-
问题定位
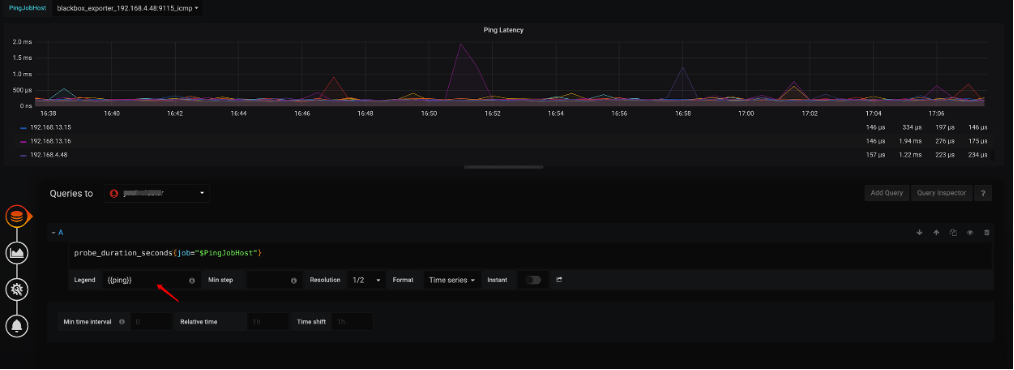
通过 TiDB 监控
Blackbox-expoter → Network Status → Ping Latency
来确认 Instance 到各个 host 的网络情况,正常情况下各个服务器延迟抖动应在 2ms 以内,如果抖动过大需要排查对应 Host 网络延迟的根因。
(如果展示数据因为过长而不能看清,可以通过修改 监控面板 Edit → A → Legend → {{ping}} 来展示 目标 Host IP) -
解决方法
更换更加稳定的网络线路,建议满足万兆带宽,Ping 延迟在 200μs 以内,丢包率 0%带宽打满
-
问题定位
通过监控项
Overview → System Info → Network Traffic
观察问题时间段内是否有 host出现网络带宽接近 100% -
解决方法
如果服务节点间的混部导致的网络带宽打满情况,请排查部署是否符合 部署最佳实践
如果问题节点是 某一 TiDB 节点,应排查 TiDB 的请求是否经过 LB 进行负责均衡,避免所有请求都集中在一台 TiDB 上。
-
系统配置是否符合最佳实践
TiDB Server -> 计算密集型服务
TiKV Server -> IO密集型服务、计算型服务
TiFlash Server -> IO密集型服务、计算密集型服务
PD Server -> 均衡型服务
-
问题定位
TiDB 分布式数据库,为了满足生产环境的可用性,对硬件资源是有较高要求,往往很多性能问题都是由于硬件资源不达标导致的,性能表现异常。所以请一定核对现有集群是否满足配置要求组件 CPU 内存 磁盘 网络 TiDB 16 Core+ 32 GB+ SAS HDD 万兆网卡 TiKV 16 Core+ 32 GB+ SSD 万兆网卡 PD 4 Core+ 8 GB+ SSD 万兆网卡 TiFlash 48 Core+ 128 GB+ SSD or more 万兆网卡 TiCDC 16 Core+ 64 GB+ SAS HDD 万兆网卡 注意:
CPU 主频应至 ≥ 2 GHz
SSD 磁盘 顺序写随机读的 IOPS 应≥ 10000+,带宽 > 1000 MB
SSD 磁盘容量推荐 1T 以上,但不要大于 2T。防止当 TiKV 实例管理的 region 数量过多。如果磁盘容量在 3T 或以上,在 CPU 与内存资源满足的情况下可以考虑 单机双 TiKV 实例部署同时相关系统设置也应符合最佳实践建议
-
解决方法
按照最佳实践配置部署服务器
TiDB 软件和硬件环境建议配置
TiDB 环境与系统配置检查
-
问题定位
HOST System Info
Overview → System Info
查看各 Host 的 CPU Core、CPU Usage、CPU Load
TiKV CPU
Overview → TiKV → CPU
查看各 TiKV Instance CPU 使用情况(此处统计的是每个 CPU CORE 的 SUM 值 )
TiDB CPU
TiDB → Server → CPU Usage
查看各 TiDB CPU 使用情况 (此处统计的是每个 CPU CORE 的 SUM 值 )
通常TiDB 实例与TiKV 实例均对 CPU 有一定要求,如果实例存在混部,很容易导致资源竞争,从而影响 TiDB 集群的读性能
PS. 如果 TiDB Server 与 PD 进行混部。当 TiDB CPU 很高,且当前 HOST 上的 PD 实例为 Leader ,将可能影响 PD 处理 TSO 的性能,从而影响 TiDB 集群读性能 -
解决方法
统一各服务模块的硬件配置
如 HOST 资源不满足,或者相同模块实例配置不统一,将会出现不可预测的情况。TiKV 实例尤为明显,尤其 IO 性能与 CPU 性能各 host 不统一时,会出现局部热点情况。
缩容混部的服务实例
如是实例的混部,可以参考官方文档 “混合部署拓扑” 进行配置
如果资源不满足官方推荐配置,强烈建议避免混部服务,可使用 TiUP 对实例进行 缩容操作
IO 资源不足
-
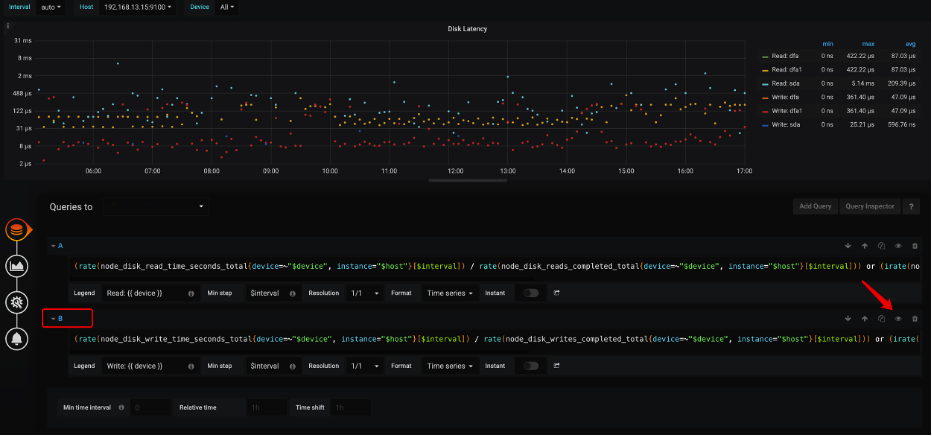
问题定位
Disk-Performance → Disk Latency 磁盘响应延迟(默认看到的是 Read Latency,需要通过 修改监控面板来展示写 Write Latency)
正常情况Latency 应小于 1ms ,不应高于 2msDisk-Performance → Disk Bandwidth 磁盘带宽
SSD 的接口协议分为 NVME 、AHCI 一般对应 PCIE 接口与 SATA 接口
PCIE 3.0 理论带宽 32Gib
SATA 3.0 理论带宽 6GiB
PS.由于各品牌和型号不一,IOPS 性能也不同这里同时给出一个 IOPS 的参考值
iofile 测试 16K chunk 顺序写与随机读性能均 ≥ 10000 IOPS -
解决方法
升级硬件
更换带宽更高的硬件设备,或者缩容混部的服务实例
如果是 PCIE 接口的 SSD ,理论上可以一台 HOST 服务器部署两个 TiKV 实例
缩容混部的服务实例
如是实例的混部,可以参考官方文档 “[混合部署拓扑] (https://docs.pingcap.com/zh/tidb/stable/hybrid-deployment-topology)” 进行配置
如果资源不满足官方推荐配置,强烈建议避免混部服务,可使用 TiUP 对实例进行 缩容操作

感谢分享