背景
随着 TiDB 的深入使用,在日常运维当中经常会遇到诸如这样的问题:
为什么我的 TiDB 集群 QPS Duration 升高了?
为什么我的 TiDB 集群,之前很快的语句今天变得执行非常慢了?
为什么我的 TiDB 集群同时出现了大量的 慢 SQL?
诸如此类各种与读请求慢相关的问题。
那么引发这些现象背后的原因是什么?我们要怎么通过 TIDB 的各种监控项与日志排查定位问题?知道了具体问题原因又有什么办法来解这些问题呢?
希望通过这篇文档,能够帮助到您自助的解决这类问题,让 TiDB Cluster 运维起来更加容易。
问题排查思路
TiDB 是一个比较复杂的系统,当出现读请求慢的时候 。有一些问题比较典型,还有一些问题并不常见。通过下面的典型问题排查,往往能解决大部分常见问题。让集群快速恢复到健康状态。还有一部分比较复杂的非典型问题,就需要我们按照读流程一步一步的对集群进行检查。从而找到问题的根源,再考虑如何解决问题
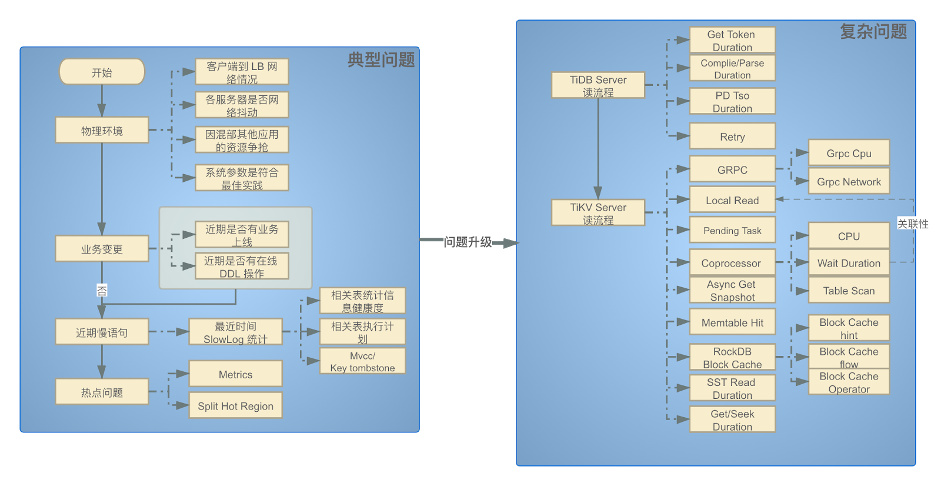
典型问题
通过以下列出的排查路径,来快速 Link 到问题与解决方案
| 分类 | 问题 |
|---|---|
| 物理环境排查 | 客户端到 LB\TiDB 网络情况 |
| 物理环境排查 | 服务器是否有网络异常 |
| 物理环境排查 | 系统配置是否符合最佳实践 |
| 物理环境排查 | 硬件资源不足 |
| 业务发生变更 | 业务并发增加\业务逻辑变化 |
| 业务发生变更 | 业务表结构变更 |
| 慢语句 | 获取慢语句 |
| 慢语句 | 统计信息 |
| 慢语句 | 执行计划 |
| 慢语句 | 其他问题 |
| 热点问题 | 判定读热点依据 |
| 热点问题 | 定位具体热点表或索引 |
| 热点问题 | 解决办法 |
复杂问题排查
TiDB Server 读流程简述
我们将讲述一条 SQL 经过哪些步骤最终构建一个合适的请求发送到 TiKV,这里主要围绕 TiDB server 读流程进行介绍。为了屏蔽细节对于读者的干扰,在不影响正确性的情况下对整个主流程进行简化为如下步骤:
-
从客户端的 Socket 读取一条 SQL
-
获取一个 Token
-
从 PD 获取 TSO (异步获取,此处拿到一个 tsFuture,后续的流程中可以通过 tsFuture 结构拿到真正的 TSO)
-
使用 Parser 将 SQL parse 为 AST
-
将 AST compile 为执行计划(此过程包含很多细节,比如 Validator / LogicalPlanOptimizer / PhysicalPlanOptimizer / Executor builder 等,由于都反映在 Compile duration 的监控之中,此处合为一个步骤)
-
执行上一步得到的执行计划
- Executor.Open(): 最底层的 Executor 会根据这条 SQL 处理的 Key 范围构建出多个要下发到 TiKV 的请求,并通过 distsql 的 API 将这些请求分发到 TiKV
- Executor.Next():最底层的 Executor 会将 distsql 返回的数据返回给上层 Executor
简单说下处理框架:建立链接,TiDB 在收到客户端的查询请求后,进行 MySQL 协议解析和转换,SQL 语法解析,查询计划的制定和优化,查询计划执行等过程。然后切分成一个个以 Range 为单位的子任务, 并行下发到所在的 TIKV 上。经过 TiKV 的处理后返回计算结果,最后将结果返回给客户端。
由于这一部分涉及的监控非常多且复杂,本小节先从概览到细节对监控进行梳理:
- QPS:每秒的查询数量
- Duration:SQL 执行的耗时统计
- Get Token Duration:建立连接后获取 Token 耗时
- Parse Duration:SQL 语句解析耗时统计
- Compile Duration:将 SQL AST 编译成执行计划耗时统计
- Execution Duration:SQL 语句执行耗时统计
以上几个监控可以反映一个查询的时间消耗主要是在哪个大模块,比如:
- Parse Duration / Compile Duration 是纯 CPU 操作,如果 CPU 负载不高,但是耗时比较长,大部分情况是 insert … values 太多,Compile 高更可能的情况是带了非关联子查询。
- Get Token Duration 耗时 比较高说明目前已经在执行的 SQL 达到了 TokenLimiter 的上限,具体情况可能很复杂,比如可能是简单的数量达到了上限,或则内部出现了卡死导致 Token 没有释放。
- Execution Duration 包含了 Executor 执行过程中的总耗时,内部涉及的组件比较多,后面将专门对这一部分进行解释。
- TSO 获取比较慢,相关的监控有:
- TSO RPC Duration:pd client 从发送请求到请求返回的耗时,等于网络 roundtrip 耗时 + PD 服务器处理耗时 + Go Runtime 调度耗时(在 CPU 负载较高时候会有所体现)
- TSO Async Wait:从获取 ts future,到开始 wait ts future 的耗时。反映了 TiDB 内部处理的耗时情况,一般是 parse、compile 以及 auto_increment 的 rebase。向 pd client 发送请求之后,调用者不会卡住,而是得到一个 ts future,只有 wait ts future 的时候,如果 ts future 没有准备好,才会卡住调用者
- TSO Wait Duration:调用 wait ts future 之后等待 future 返回的耗时
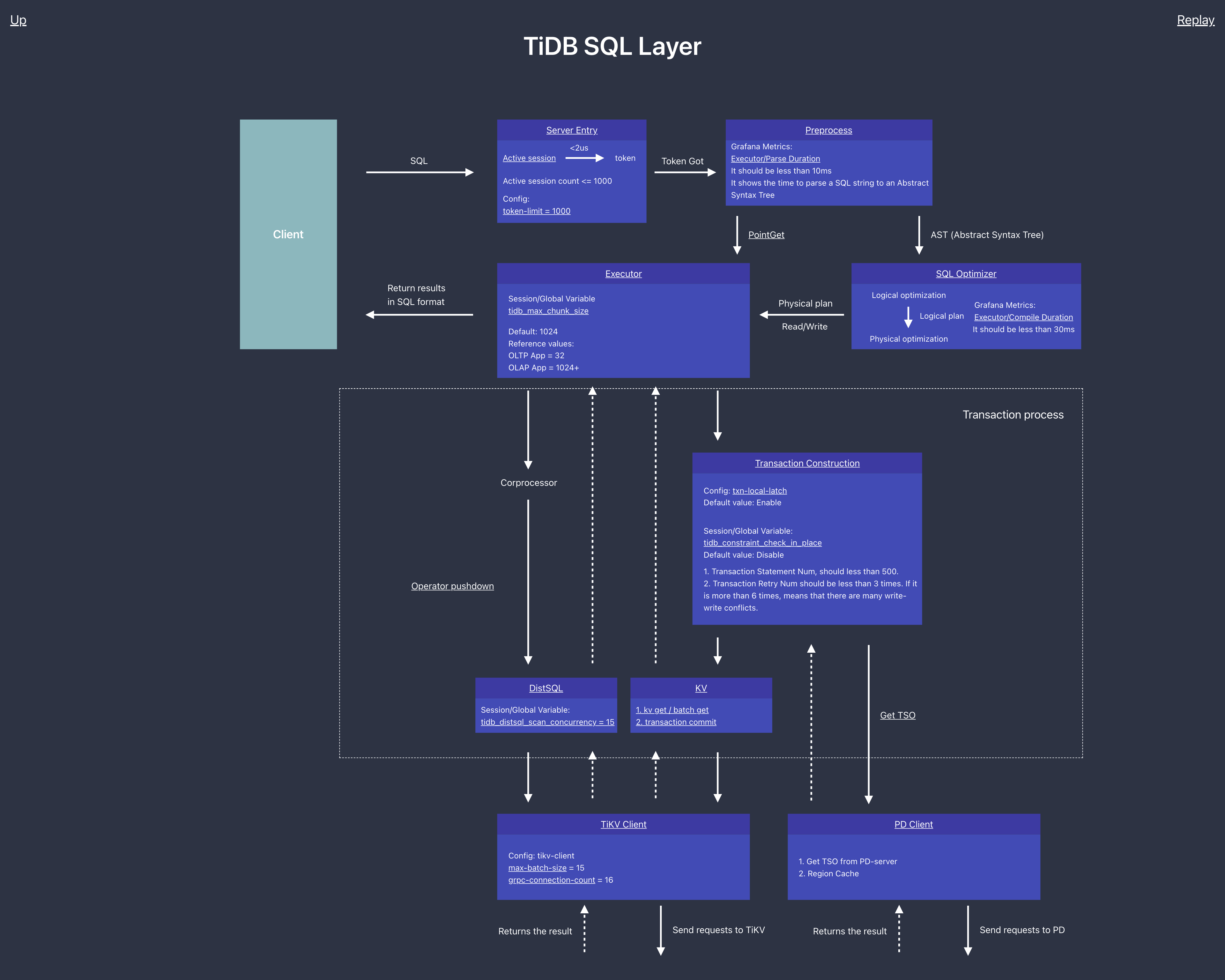
接下来我们就按照对应模块,一步一步的去排查 TiDB Server 层面的读性能问题
| 分类 | 明细 |
|---|---|
| TiDB Cluster 读流程 | TiDB Server 读流程 – 协议层 |
| TiDB Cluster 读流程 | TiDB Server 读流程 – Parser 模块 |
| TiDB Cluster 读流程 | TiDB Server 读流程 – Compile 模块 |
| TiDB Cluster 读流程 | TiDB Server 读流程 – Executor 模块 |
| TiDB Cluster 读流程 | TiDB Server 读流程 – Executor 模块 – Get TSO |
| TiDB Cluster 读流程 | TiDB Server 读流程 – Executor 模块 – DistSQL API |
| TiDB Cluster 读流程 | TiDB Server 读流程 – 其他问题 |
TiKV Server 读流程简述
如果在 TiDB Server 层面没有发现问题,那么就需要我们从 TiKV Server 层面继续排查
在 性能地图 --TiKV Server 部分我们可以看到 整个读流程的过程
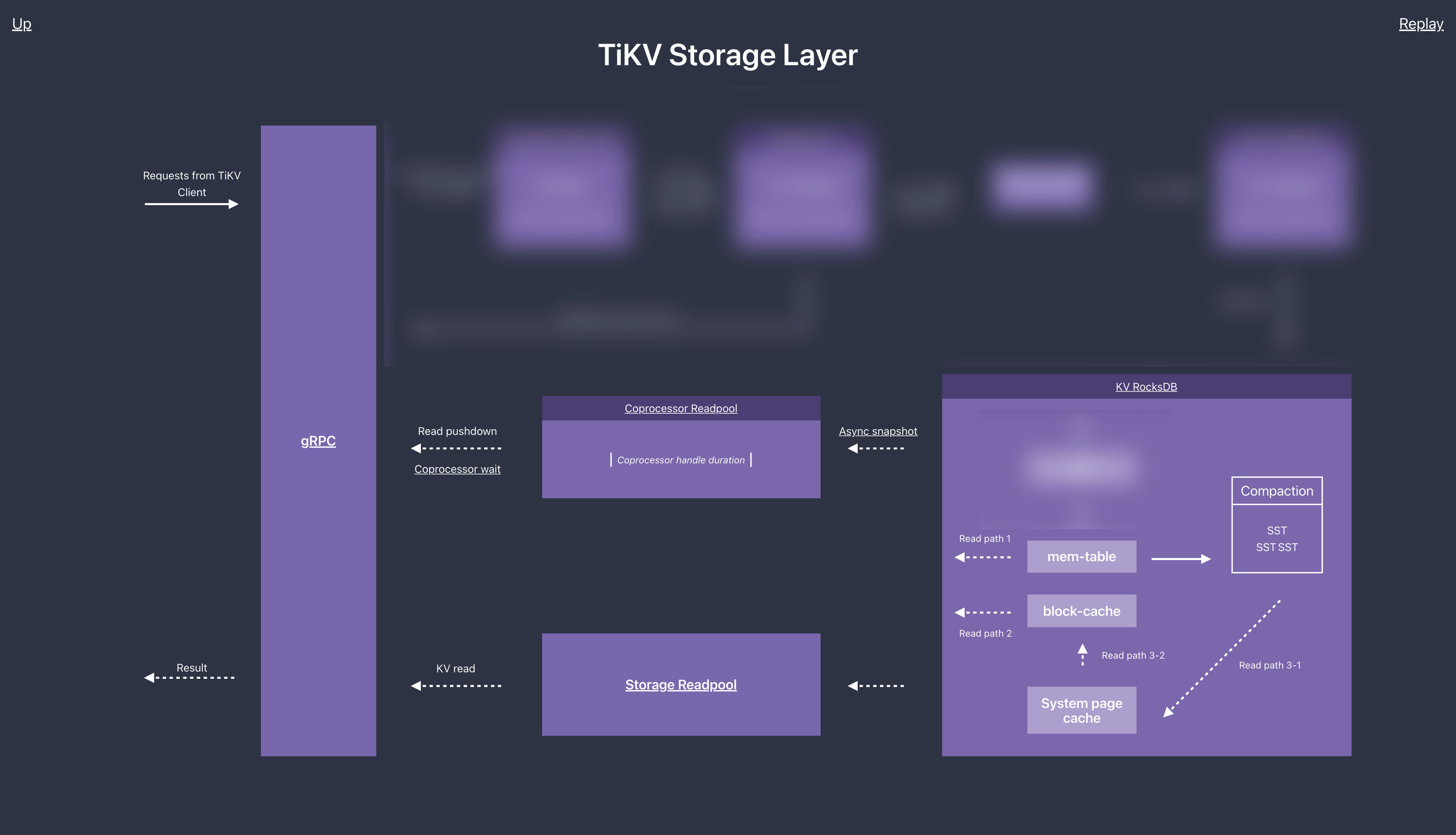
为了便于理解 我们将它再进一步细化。 如图:
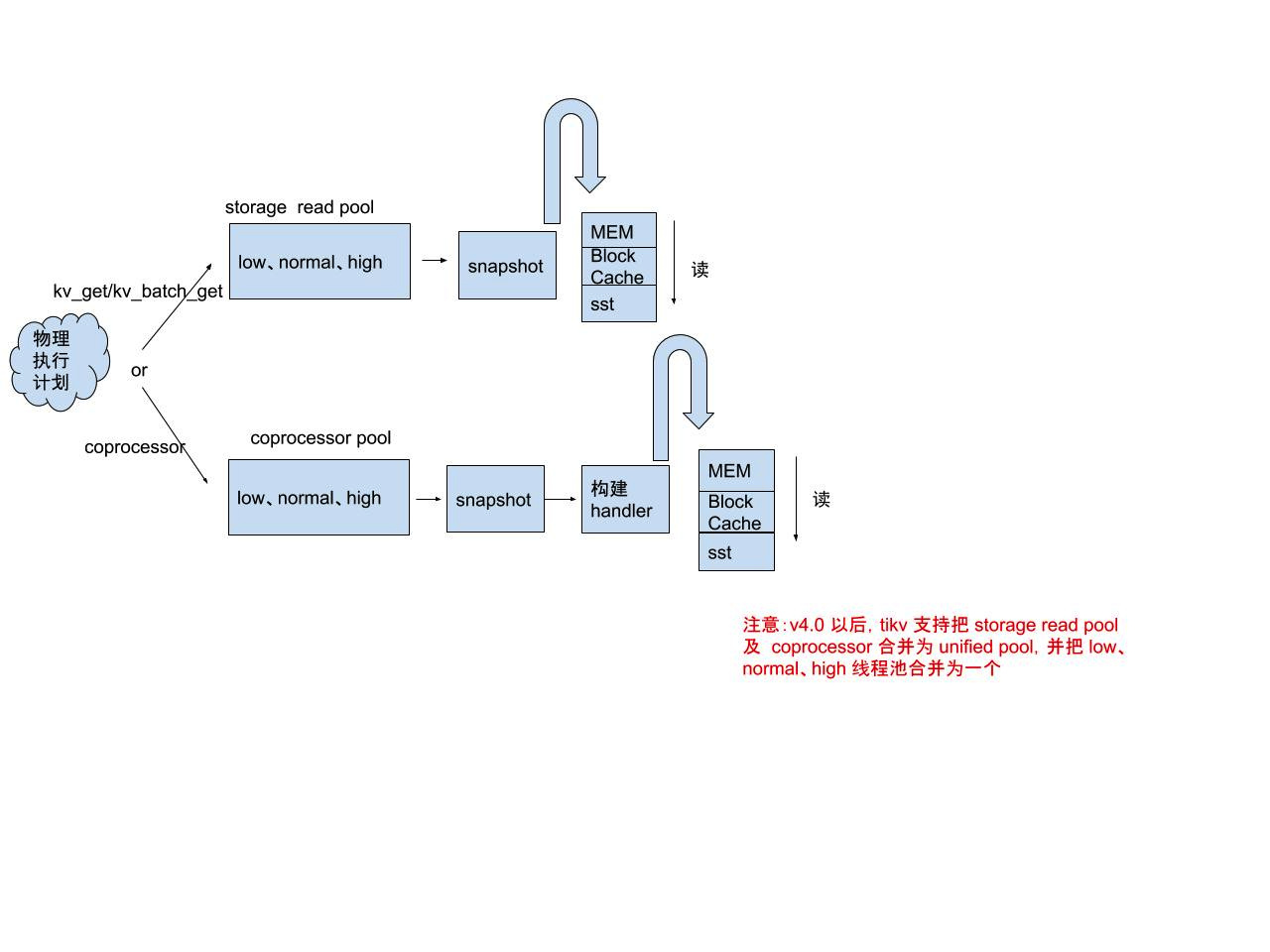
让我们再一次具体看看查询语句在 TiDB Cluster 中是如何处理的:
- TiDB 收到查询语句,对语句进行分析,计算出物理执行计划,组织成发送给 TiKV 的 Coprocessor/kv_get/kv_batch_get 请求。
- TiDB 根据上面的请求的类型,并根据数据的分布,将请求分发到所有相关 TiKV 上对应的线程池中。
- TiKV 在收到请求后,先构建出一个 snapshot ,然后再采用不同的请求算子对数据进行搜索、过滤、聚合,然后返回给 TiDB
- TiDB 在收到所有数据的返回结果后,进行二次聚合,并将最终结果计算出来,返回给客户端。
PS.关于 Coprocessor/kv_get/kv_batch_get ,下面会做一些简单解释:
- TiKV 读取数据并计算的模块,我们定义为 Coprocessor,该概念灵感来自于 HBase, 目前在 TiDB 中的实现类似于 HBase 中的 Coprocessor 的 Endpoint 部分,也可类比 MySQL 存储过程。
- kv_get/kv_batch_get 我们可以简单的理解为处理执行计划中显示为 Point_Get 的请求,即根据主键进行的点查或批量查询
再一次、再一次、再一次,确认服务器的负载情况
在开始细分析,TIKV 哪个环节导致读请求变慢之前,建议首先查看当前集群服务器的负载情况,可以在 Overview 监控面板中,可以看到当前各节点服务器的 Load、CPU 使用情况、磁盘 IO 使用情况、以及网卡流量使用情况,如果上面各指标的使用已经比较繁忙,甚至达到饱和,建议先着重查看导致上述问题的原因,比如:
- 出现较多慢 SQL
- 其他外部程序占用
- 业务本身繁忙(考虑扩容)
- 以及其他典型问题可能导致的问题
接下来我们就按照对应模块,一步一步的去排查 TiKV Server 层面的读性能问题
TiKV Server 读流程分析
| 分类 | 明细 |
|---|---|
| TiDB Cluster 读流程 | TiKV Server 读流程 – gRPC 模块 |
| TiDB Cluster 读流程 | TiKV Server 读流程 – Snapshot 构建 |
| TiDB Cluster 读流程 | TiKV Server 读流程 – RockDB-kv 模块 |
| TiDB Cluster 读流程 | TiKV Server 读流程 – storage read pool 模块 |
| TiDB Cluster 读流程 | TiKV Server 读流程 – coprocessor pool 模块 |
| TiDB Cluster 读流程 | TiKV Server 读流程 – 其他问题 |