北京大爷
2021 年1 月 21 日 08:46
1
读相关的请求主要包含 kv_get / kv_batch_get / coprocessor 三个接口,可以通过以下监控查看请求的数量、失败数量、延迟等情况:
TiKV-Detail → gRPC → gRPC message count:每种 gRPC 消息的个数
TiKV-Detail → gRPC → gRPC message failed:失败的 gRPC 消息的个数
TiKV-Detail → gRPC → gRPC message duration:gRPC 消息的执行时间
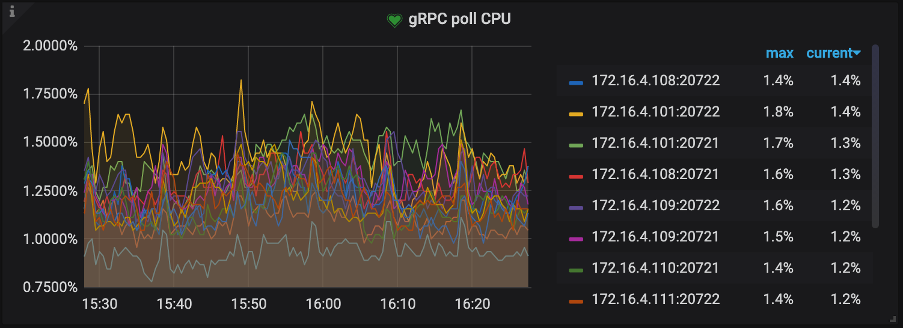
TiKV-Detail → thread CPU → gRPC poll CPU:gRPC 线程的 CPU 使用率,gRPC 线程是一个纯 CPU 的线程,不涉及 IO 操作,如果使用率过高,可以考虑调整 gRPC 线程数量,不然客户端请求会因为处理不及时导致延迟加大,此时 gRPC 会成为瓶颈
以上监控能对整个过程进行一个概览性的分析,如果其中某一个监控指标出现了异常,就需要进一步分析,kv_get / kv_batch_get / coprocessor 以上这三个接口的流量,他们分别在两个线程池执行,分别为:
Storage read threads pool (kv_get / kv_batch_get 接口)
Coprocessor threads pool (coprocessor 接口)。
1 个赞
北京大爷
2021 年1 月 21 日 09:20
3
无论是走 Storage read pool 还是 Coprocessor pool 两个线程池,在处理请求之前都需要先构建一个 Snapshot ,我们后续的读都是基于这个 Snapshot 的,这也是为什么 TiDB 的隔离级别叫 Snapshot 隔离级别的一个原因。
通常获取 Snapshot 很快,但会有一些场景影响 Snapshot 获取时间:
2 个赞
北京大爷
2021 年1 月 21 日 09:37
4
我们所有的数据都是以 KV 形势存储在 RockDB 中的,我们把这个 RockDB 称为 RockDB-KV。
可能有用户发现了 还有一个模块叫 RockDB-Raft ,ta 是用户同步 Raft 日志的,为了保证数据的一致性,所以也会将 RaftLog 进行持久化
查找的数据需要尽可能在内存中查找,所以查看对应监控信息,来分析读取 KV 键值对的过程中,不同类型的操作所占比例是否合理(下面的监控指标在 TiKV-Detail → RocksDB-kv 下):
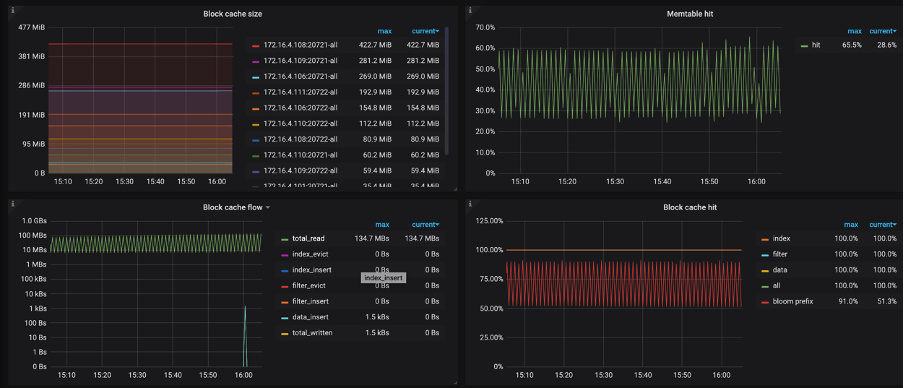
Block Cache/MEM hit,这一部分依赖 Memory,对应的监控信息有:
Block cache size:block cache 的大小。如果将 shared-block-cache 禁用,即为每个 CF 的 block cache 的大小
Block cache hit:block cache 的命中率
Block cache flow:不同 block cache 操作的流量
Block cache operations 不同 block cache 操作的个数
读取 SST Files,这部分主要依赖 IO,对应的监控信息为:
SST read duration:读取 SST 所需的时间 (Ta 也在 TiKV-Detail → RocksDB-kv 下)
二分查找过程中会比较 Key 的大小,这部分依赖 CPU,对应的监控有:
TiKV-Detail → Thread CPU → RocksDB CPU:RocksDB 线程的 CPU 使用率
以上任何一个环节出现瓶颈,都可能导致读取 KV 键值对的延迟比较高,比如 Block cache size 非常小,命中率很低,那么每次都需要通过 SST File 读取数据必然延迟会加高,如果更糟糕的情况发生,比如 IO 打满或 CPU 打满,延迟会进一步加大。
如果 Block cache 命中率小,可以通过 Block cache flow 和 Block cache operations 进一步定位 Block cache 上面发生的事件。
SST 文件由 Index Block(数据索引)、Filter Block(一般是 bloom filter 的数据) 和 Data Block 组成,因此在 Block Cache 相关监控中会出现 index, filter, data 相关的多个曲线。在 RocksDB 中,Block Cache 也会被分为多个 shard(由 num_shard_bits 参数控制,默认值为 6,也就是 64 个 shard,在 3.0 中已支持修改)。
在 Block Cache 的大小已经比较大的情况下,如果还是观察到 Block Cache 命中率低,evict 数据量大(见 Block cache flow)
首先可以观察是否有一个很大的 SST 文件,由于其 index block 和 filter block 很大导致其他 SST 的 cache 失效,这个 SST 文件通常是由于 Region 调度时生成 Snapshot 产生的,如果有则可以考虑手动触发 compaction 将其分散成小文件。
如果没有大 SST,则考虑是由于请求的 Block Cache 都落在同一个 shard 里,在 3.0 中可以通过调小 num_shard_bits,或者通过进一步调高 Block Cache 大小,来解决 Cache 命中率低的问题。
1 个赞
北京大爷
2021 年1 月 21 日 10:19
5
storage read 主要是解决我们 查询中的 点查来单独设置的 线程池。及使用 主键与唯一索引进行等值查询 ,才会走 storage read pool 这个快速通道。通常情况下storage read pool 这里不应该看到很慢的场景
Storage read threads pool 可以通过以下监控来排查(下面的监控指标在 TiKV-Detail → Storage 下):
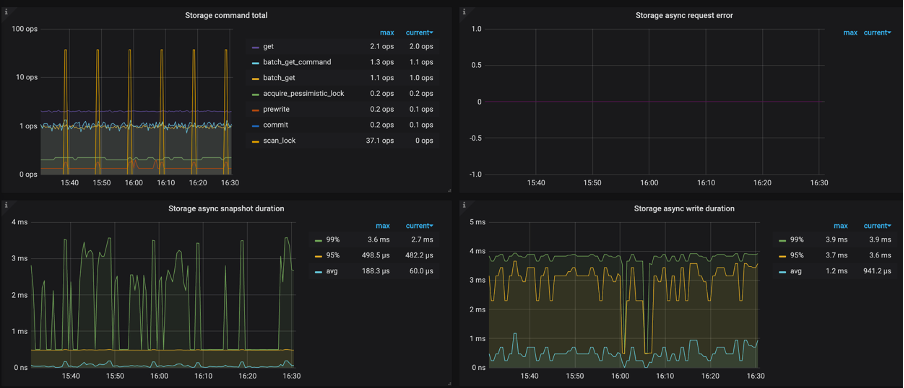
Storage command duration:执行 get 命令所需花费的时间(按照之前的说明,这部分时间就是调度之后,RocksDB->GetSnapshot() + Snapshot->Get(key) 的时间总和,所以不包含调度本身花费的时间)
Storage command total:可以查看 get 命令的数量
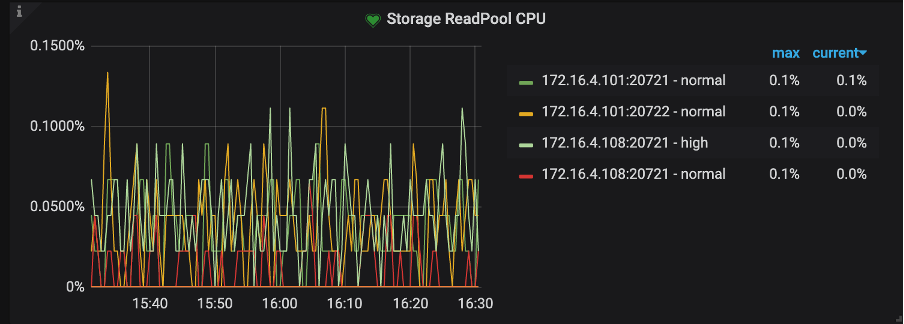
TiKV-Detail → Thread CPU ->Storage ReadPool CPU:Readpool 线程的 CPU 使用率
比较套路的排查思路是先看一下 CPU 是不是被打满了,如果被打满了看是不是命令的数量比较多,如果 CPU 没有打满,但是 Storage command duration 延迟比较高,就按照获取 Snapshot 和从 Snapshot 中获取 KV 比较慢进行排查(上面已讲,这里不再复述)
1 个赞
北京大爷
2021 年1 月 21 日 10:31
6
Coprocessor pool 可以通过以下监控来排查(下面的监控指标在 TiKV-Detail → Coprocessor Overview/detail 下):
Wait duration:请求被调度 + 获取 Snapshot + 构建 Handler 的时间总和(监控中包含 max / .99 / .95 对应的延迟)
Handle duration: 使用 Handler 处理这个请求的时间,Handle 过程包含:
TiKV-Detail → Thread CPU → Coprocessor CPU:coprocessor 线程的 CPU 使用率
除了以上比较重要的监控指标,也可以通过以下监控辅助排查:
TiKV-Detail → Coprocessor Overview → Request errors:下推的请求发生错误的个数,正常情况下,短时间内不应该有大量的错误
TiKV-Detail → Coprocessor Detail → DAG executors:DAG executor 的个数,重点看一下 TableScan 算子的数量,排查是否有大查询扫表将 CPU 资源占用
Scan keys:每个请求 scan key 的个数,如果 Scan keys 的数量特别大,会占用大量的系统资源,导致请求的延迟变大
Scan details:scan 每个 CF 的详细情况
Table Scan - Details by CF:table scan 针对每个 CF 的详细情况
Index Scan - Details by CF:index scan 针对每个 CF 的详细情况
Table Scan - Perf Statistics:执行 table sacn 的时候,根据 perf 统计的 RocksDB 内部 operation 的个数
Index Scan - Perf Statistics:执行 index sacn 的时候,根据 perf 统计的 RocksDB 内部 operation 的个数
1 个赞
北京大爷
2021 年1 月 22 日 05:47
7
其他问题: 一、读请求过程中出现错误
可能出现的错误
请求是根据 tidb-server 中的 region cache 里的 region 信息进行发送的,而在实际中,部分 region 信息可能因为如下原因导致过期,主要包括:
一个请求中的部分 Key 上可能有锁
其他错误
错误是如何处理的?
如果是 Region 相关的错误,会先进行 Backoff,然后进行重试,比如:
如果有其他错误,则立即向上层返回错误,中断请求
错误相关的监控有哪些?
TiDB -> KV Errors
KV Retry Duration:KV 重试请求的时间
TiClient Region Error OPS:TiKV 返回 Region 相关错误信息的数量
KV Backoff OPS:TiKV 返回错误信息的数量(事务冲突等)
KV Backoff OPS:TiKV 返回错误信息的数量(事务冲突等)
Lock Resolve OPS:事务冲突相关的数量
Other Errors OPS:其他类型的错误数量,包括清锁和更新 SafePoint
TiKV -> Errors
Server is busy
Coprocessor error
gRPC message error
leader drop
leader missing
TiKV -> gRPC -> gRPC message failed
二、MVCC/TombStone 数量太多
导致版本过多的应用场景
业务使用了计数器
gc时间比较长,且修改频繁
版本过多导致的问题
需要更多的存储空间
同一个key的所有版本在底层存储上是相邻的,当scan一个范围的时候需要跳过很多的历史版本,同一个key的所有版本在底层存储上是相邻的,这些历史版本也会因为key的最近的版本被访问而从磁盘读取出来并缓存在block-cache中
相关的监控有哪些
TiKV-Detail -> Coprocessor Overview -> Total RocksDB Perf Statistics
TiKV-Detail -> Coprocessor Detail -> Total Ops Details(Table Scan)
TiKV-Detail -> Coprocessor Detail -> Total Ops Details(Index Scan)
TiKV-Detail -> Coprocessor Detail -> Total Ops Details by CF (Table Scan)
TiKV-Detail -> Coprocessor Detail -> Total Ops Details by CF (Index Scan)
处理方式
调整 GC 的频率及时间
对 tikv 进行 compact 操作
三、读热点问题
判断读热点依据
方式一:在监控面板 TiKV-Details -> Thread CPU 中查看
方式二:在监控面板 TiKV-Throuble-Shooting -> Hot Read 中查看
若确定存在读热点,需定位到具体的热点表或索引
方式一:通过 tidb dashboard 热力图定位(推荐方式)
方式二:通过 TiDB API
查询读流量最大的 Region ID
pd-ctl -u http://{pd}:2379 -d region topread [limit]
根据 Region ID 定位到表或者索引 curl http://{TiDBIP}:10080/regions/{RegionId}
读热点解决方法
根据监控面板 TiKV-Details -> RocksDB KV -> Block Cache hit 命中率来判断
若 BlockCache 的命中率下降或者抖动,可能是存在全表扫描的 SQL、执行计划选择不正确的 SQL、存在大量 count(*) 操作的 SQL 等等,解决方法:
若 BlockCache 命中率比较稳定,则可能是 Region 并发读取过高导致,在业务查询频繁的命中个别 Region 最终时会导致单个 TiKV 节点性能达到极限,几种解决方法供参考:
四、Pending Task
TiKV 后台会不定时执行一些操作,比如 compaction、gc、split region 等,如果这些 任务执行时间很长,也会增加读请求的延迟
另外,尽管可能性很低,但如果执行读请求相关的任务发生了阻塞,读请求相应的时间会变长,所以我们也建议查看是否发生了 pending task,具体相关的监控,可以查看
tikv-detail -> task -> pending task
五、get、seek 慢
Get接口提供用户一种从DB中查询key对应value的方法
Seek()函数查找大于或等于指定key值的第一个键值对的位置
通常 get 是比 seek 操作更轻,如果 get/seek的耗时较长,可能是集群负载较高、磁盘性能出现问题,对应的耗时情况,可以通过下面指标查看:
RocksDB - kv / raft
Get operations:get 操作的个数
Get duration:get 操作的耗时
Seek operations:seek 操作的个数
Seek duration:seek 操作的耗时
Write operatioxins:write 操作的个数
Write duration:write 操作的耗时
WAL sync operations:sync WAL 操作的个数
WAL sync duration:sync WAL 操作的耗时
Compaction operations:compaction 和 flush 操作的个数
Compaction duration:compaction 和 flush 操作的耗时
SST read duration:读取 SST 所需的时间
六、grpc 超过网卡处理能力
如果 tidb-server的网卡是千兆的,可能会由于执行计划不对,扫描的数据量太多,导致 tikv 把 tidb-server 的网卡打满,影响查询速度。
相关监控:
Overview -> System Info -> Network traffic
七、服务器资源
如果服务器资源使用显示不高,但又发现集群处于堵塞状态,需要查看是否开启了资源使用相关控制,另外 tidb 在使用中,不建议开启 swap,如果开启了,需要进行如下操作:
集群是否开启了 resource control,可在集群参数文件中查看
系统上是否采用了 numactl 对内存或 CPU 进行了资源控制
3 个赞