北京大爷
(北京大爷)
1
1.协议层
TiDB 兼容 MySQL 5.7 协议,TiDB 4.0 以上,兼容部分 MySQL 8.0,详情请参考 GitHub
当和客户端的连接建立好之后,TiDB 中会有一个 Goroutine 监听端口,等待从客户端发来的包,并对发来的包做处理。
默认情况下,可以同时执行的 SQL count 为 1000,由 token-limit 参数控制。在特殊场景下 可以使用此参数对 TiDB Server 线程加以限制。
注:OLTP 场景下,建议连接数应该少于500个,并且需要密切关注不同 tidb-server 之间连接数的均匀分布。
监控说明:
8 个赞
北京大爷
(北京大爷)
3
2.Parser 模块
Parser 主要是检查关键字的正确语法和拼写,并将文本解析为 AST(抽象语法树)
监控说明:
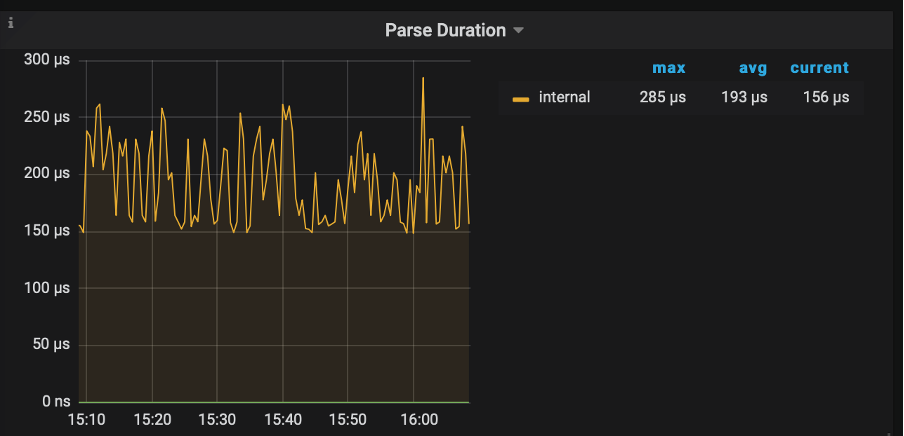
- 位置:TiDB – Executor – Parse Duration 面板
正常情况下,“Parse Duration” 小于 10ms
Parser 相关问题处理:
-
报错原理解读
- MySQL client 报错内容:“ERROR 1064 (42000): You hava an error in your SQL syntax;…”
- 说明:如果有这个报错,可以明确确认是 Parser 报错
语法报错 log 日志内容:“parser error” and with stack “(Parser).Parse”
-
Parser 报错判断
- 查看错误消息或日志,是否有报错码 1064 等。
- 在 MySQL 中是否可以执行: MySQL 5.7 语法 MySQL 8.0 部分语法
- 判断 TiDB 是否支持,可以看 parser 文件,来确认 TiDB 已经支持的语法
- 检查 MySQL 的定义
- 当发现语法是 TiDB 支持,如果有报错,可以判断为非预期,需要修复
- 当发现语法是 TiDB 不支持,但是 MySQL 支持,可以向我们提需求做兼容
-
Parser 性能优化
- 使用 prepare 语句遍历解析器阶段
- 简化SQL语句 (如,太多的’ ifnull() '表达式)
5 个赞
北京大爷
(北京大爷)
4
3.Compile 模块
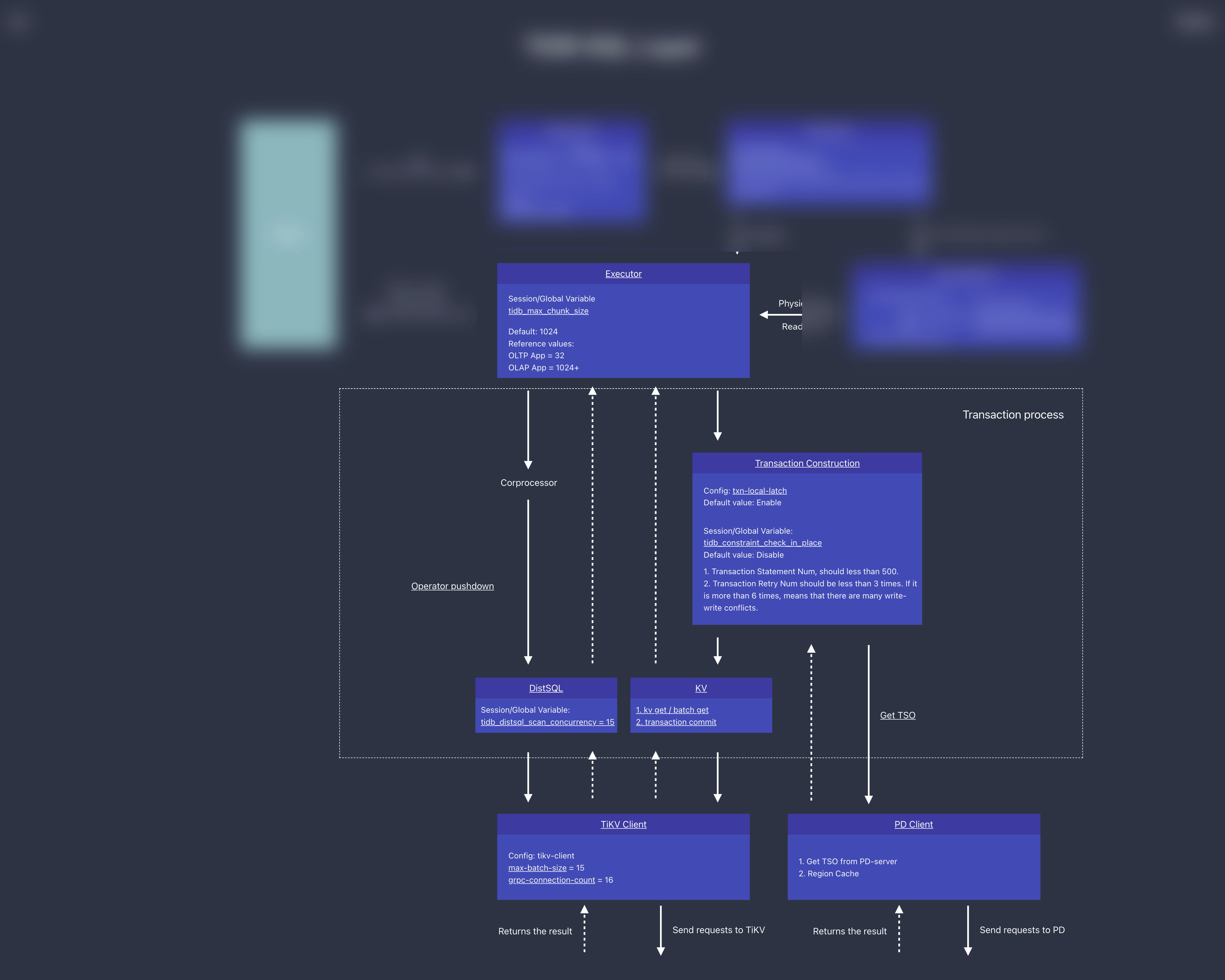
拿到 AST 之后,就可以做各种验证(预处理、合法性验证,权限检验)、变换、优化,这一系列动作的入口在 compile,最重要的三个步骤:
- 做一些合法性检查以及名字绑定;
- 制定查询计划,并优化,这是最核心的步骤之一。这里有一个特殊的函数 TryFastPlan,如果这里判断规则可以符合 PointGet,会跳过后续的优化,直接走点查
- 构造 executor.ExecStmt 结构:这个 ExecStmt 结构持有查询计划,是后续执行的基础
监控说明:
3 个赞
北京大爷
(北京大爷)
5
4.生成 + 运行 Executor
TiDB 会将 plan 转换成 executor,运行时会将所有的物理 executor 构造一个树状结构,每一层通过调用下一层获取结果。
监控说明:
3 个赞
北京大爷
(北京大爷)
6
4.1.获取 Key 所在的 Region 和 TSO
TiDB 通过向 PD 发送请求实现 region 的定位以及获取 TSO。
TiDB 先访问 PD 获取 TSO,然后访问 tidb-server 本地 Region Cache,按照获得的路由信息,将请求发送给 TiKV。
Region Cache
- TiDB 先访问 pd 获取 tso,然后访问 tidb-server 本地 Region Cache,然后按照获得的路由信息,将请求发给 TiKV,如果 TiKV 返回错误说明路由信息过旧,这个时候 tidb-server 会去 pd 重新取 region 的最新路由信息,并更新 region cache。如果,请求发送到 follower 了,TiKV 会返回 not leader 的错误并把谁是 leader 的信息返回给 tidb-server, 然后 tidb-sever 更新 Region Cache。
获取 TSO
- 所有 TiDB 与 PD 交互的逻辑都是通过一个 PD Client 的对象进行的,这个对象会在服务器启动时创建 Store 的时候创建出来,创建之后会开启一个新线程,专门负责批量从 PD 获取 TSO。对于这些 TSO 请求,分为三个阶段:
- 将一个 TSO 请求放入 channel,对应的函数为 GetTSAsync,调用这个函数会得到一个 tsFuture 对象
- TSO 线程从 channel 拿到请求向 PD 发起 RPC 请求,获取 TSO,获取到 TSO 之后分配给相应的请求
- TSO 分配给相应的请求之后,就可以通过持有的 tsFuture 获取 TSO(调用 tsFuture.Wait())
监控说明:
-
目前系统没有对第一个阶段设置相应的监控信息,这个过程通常很快,除非 channel 满了,否则 GetTSAsync 函数很快返回,而 channel 满表示 RPC 请求延迟可能过高,所以可以通过 RPC 请求的 Duration 来进一步分析。
-
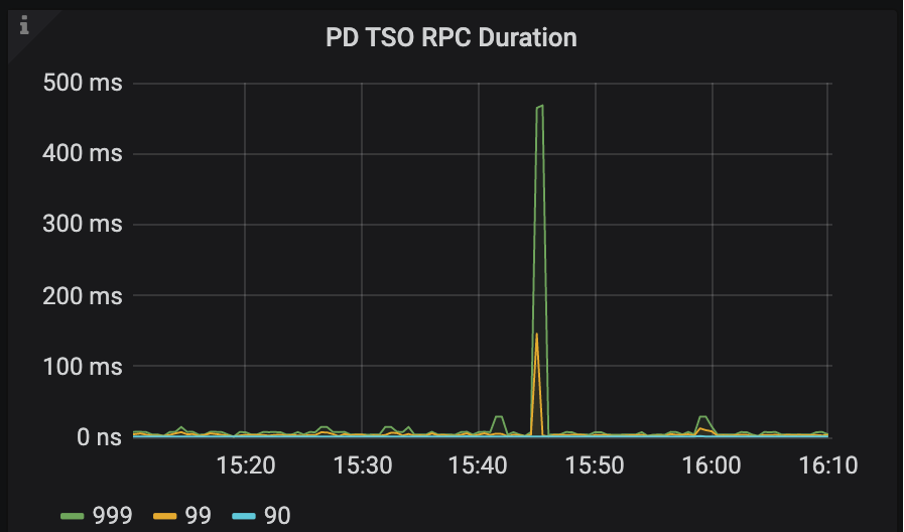
第二阶段中 TiDB 向 PD 发起 RPC 请求的 Duration 对应的监控项是 PD TSO RPC Duration。
- 位置:TiDB – PD Client – PD TSO RPC Duration 面板
-
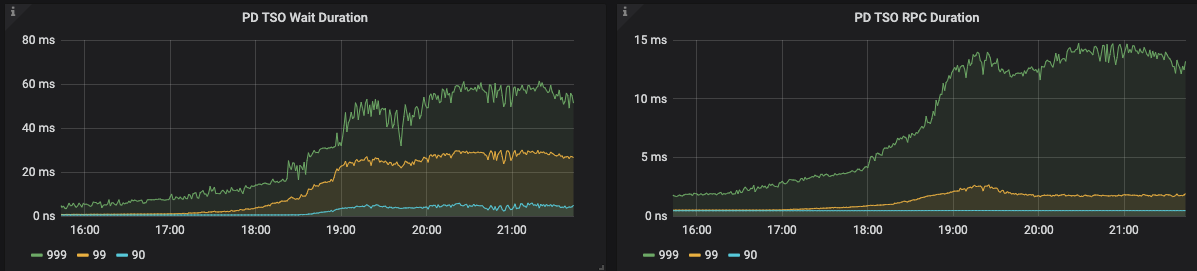
PD TSO RPC Duration : 反应向 PD 发起 RPC 请求的耗时,如果 duration 比较高,可能的原因如下:
- TiDB 和 PD 之间的网络延迟高,可以通过 Blackbox exporter Dashboard 下面的 Network Status - Ping Latency 监控项确认。
- PD 负载太高,不能及时处理 TSO 的 RPC 请求,可以通过 PD Dashboard 下的 TiDB - handle_requests_duration_seconds 监控项确认。
-
第一阶段拿到 tsFuture 对象后到第三阶段调用 tsFuture.Wait() 这段过程的 Duration 对应的监控项是 TSO Async Duration;拿到 tsFuture 之后还需要进行 SQL Parse 和 Compile 成执行计划,真正执行的时候才会调用 tsFuture.Wait()
- 位置:TiDB – PD Client – PD Client CMD Duration (wait)
- TSO Async Duration:从获取 ts future,到开始 wait ts future 的耗时,如果 duration 比较高,可能的原因如下:
- 这个 SQL 很复杂,Parse 花费了很长的时间
- Compile 花费了很长时间
-
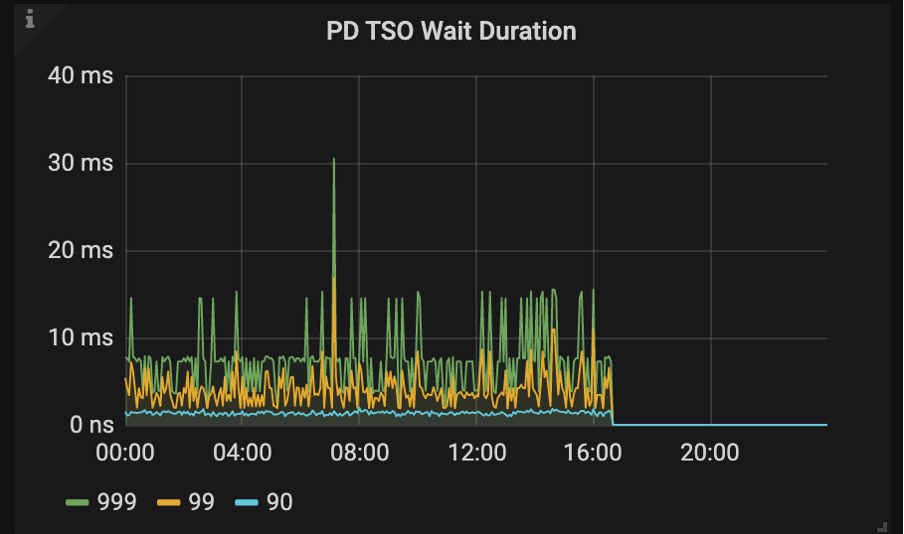
如果 Parser 和 Compile 过程很快完成了,第三阶段中调用 tsFuture.Wait() 时 PD 的 TSO RPC 还没有返回,就需要等待,这段等待时间对应的监控项是 PD TSO Wait Duration
- 位置:TiDB – PD Client – PD TSO Wait Duration 面板
- PD TSO Wait Duration:调用 wait ts future 之后等待 future 返回的耗时,受网络和 runtime 影响
注意:读取只向 PD拿一次 TSO 就够了。写入的话,需要拿两次,因为写流程两阶段提交,需要取两次 tso,包括:start_ts + commit_ts。并且暂时不会支持通过 start_ts 计算出 commit_ts 减少拿的次数。所以在压测场景下,写入场景一般会比读场景的 PD TSO Wait Duration 的指标值高很多。
3 个赞
北京大爷
(北京大爷)
7
4.2.DistSQL API
请求的分发与汇总会有很多复杂的处理逻辑,比如上小节说的出错重试、获取路由信息、控制并发度以及结果返回顺序,为了避免这些复杂的逻辑与 SQL 层耦合在一起,TiDB 抽象了一个统一的分布式查询接口,称为 DistSQL API,位于 distsql 这个包中。
DistSQL 是位于 SQL 层和 Coprocessor 之间的一层抽象,它把下层的 Coprocessor 请求封装起来对上层提供一个简单的 Select 方法。执行一个单表的计算任务。最上层的 SQL 语句可能会包含 JOIN,SUBQUERY 等复杂算子,涉及很多的表,而 DistSQL 只涉及到单个表的数据。一个 DistSQL 请求会涉及到多个 Region,我们要对涉及到的每一个 Region 执行一次 Coprocessor 请求。
监控说明:
6 个赞
北京大爷
(北京大爷)
10
TiDB server 其他错误
可能出现的错误
- 发送请求过程中,根据 RegionCache 中的 Region 信息切分,但是 Region 信息可能已经过期,包括
- Region 发生了分裂
- Region 发生了合并
- Region 发生了调度
- 一个请求中的部分 Key 上可能有锁
- 其他错误
错误是如何处理的?
- 如果是 Region 相关的错误,会先进行 Backoff,然后进行重试,比如:
- Region 信息过期会使用新的 Region 信息重试任务
- Region 的 leader 切换,会把请求发送给新的 Leader
- 如果部分 Key 上有锁,会进行 Resolve lock
- 如果有其他错误,则立即向上层返回错误,中断请求
错误相关的监控有哪些?
- KV Errors
- KV Retry Duration:KV 重试请求的时间
- TiClient Region Error OPS:TiKV 返回 Region 相关错误信息的数量
- KV Backoff OPS(TiDB - KV Errors):TiKV 返回错误信息的数量(事务冲突等)
- Lock Resolve OPS:事务冲突相关的数量
- Other Errors OPS:其他类型的错误数量,包括清锁和更新 SafePoint
一些常见问题补充:
- Backoff 是什么意思?→ Backoff 就是本次请求失败了,sleep 一小段时间再进行重试
- Backoff sleep 的时间长短如何确定?→ TiDB 中的 Backoff 对于不同的请求以及错误类型使用不同的 Backoff 算法,具体可以参考文档1 参考文档2
- Backoff 会一直进行吗?→ 不会
- Backoff 什么时候终止?→ 每一次失败重试之前都会 sleep 一段时间,Backoff 终止的依据是多次重试的 sleep 时间总和大于阈值
- Backoff 的阈值如何确定的?→ 目前是写死在代码之中,参考以下列表,单位毫秒
- copBuildTaskMaxBackoff = 5000
- tsoMaxBackoff = 15000
- scannerNextMaxBackoff = 20000
- batchGetMaxBackoff = 20000
- copNextMaxBackoff = 20000
- getMaxBackoff = 20000
- prewriteMaxBackoff = 20000
- cleanupMaxBackoff = 20000
- GcOneRegionMaxBackoff = 20000
- GcResolveLockMaxBackoff = 100000
- deleteRangeOneRegionMaxBackoff = 100000
- rawkvMaxBackoff = 20000
- splitRegionBackoff = 20000
- maxSplitRegionsBackoff = 120000
- scatterRegionBackoff = 20000
- waitScatterRegionFinishBackoff = 120000
- locateRegionMaxBackoff = 20000
- pessimisticLockMaxBackoff = 10000
- pessimisticRollbackMaxBackoff = 10000
- Region Error 和 Lock 可以通过监控排查,其他错误怎排查?→ 在日志中搜索 “other error”
举一个简单的例子:
一个请求发送到 TiKV 的超时时间是 60s,如果返回了错误之后每次 backoff 1s,总的 Backoff 时间是 5s,那么这种情况可以重试 5 次。考虑一种情况:前四次请求失败,且每次失败都是可重试错误,最后一次请求成功,每次请求返回时间都是 50s,那么这个请求的总的时间为 50 * 4 + 1 * 4 + 50。
这个例子想要说明的问题是什么呢?如果发现 Duration 耗时很长,不但需要去看 Backoff 的监控,还需要去查看单次 KV Duration 的耗时,以及 KV Errors 的监控进一步排查问题。
13 个赞
信仰在空中飘扬
(信仰在空中飘扬)
17
有点疑惑: 连接数限制为1000 是指的单个tidb-server 的同时在运行的连接么 ? 还是说也包括sleep 的那些连接 ?
2 个赞
北京大爷
(北京大爷)
18
这里只的是 可以在 tidb 拿到执行资格的 SQL 数量。可以理解为 可以同时执行 SQL 数量的带宽。针对这部分的描述已加以修改说明
感谢反馈
2 个赞
信仰在空中飘扬
(信仰在空中飘扬)
20
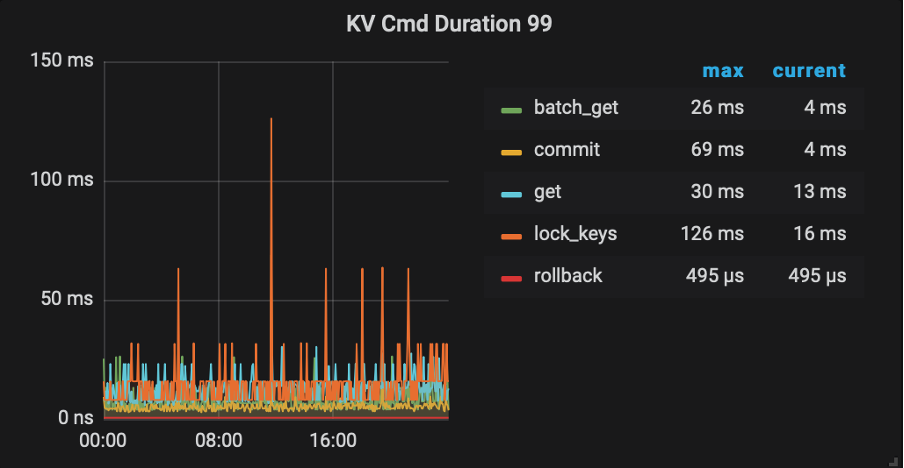
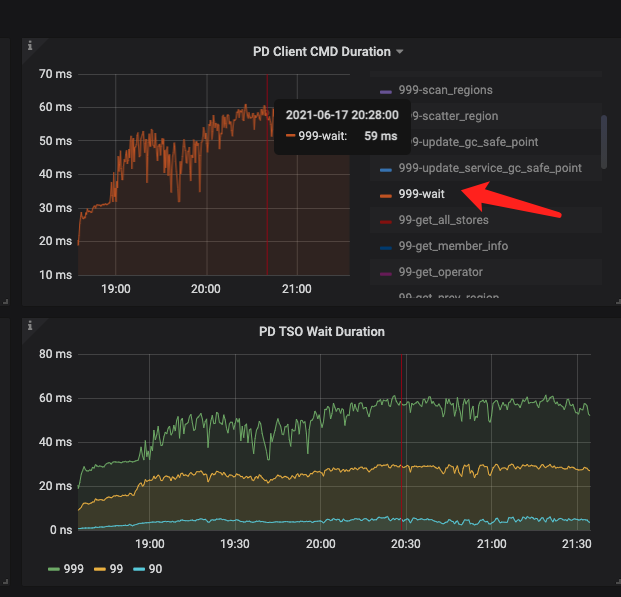
此图为我们生产集群监控图。
此处你的解读是:
问题1:我怎么觉得这个cmd duration – wait 跟 tso wait duration 是同一个意思,跟sql 解析没什么关系呢 ?
问题2: * PD TSO Wait Duration:调用 wait ts future 之后等待 future 返回的耗时,受网络和 runtime 影响
这里的runtime 指的是什么 ?我们业务集群在高峰期tso wait duration 增加到60ms 左右,但是parse + compile 时间都比较短,tso rpc 时间也较短。不知为何wait duration 会这么长
2 个赞
Hi~ 请问问题解决了吗 ?从你的问题来看,你遇到了 PD TSO duration 高,导致业务请求延迟的情况。
和 SQL 优化的 Parse 没有关系,Parse 层就是做 SQL 语义识别和转化,不涉及 Get tso 。
可以如果可以,需要看一下 TiDB Server 的监控看看,比如 TiDB Server 的 Get token duration 或者 Go goroutine count 的情况
1 个赞
wink
(winkyao)
22
第一个问题是这样的:
- TSO Async Duration:从获取 ts future,到开始 wait ts future 的耗时,如果 duration 比较高,可能的原因如下:
- 这个 SQL 很复杂,Parse 花费了很长的时间
- Compile 花费了很长时间
第一个 wait 还没有真正从 TiDB 发出 rpc 请求到 PD 获取 TSO,那个监控是后面提到的 PD TSO Wait Duration 的监控。所以第一个wait 是从接到请求到真正发出请求的时间,这里面有:Parse 语句阶段,还有 Compile 生成执行计划阶段。
1 个赞