RockDB-KV 模块
我们所有的数据都是以 KV 形势存储在 RockDB 中的,我们把这个 RockDB 称为 RockDB-KV。
可能有用户发现了 还有一个模块叫 RockDB-Raft ,ta 是用户同步 Raft 日志的,为了保证数据的一致性,所以也会将 RaftLog 进行持久化
MEM/Block Cache 命中率
查找的数据需要尽可能在内存中查找,所以查看对应监控信息,来分析读取 KV 键值对的过程中,不同类型的操作所占比例是否合理(下面的监控指标在 TiKV-Detail → RocksDB-kv 下):
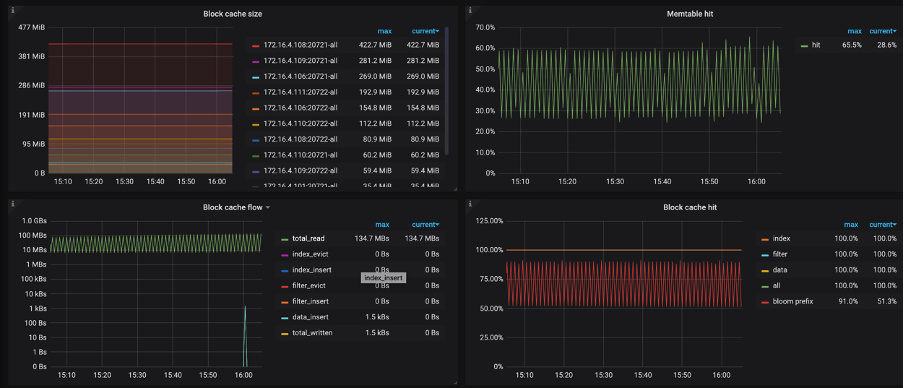
-
Block Cache/MEM hit,这一部分依赖 Memory,对应的监控信息有:
- Block cache size:block cache 的大小。如果将 shared-block-cache 禁用,即为每个 CF 的 block cache 的大小
- Block cache hit:block cache 的命中率
- Block cache flow:不同 block cache 操作的流量
- Block cache operations 不同 block cache 操作的个数
-
读取 SST Files,这部分主要依赖 IO,对应的监控信息为:
- SST read duration:读取 SST 所需的时间 (Ta 也在 TiKV-Detail → RocksDB-kv 下)
- SST read duration:读取 SST 所需的时间 (Ta 也在 TiKV-Detail → RocksDB-kv 下)
-
二分查找过程中会比较 Key 的大小,这部分依赖 CPU,对应的监控有:
- TiKV-Detail → Thread CPU → RocksDB CPU:RocksDB 线程的 CPU 使用率
- TiKV-Detail → Thread CPU → RocksDB CPU:RocksDB 线程的 CPU 使用率


以上任何一个环节出现瓶颈,都可能导致读取 KV 键值对的延迟比较高,比如 Block cache size 非常小,命中率很低,那么每次都需要通过 SST File 读取数据必然延迟会加高,如果更糟糕的情况发生,比如 IO 打满或 CPU 打满,延迟会进一步加大。
- 如果 Block cache 命中率小,可以通过 Block cache flow 和 Block cache operations 进一步定位 Block cache 上面发生的事件。
- SST 文件由 Index Block(数据索引)、Filter Block(一般是 bloom filter 的数据) 和 Data Block 组成,因此在 Block Cache 相关监控中会出现 index, filter, data 相关的多个曲线。在 RocksDB 中,Block Cache 也会被分为多个 shard(由 num_shard_bits 参数控制,默认值为 6,也就是 64 个 shard,在 3.0 中已支持修改)。
- 在 Block Cache 的大小已经比较大的情况下,如果还是观察到 Block Cache 命中率低,evict 数据量大(见 Block cache flow)
- 首先可以观察是否有一个很大的 SST 文件,由于其 index block 和 filter block 很大导致其他 SST 的 cache 失效,这个 SST 文件通常是由于 Region 调度时生成 Snapshot 产生的,如果有则可以考虑手动触发 compaction 将其分散成小文件。
- 如果没有大 SST,则考虑是由于请求的 Block Cache 都落在同一个 shard 里,在 3.0 中可以通过调小 num_shard_bits,或者通过进一步调高 Block Cache 大小,来解决 Cache 命中率低的问题。