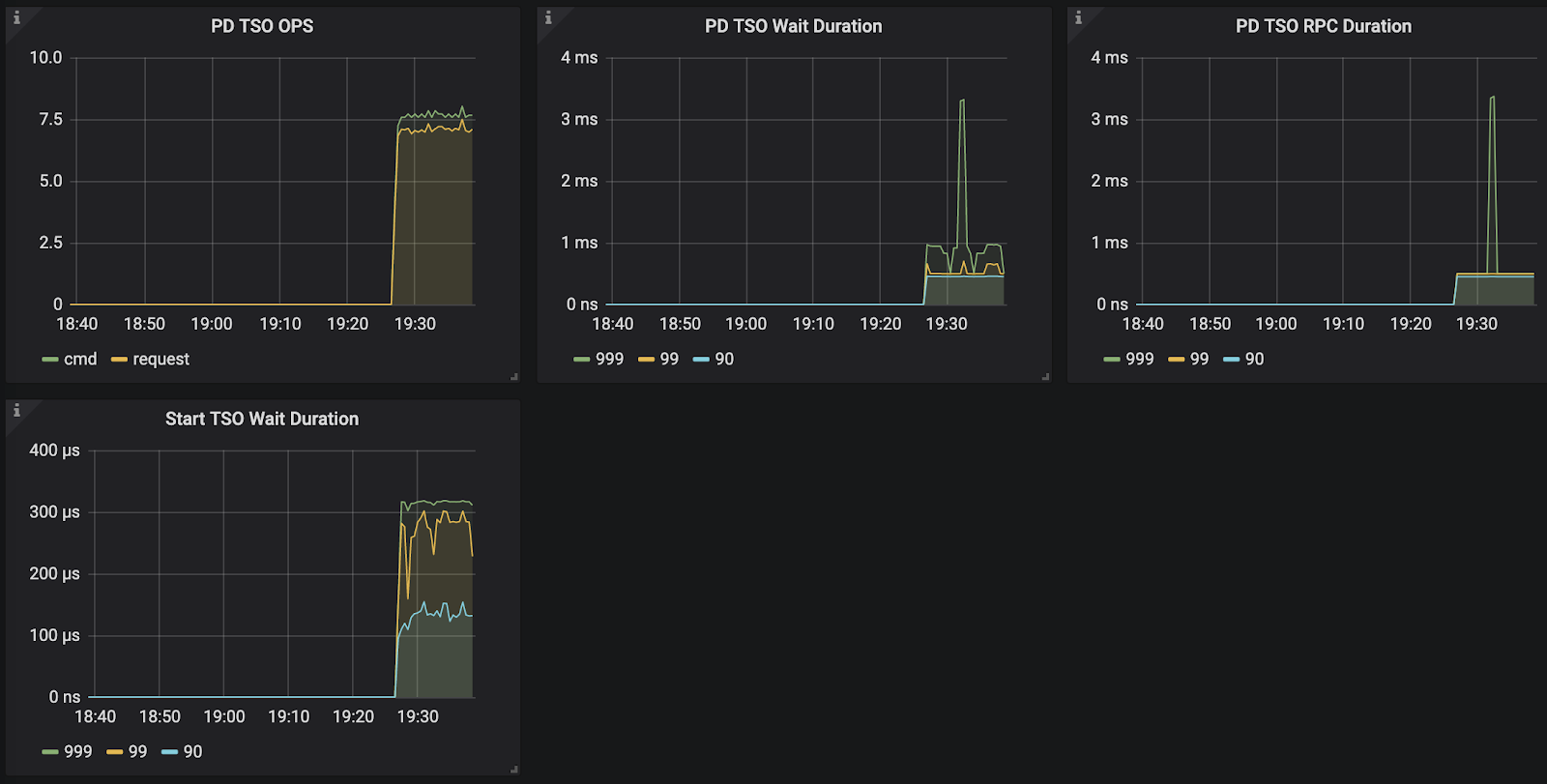
监控说明:
目前系统没有对第一个阶段设置相应的监控信息,这个过程通常很快,除非 channel 满了,否则 GetTSAsync 函数很快返回,而 channel 满表示 RPC 请求延迟可能过高,所以可以通过 RPC 请求的 Duration 来进一步分析。
- PD TSO RPC Duration : 反应向 PD 发起 RPC 请求的耗时,这个过程慢有两种可能:
- TiDB 和 PD 之间的网络延迟高
- PD 负载太高,能不能及时处理 TSO 的 RPC 请求
- TSO Async Duration: 拿到一个 tsFuture 之后到调用 tsFuture.Wait() 中间的时间消耗,拿到 tsFuture 之后,后续还需要进行 SQL Parse 和 Compile 成执行计划,真正执行的时候才会调用 tsFuture.Wait(),所以这部分延迟太多,可能因为:
- 这个 SQL 很复杂,Parse 花费了很长的时间
- Compile 花费了很长时间
- PD TSO Wait Duration: 我们可能拿到一个 tsFuture 之后,很快做完 Parse 和 Compile 的过程,这个时候去调用 tsFuture.Wait(),但是这个时候 PD 的 TSO RPC 还没有返回,我们就需要等,这个时间反应的是这一段的等待时间。
- PD TSO Duration:上面整个过程的时间
所以这一块的正确分析方式是先查看整个 TSO 是否延迟过大,再去查具体是某个阶段延迟过大。
注:
读取只向 PD拿一次 Tso 就够了。写入的话,需要拿两次,因为写流程两阶段提交,需要取两次 tso,包括:start_ts + commit_ts。并且暂时不会支持通过 start_ts 计算出 commit_ts 减少拿的次数。所以在压测场景下,写入场景一般会比读场景的 PD TSO Wait Duration 的指标值高很多。
tikv-client 配置参数:
max-batch-size = 15 批量发送 rpc 封包的最大数量,如果不为 0,将使用 BatchCommands api 发送请求到 TiKV,可以在并发度高的情况降低 rpc 的延迟,推荐不修改该值
grpc-connection-count = 16 跟每个 TiKV 之间建立的最大连接数。
7. 构造 twoPhaseCommitter
当一个事务准备提交的时候,会创建一个 twoPhaseCommiter,用来执行分布式的事务。构造的时候,需要做以下几件事情:
- 从 memBuffer 和 lockedKeys 里收集所有的 key 和 mutation
memBuffer 里的 key 是有序排列的,我们从头遍历 memBuffer 可以顺序的收集到事务里需要修改的 key,value 长度为 0 的 entry 表示 DELETE 操作,value 长度大于 0 表示 PUT 操作,memBuffer 里的第一个 key 做为事务的 primary key。lockKeys 里保存的是不需要修改,但需要加读锁的 key,也会做为 mutation 的 LOCK 操作,写到 TiKV 上。 - 计算事务的大小是否超过限制
在收集 mutation 的时候,会统计整个事务的大小,如果超过了最大事务限制,会返回报错。
太大的事务可能会让 TiKV 集群压力过大,执行失败并导致集群不可用,所以要对事务的大小做出硬性的限制。 - 计算事务的 TTL 时间
如果一个事务的 key 通过 prewrite 加锁后,事务没有执行完,tidb-server 就挂掉了,这时候集群内其他 tidb-server 是无法读取这个 key 的,如果没有 TTL,就会死锁。设置了 TTL 之后,读请求就可以在 TTL 超时之后执行清锁,然后读取到数据。
我们计算一个事务的超时时间需要考虑正常执行一个事务需要花费的时间,如果太短会出现大的事务无法正常执行完的问题,如果太长,会有异常退出导致某个 key 长时间无法访问的问题。所以使用了这样一个算法,TTL 和事务的大小的平方根成正比,并控制在一个最小值和一个最大值之间。
8. execute
在 twoPhaseCommiter 创建好以后,下一步就是执行 execute 函数。在 execute 函数里,需要在 defer 函数里执行 cleanupKeys,在事务没有成功执行的时候,清理掉多余的锁,如果不做这一步操作,残留的锁会让读请求阻塞,直到 TTL 过期才会被清理。
2. TiKV 层
1. gRPC 建立维护和 TiDB-sever 之间的连接
TiDB 和 Tikv-server 之间维护了一个连接池 connArray。TiDB 和 TiKV 之间通过 gRPC 通信,而 gPRC 支持在单 TCP 连接上多路复用,所以多个并发的请求可以在单个连接上执行而不会相互阻塞。 我们知道 当PD选举 或者 region 分裂等情况出现时,Tidb-server 的请求是无法被及时响应(notleader/staleepoch/serverbusy)。为了解决这个问题,Backoffer 实现了 fork 功能, 在发送每一个子请求的时候,需要 fork 出一个 child Backoffer,child Backoffer 负责单个 RPC 请求的重试,它记录了 parent Backoffer 已经等待的时间,保证总的等待时间,不会超过 query 超时时间。
我们一直在说二阶段提交,标准的分布式事务,但是对于 tidb 中二阶段提交的具体流程,以及做了哪些优化,目前 DBA 侧不是特别清晰,希望有相关的文档或培训,能够结合原理和实际流程,讲的通俗易懂一些。 可以先看一下 PU 课程,以及 PPT :
TiKV Transaction API Transaction
乐观锁分享 PPT:https://docs.google.com/presentation/d/12LL5nhwnKJYAGf1ncq7xdjJlxRz5uSTNcCoThBccQ2Y/edit
结论:1.一个优化是只对 commit primary key 是需要等待的,其他的 second keys 都是异步去提交的。2.对于失败以后,对残留锁的清理,也是异步去做的。
结论:读会被写影响的主要原因是在于如果读持有的 start_ts 如果在锁的 start_ts 之后,这时候无法保证这个事务的 commit_ts 是否小于读的 start_ts(想象一下这两者是并发从 pd 读取的 tso), 如果 commit_ts < 读的 start_ts, 那么这次读取,是需要看到此次提交的数据的,所以,读必须等待此次事务。
2. Prewrite 阶段
1. tidb 开始 prewrite 操作:向所有涉及改动的 region 并发执行 prewrite 请求。若其中某个prewrite 失败,根据错误类型决定处理方式:
KeyIsLock:尝试 Resolve Lock 后,若成功,则重试当前 region 的 prewrite。否则,重新获取 tso 作为 start_ts 启动 2pc 提交。
WriteConfict 有其它事务在写当前 key, 重新获取 tso 作为 start_ts 启动 2pc 提交。
其它错误,向 client 返回失败。
首先在所有行的写操作中选出一个作为 primary,其他的为 secondaries。
PrewritePrimary: 对 primaryRow 写入 L 列(上锁),L 列中记录本次事务的开始时间戳。写入 L 列前会检查:
- 是否已经有别的客户端已经上锁 (Locking)。
- 是否在本次事务开始时间之后,检查 W 列,是否有更新 [startTs, +Inf) 的写操作已经提交 (Conflict)。
在这两种种情况下会返回事务冲突。否则,就成功上锁。将行的内容写入 row 中,时间戳设置为 startTs。
将 primaryRow 的锁上好了以后,进行 secondaries 的 prewrite 流程:
- 类似 primaryRow 的上锁流程,只不过锁的内容为事务开始时间及 primaryRow 的 Lock 的信息。
- 检查的事项同 primaryRow 的一致。
当锁成功写入后,写入 row,时间戳设置为 startTs。
以上 Prewrite 流程任何一步发生错误,都会进行回滚:删除 Lock,删除版本为 startTs 的数据。
【scheduler】
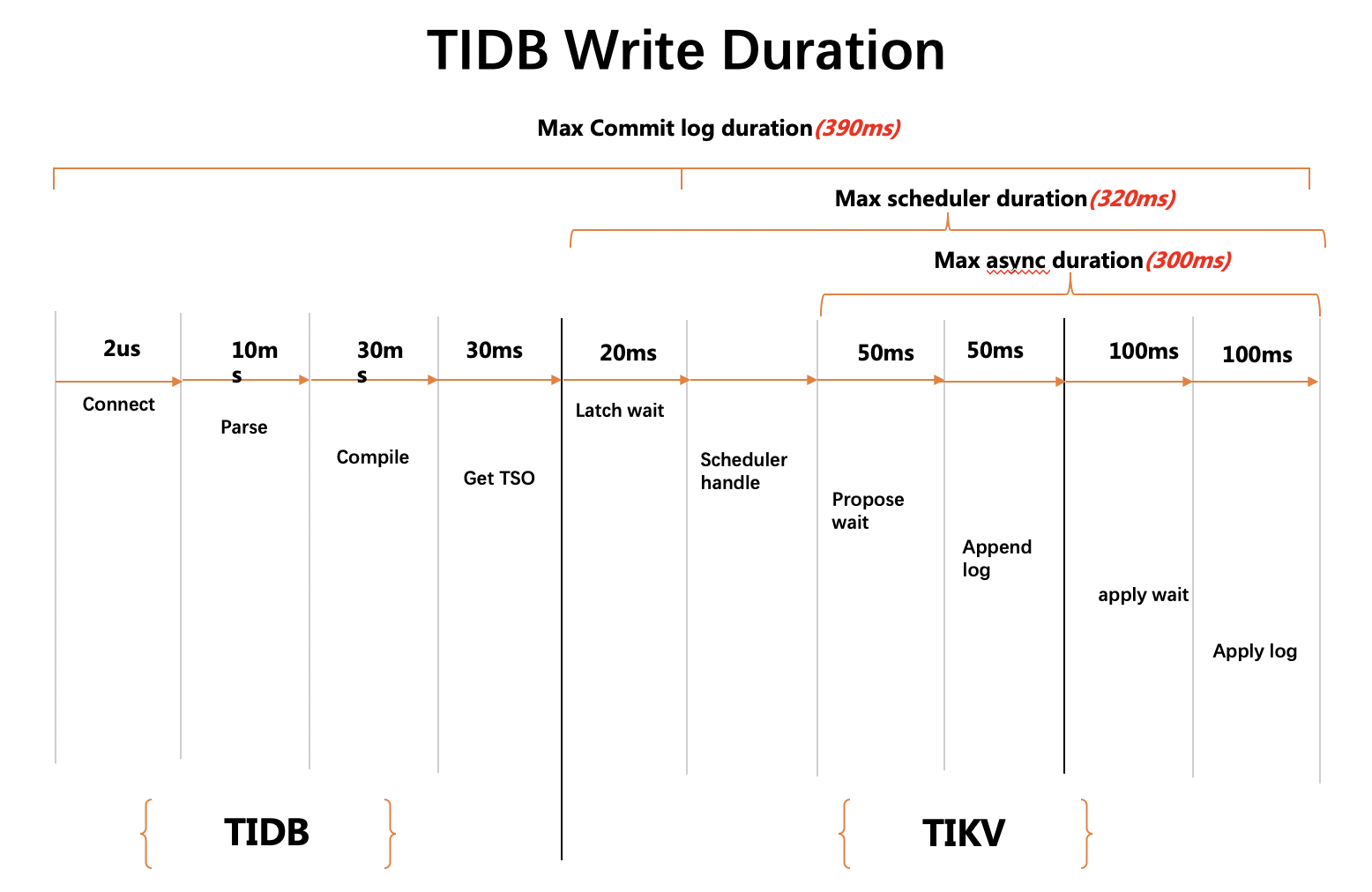
latch wait duration
建议 99% 的 latch 请求延迟应该小于 20ms,如果 latch 请求延迟很长那么代表争用严重,可以通过调整 scheduler-concurrency 参数增加 latch 数量。
scheduler 线程池 cpu 使用率应该小于 scheduler-worker-pool-size*90%
[storage]
scheduler-concurrency = 2048000
scheduler-worker-pool-size = 4
3. commit 阶段
-
tidb 向 pd 获取 tso 作为当前事务的 commit_ts。
-
tidb 开始 commit:tidb 向 primary 所在 region 发起 commit。 若 commit primary 失败,则先执行 rollback keys,然后根据错误判断是否重试:
LockNotExist 重新获取 tso 作为 start_ts 启动 2pc 提交(步骤5)。
其它错误,向 client 返回失败。
-
tidb 向 tikv 异步并发向剩余 region 发起 commit。
-
tidb 向 client 返回事务提交成功信息。
当 Prewrite 完成以后,进入 Commit 阶段,会从 PD 获取一个 commitTS 用来执行 commit 操作。取到了 commitTS 之后,还需要做以下验证:
- commitTS 比 startTS 大
- schema 没有过期
- 事务的执行时间没有过长
- 如果没有通过检查,事务会失败报错。
通过检查之后,执行最后一步 commitKeys。
- commit primary:写入 W 列新数据,时间戳为 commitTs,内容为 startTs,表明数据的最新版本是 startTs 对应的数据。
- 删除L列。
如果 primary row 提交失败的话,全事务回滚,回滚逻辑同 prewrite。如果 commit primary 成功,则可以异步的 commit secondaries, 流程和 commit primary 一致, 失败了也无所谓。
当 commitKeys 请求遇到了网络超时,那么这个事务是否已经提交是不确定的,这时候不能执行 cleanupKeys 操作,否则就破坏了事务的一致性。我们对这种情况返回一个特殊的 undetermined error,让上层来处理。上层会在遇到这种 error 的时候,把连接断开,而不是返回给用户一个执行失败的错误。prewriteKeys, commitKeys 和 cleanupKeys 有很多相同的逻辑,需要把 keys 根据 region 分成 batch,然后对每个 batch 执行一次 RPC。当 RPC 返回 region 过期的错误时,我们需要把这个 region 上的 keys 重新分成 batch,发送 RPC 请求。
这部分逻辑我们把它抽出来,放在 doActionOnKeys 和 doActionOnBatches 里,并实现 prewriteSinlgeBatch,commitSingleBatch,cleanupSingleBatch 函数,用来执行单个 batch 的 RPC 请求。
虽然大部分逻辑是相同的,但是不同的请求在执行顺序上有一些不同,在 doActionOnKeys 里需要特殊的判断和处理。
- prewrite 分成的多个 batch 需要同步并行的执行。
- commit 分成的多个 batch 需要先执行第一个 batch,成功后再异步并行执行其他的 batch。
- cleanup 分成的多个 batch 需要异步并行执行。
doActionOnBatches 会开启多个 goroutines 并行的执行多个 batch,如果遇到了 error,会把其他正在执行的 context cancel 掉,然后返回第一个遇到的 error。
执行 prewriteSingleBatch 的时候,有可能会遇到 region 分裂错误,这时候 batch 里的 key 就不再是一个 region 上的 key 了,我们会在这里递归的调用 prewriteKeys,重新走一遍拆分 batch 然后执行 doActionOnBatch 和 prewriteSingleBatch 的流程。这部分逻辑在 commitSingleBatch 和 cleanupSingleBatch 里也都有。
监控说明:
[raftstore]
propose wait duration
建议 propose wait duration 的延迟应该小于 50ms。 如果延迟较高,意味着 raftstore 繁忙。这可能是由于 append raft log 比较慢或者 raftsotre 的 cpu 使用率过高。raftstore cpu 的使用率应该小于参数 store-pool-size*85%。
store-pool-size = 2
append log duration/write db duration+。。。
建议 99% 的 append log duration 应该小于 50ms。
[apply]
apply wait duration
建议 99% 的 apply wait duration 应该小于 100ms 。如果 apply wait duration 延迟显示非常高,那可能意味着 apply pool 繁忙或者 写入 db 的延迟较高。 apply pool 的 cpu 使用率应该小于 apply-pool-size*90%
apply-pool-size = 2
apply log duration/write db duraiotn+。。。
建议 99% 的 apply log duration 延迟应该小于 100ms。
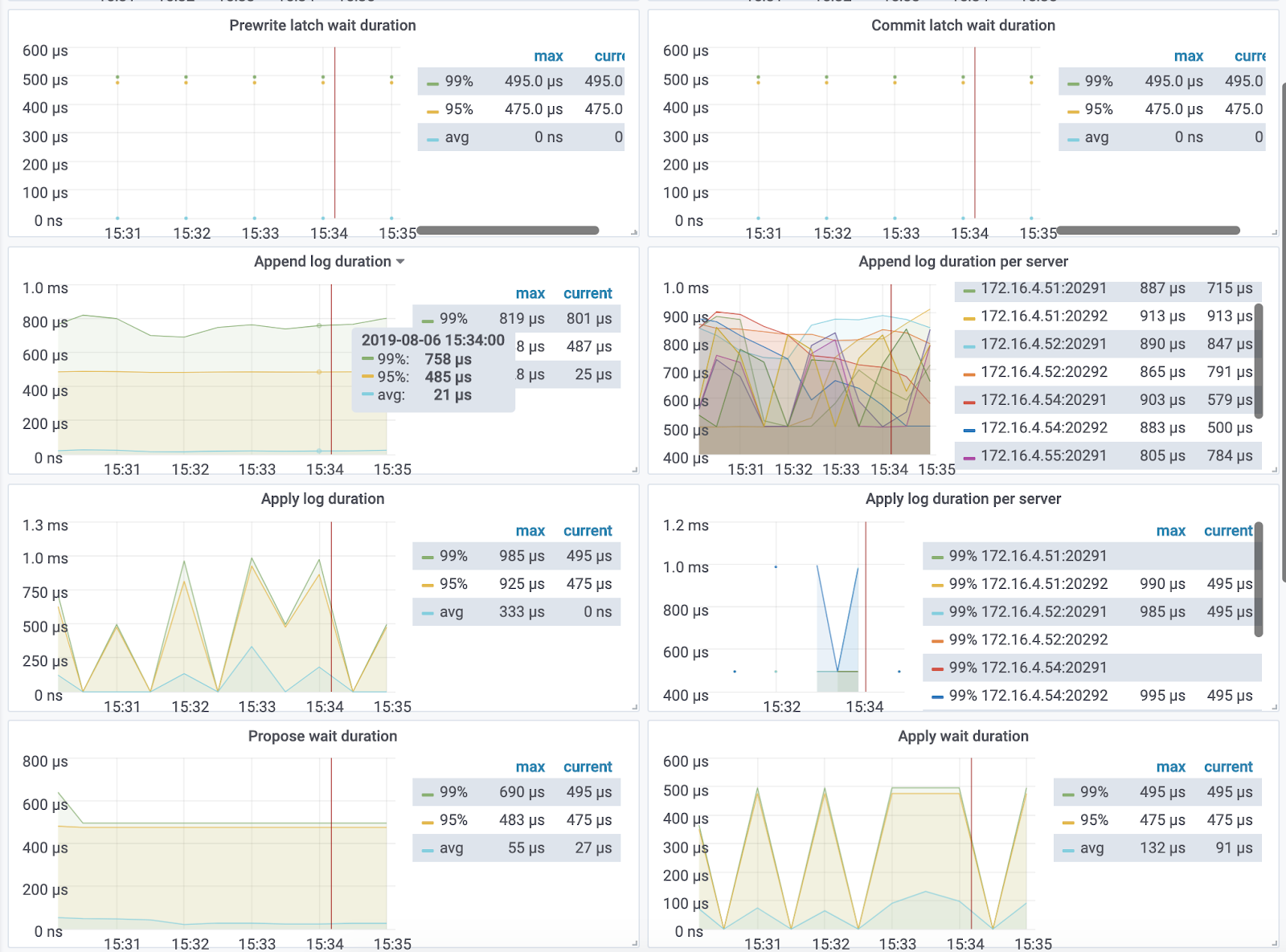
async-write duration 表示 raft write duration,它包括:
-
propose wait duration
-
append log duration
-
commit log duration
-
apply wait duration
-
apply log duration
建议 99% 的 async-write duration 应该小于 200ms
schduler duration 包括
-
latch wait duration,
-
scheduler handle duration,
-
async-write duration
以上为写入过程
Thread cpu 指标说明
Raft Store CPU:
所有涉及 raft 相关的请求都需会统计到这,包括 raft group 之间的心跳、raft log 的写入和同步到 follow 节点,还有请研发帮忙补充
Async apply CPU:
我们的 tikv 上有两个 rocksdb 实例,一个是 raft log 对应的实例,叫做 append log,另外一个是数据对应的实例,叫做 apply log,那这个监控项对应的是哪个?
结论: 我们的 tikv 上有两个 rocksdb 实例,一个是 raft log 对应的实例,叫做 append log,另外一个是数据对应的实例,叫做 apply log 对应的监控为 kvdb。
Local reader CPU:
2.1 版本中,这个指标表示,单独一个负责读请求线程的如下两个工作:1)判断是否是 leader,请求是否合法;2)拿 snapshot 给后续该读请求用。3.0 以后版本该项会取消。
Scheduler CPU:
负责写请求的调度工作,在 2.1 中是单线模式,3.0 以后版本该项取消。
Scheduler worker CPU:
负责事物写请求之前的事务约束校验等工作,比如是否有写写冲突等。
Storage ReadPool CPU:
负责点查场景下的 key 读取操作: get & batch get & schema 获取
Corprocessor CPU:
负责非点查场景下的 key 读取操作, 统计数据, checksum.
Snapshot worker CPU:
涉及到region 迁移、补副本等操作时,需要该模块发起在 leader 节点产生 snapshot。
Split check CPU:
3.0版本的参数,region-split-check-diff: "6MB” ,split-region-check-tick-interval: “10s”,意思是每隔10s 运行 check,发现 region 的大小增长超过6MB ,并且满足region-max-size: “144MB” 或者 region-max-keys: 1440000 这两个条件之一时触发 split 操作,split 之后,新的 region 大小是96MB,max-keys 是960000。

RocksDB CPU:
负责 kvdb 和 raftdb 的后台数据整理工作( compaction)
gRPC poll CPU:
grpc 相关的模块,默认值是4,而且目前的现象是很难打满,基本上发现 grpc 到350了就需要考虑调整上限值
GC worker CPU:
gc 相关的模块,关注度不高。
4. column family 结构
Percolator 提供三个 column family (CF),Lock,Data 和 Write,当写入一个 key-value 的时候,会将这个 key 的 lock 放到 Lock CF 里面,会将实际的 value 放到 Data CF 里面,如果这次写入 commit 成功,则会将对应的 commit 信息放到入 Write CF 里面。
Key 在 Data CF 和 Write CF 里面存放的时候,会把对应的时间戳给加到 Key 的后面。在 Data CF 里面,添加的是 startTS,而在 Write CF 里面,则是 commitTS。
对于 value 比较小的情况,TiKV 会直接将 value 存放到 Write CF 里面,这样 Read 的时候只要走 Write CF 就行。