【 TiDB 使用环境】生产环境
【 TiDB 版本】5.4.1
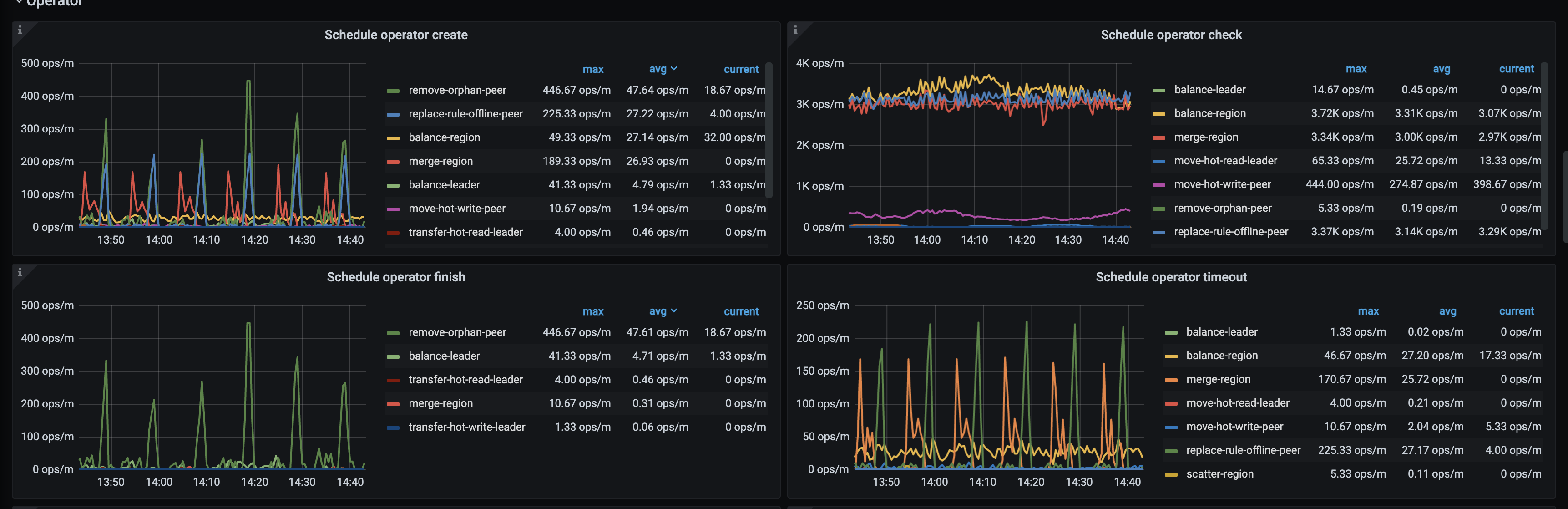
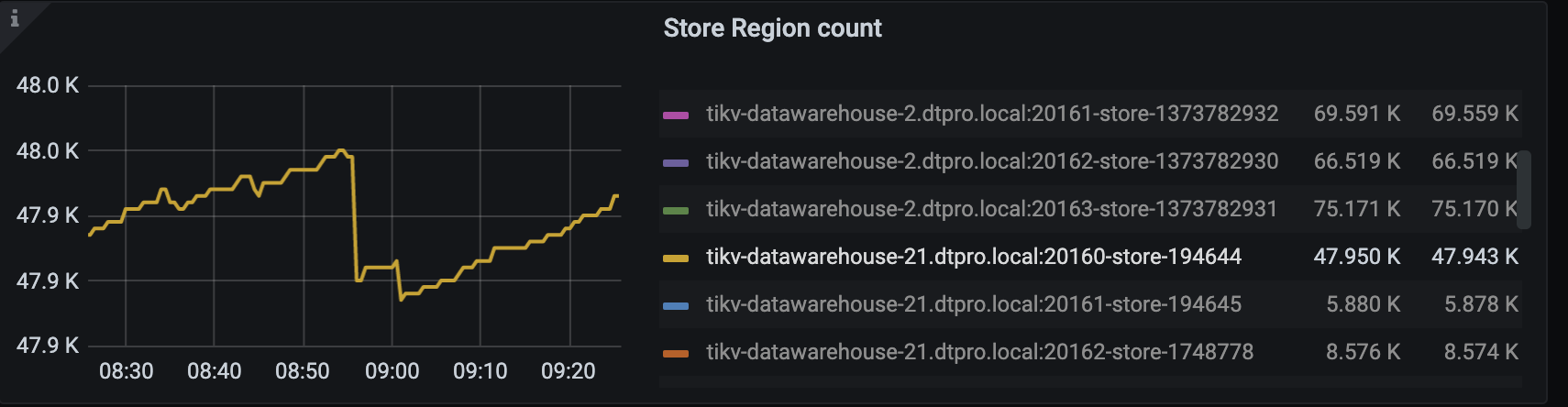
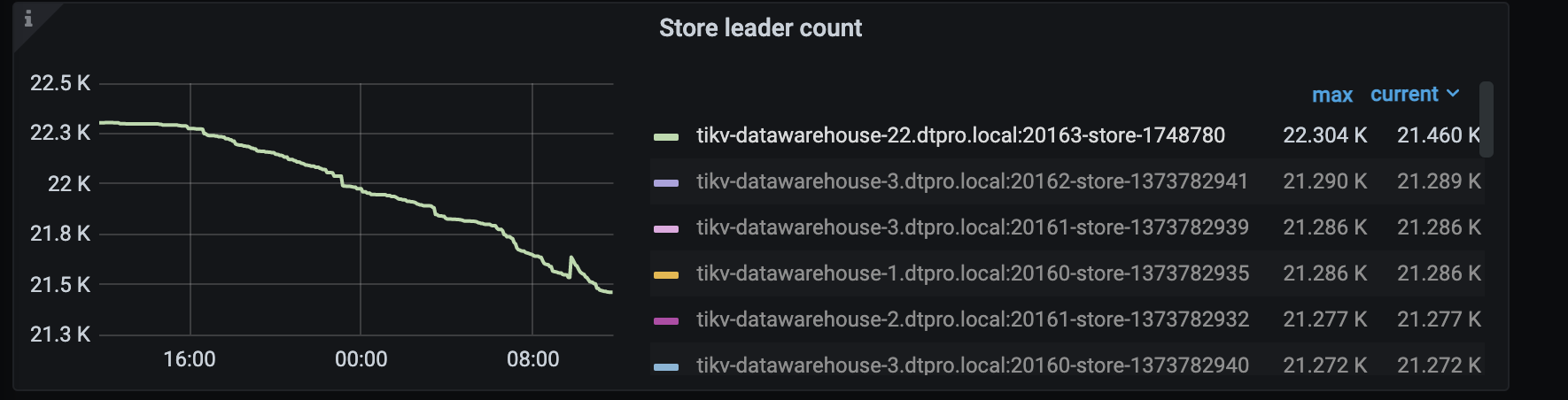
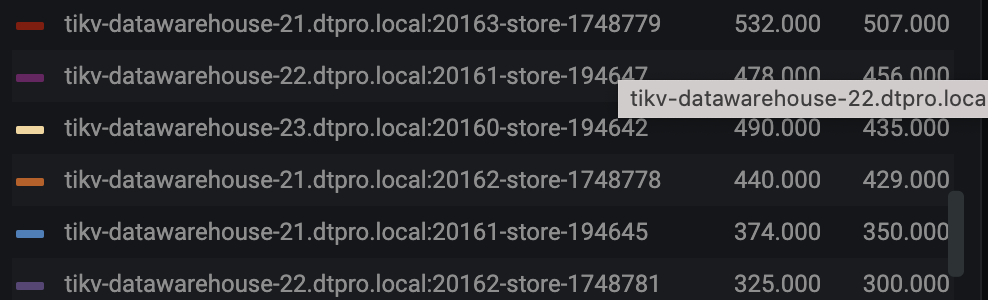
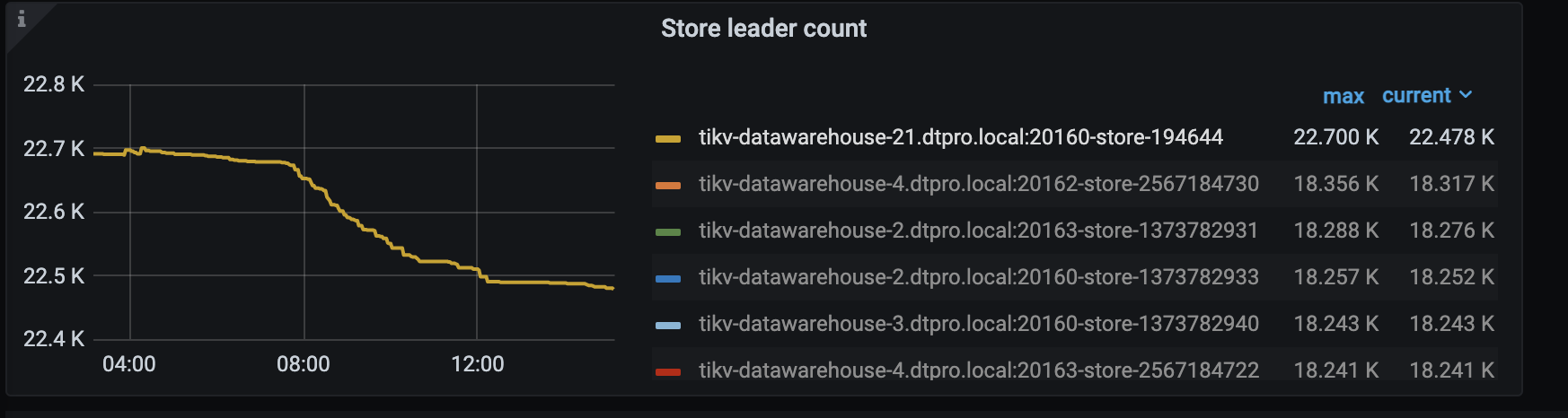
【遇到的问题】调度创建的operator(merge region、replace-rule-offline-peer)绝大部分都timeout了,集群进行了部分节点的下线,但其中一个节点的region一直没有下降。
【复现路径】
【问题现象及影响】导致下线节点的调度一直不能完成。想了解哪个参数可以调整operator的timeout时间,想调整来完成这个节点的schedule。
【附件】
【 TiDB 使用环境】生产环境
【 TiDB 版本】5.4.1
【遇到的问题】调度创建的operator(merge region、replace-rule-offline-peer)绝大部分都timeout了,集群进行了部分节点的下线,但其中一个节点的region一直没有下降。
【复现路径】
【问题现象及影响】导致下线节点的调度一直不能完成。想了解哪个参数可以调整operator的timeout时间,想调整来完成这个节点的schedule。
【附件】
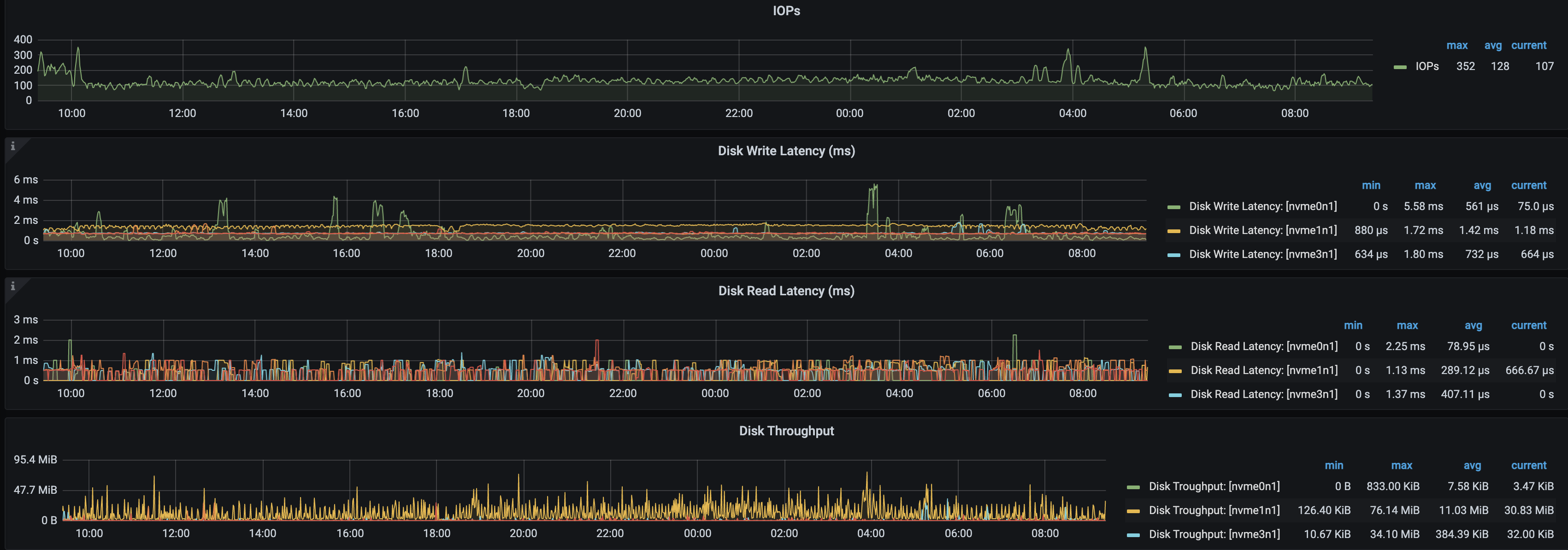
tikv 节点的资源是不是太过于繁忙了? 导致无法响应?
这个数据很稳定在大部分时间 tikv的cpu还是有剩余的。
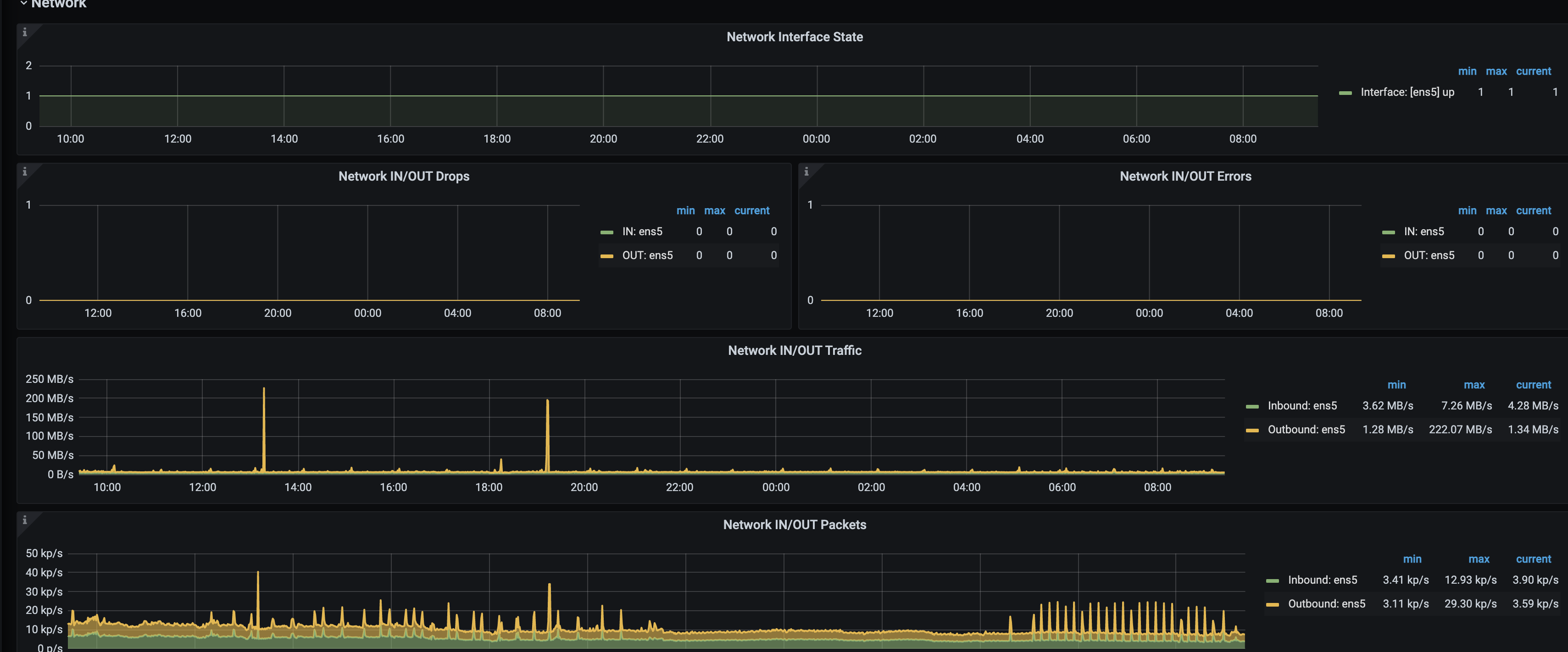
不光 CPU,磁盘,内存,网络…都是需要参考的
下线会一直不变换状态,有很多种原因,比较复杂了
比如
可以参考这个调整一下参数:
https://docs.pingcap.com/zh/tidb/stable/pd-scheduling-best-practices#节点下线速度慢
这个需要额外注意
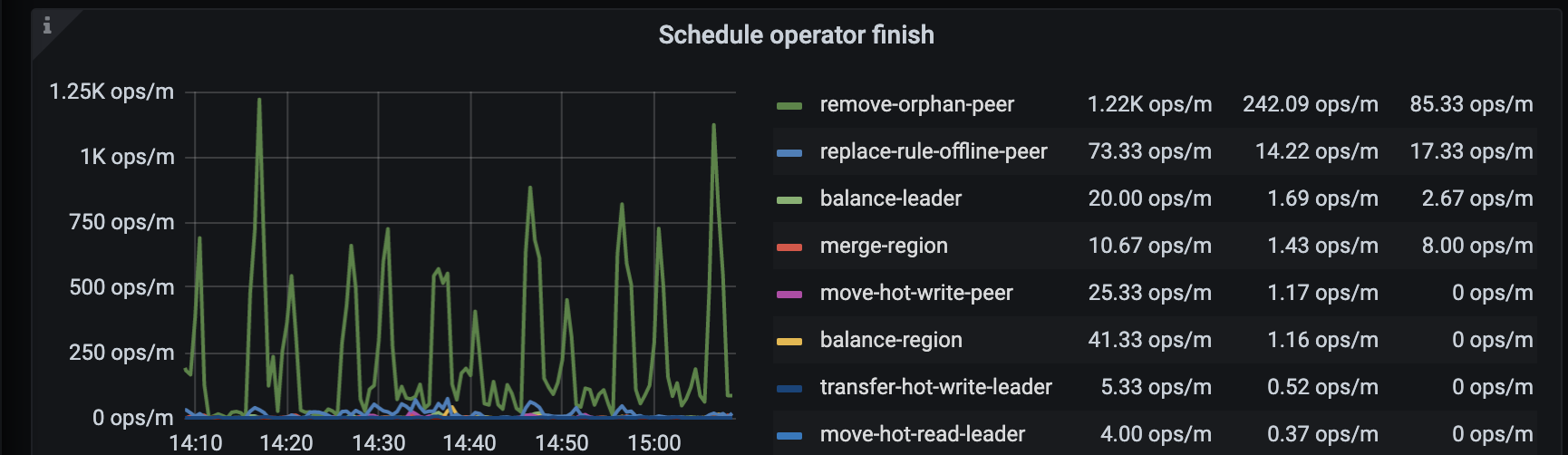
这个文档的配置我们尝试过了,现在的问题是不管limit调整到多高,大部分operator(merge region、replace-rule-offline-peer)都会timeout。
那你查一下,被下线的节点还有 region 是 leader 么? 如果没有可以强制下线试试
强制下线是指 --force 吗
是的,就是 force
tiup scale-in --force 强制/暴力下线 (不是特殊情况,不建议这么干)
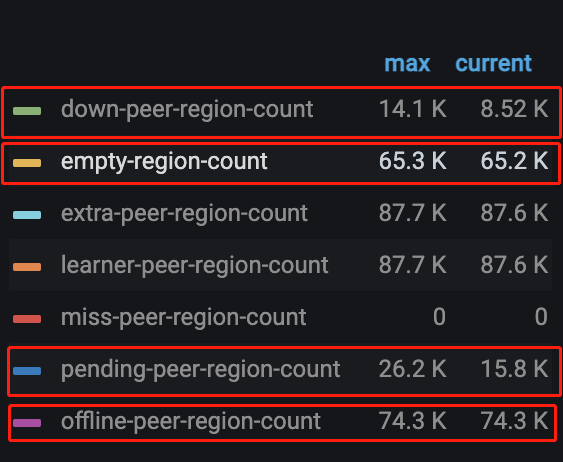
这是干嘛了…
我们更换了tikv节点,方法是先扩容再缩容。为了提高scheduler速度 就提高了一些limit参数,这些值就是提高limit后变化的。
offline-peer 就是下线的region
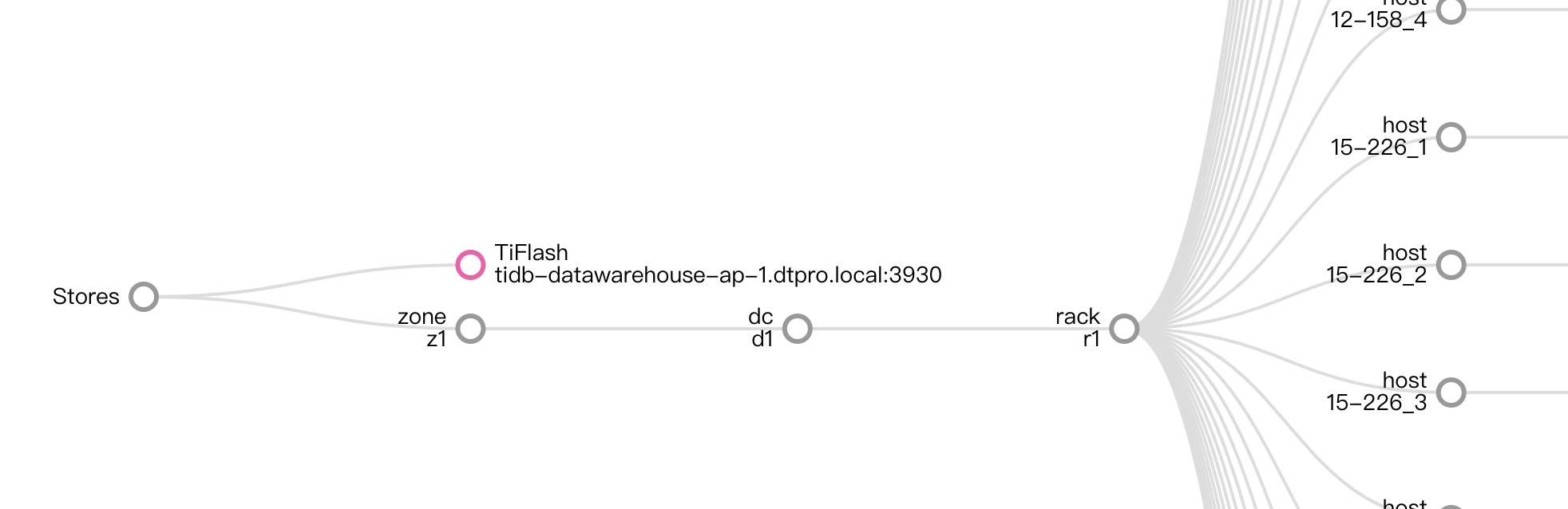
Hello~ 这个可能要看一下 palcement rule 和 label 配置,看看是否存在 label 配置不正确的问题,导致 region 不能正确调度到同一层 label 的不同域下面。
比如使用 Rack 层配置,配置 Rack1,Rack2, Rack3 但是下线的 tikv 是 Rack2 的配置,但是在 Rack2 里面没有其他 tikv 实例可以用来存储 region,导致下线的 tikv region 一直没有被调度。
在 @jingyu ma 的帮助下 调整了store limit,现在remove-orphan-peer operator的速度比较可观了。但replace-rule-offline-peer 只比之前快了一点,现在仍然很慢。具体表现是个别store 上的region下降特别慢。