4.1.获取 Key 所在的 Region 和 TSO
TiDB 通过向 PD 发送请求实现 region 的定位以及获取 TSO。
TiDB 先访问 PD 获取 TSO,然后访问 tidb-server 本地 Region Cache,按照获得的路由信息,将请求发送给 TiKV。
Region Cache
- TiDB 先访问 pd 获取 tso,然后访问 tidb-server 本地 Region Cache,然后按照获得的路由信息,将请求发给 TiKV,如果 TiKV 返回错误说明路由信息过旧,这个时候 tidb-server 会去 pd 重新取 region 的最新路由信息,并更新 region cache。如果,请求发送到 follower 了,TiKV 会返回 not leader 的错误并把谁是 leader 的信息返回给 tidb-server, 然后 tidb-sever 更新 Region Cache。
获取 TSO
- 所有 TiDB 与 PD 交互的逻辑都是通过一个 PD Client 的对象进行的,这个对象会在服务器启动时创建 Store 的时候创建出来,创建之后会开启一个新线程,专门负责批量从 PD 获取 TSO。对于这些 TSO 请求,分为三个阶段:
- 将一个 TSO 请求放入 channel,对应的函数为 GetTSAsync,调用这个函数会得到一个 tsFuture 对象
- TSO 线程从 channel 拿到请求向 PD 发起 RPC 请求,获取 TSO,获取到 TSO 之后分配给相应的请求
- TSO 分配给相应的请求之后,就可以通过持有的 tsFuture 获取 TSO(调用 tsFuture.Wait())
监控说明:
-
目前系统没有对第一个阶段设置相应的监控信息,这个过程通常很快,除非 channel 满了,否则 GetTSAsync 函数很快返回,而 channel 满表示 RPC 请求延迟可能过高,所以可以通过 RPC 请求的 Duration 来进一步分析。
-
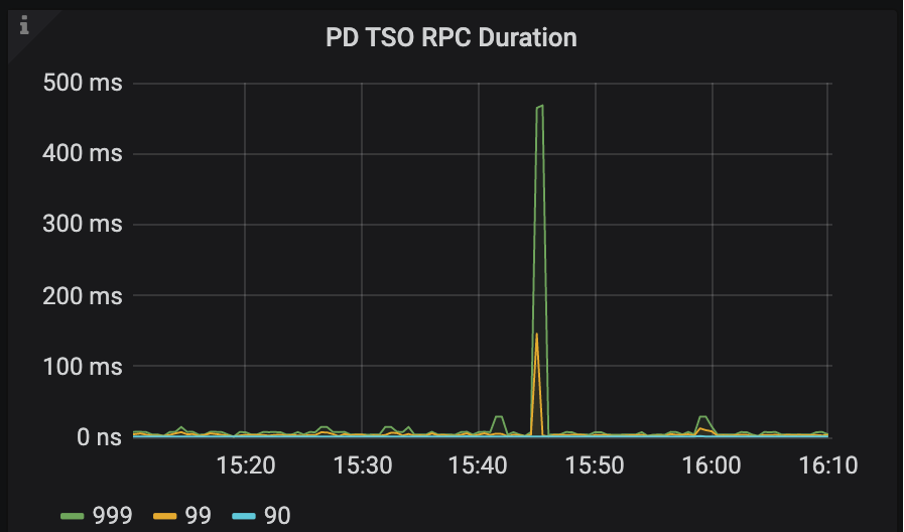
第二阶段中 TiDB 向 PD 发起 RPC 请求的 Duration 对应的监控项是 PD TSO RPC Duration。
- 位置:TiDB – PD Client – PD TSO RPC Duration 面板
-
PD TSO RPC Duration : 反应向 PD 发起 RPC 请求的耗时,如果 duration 比较高,可能的原因如下:
- TiDB 和 PD 之间的网络延迟高,可以通过 Blackbox exporter Dashboard 下面的 Network Status - Ping Latency 监控项确认。
- PD 负载太高,不能及时处理 TSO 的 RPC 请求,可以通过 PD Dashboard 下的 TiDB - handle_requests_duration_seconds 监控项确认。
-
第一阶段拿到 tsFuture 对象后到第三阶段调用 tsFuture.Wait() 这段过程的 Duration 对应的监控项是 TSO Async Duration;拿到 tsFuture 之后还需要进行 SQL Parse 和 Compile 成执行计划,真正执行的时候才会调用 tsFuture.Wait()
- 位置:TiDB – PD Client – PD Client CMD Duration (wait)
- TSO Async Duration:从获取 ts future,到开始 wait ts future 的耗时,如果 duration 比较高,可能的原因如下:
- 这个 SQL 很复杂,Parse 花费了很长的时间
- Compile 花费了很长时间
-
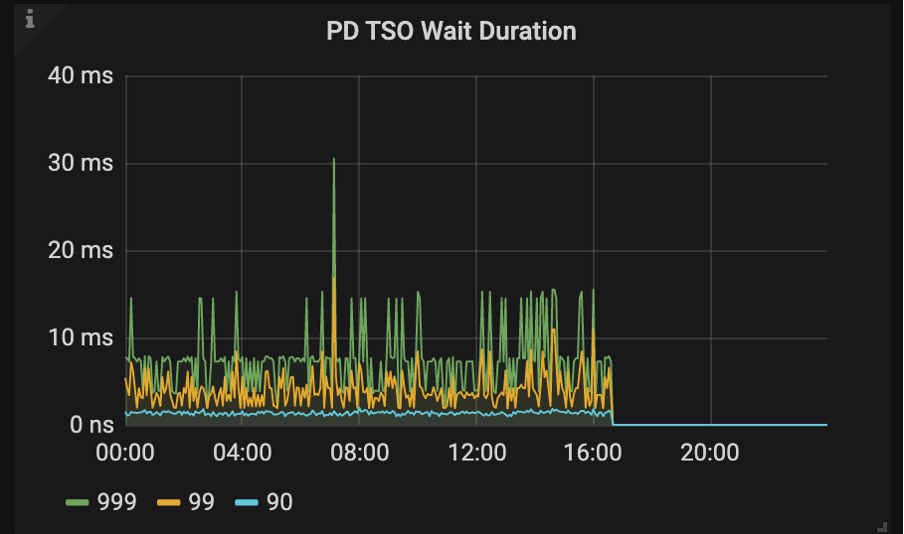
如果 Parser 和 Compile 过程很快完成了,第三阶段中调用 tsFuture.Wait() 时 PD 的 TSO RPC 还没有返回,就需要等待,这段等待时间对应的监控项是 PD TSO Wait Duration
- 位置:TiDB – PD Client – PD TSO Wait Duration 面板
- PD TSO Wait Duration:调用 wait ts future 之后等待 future 返回的耗时,受网络和 runtime 影响
注意:读取只向 PD拿一次 TSO 就够了。写入的话,需要拿两次,因为写流程两阶段提交,需要取两次 tso,包括:start_ts + commit_ts。并且暂时不会支持通过 start_ts 计算出 commit_ts 减少拿的次数。所以在压测场景下,写入场景一般会比读场景的 PD TSO Wait Duration 的指标值高很多。