【 TiDB 使用环境】生产环境
【 TiDB 版本】
5.1.2
【遇到的问题:问题现象及影响】
报错:[operator_controller.go:566] [“operator timeout”]
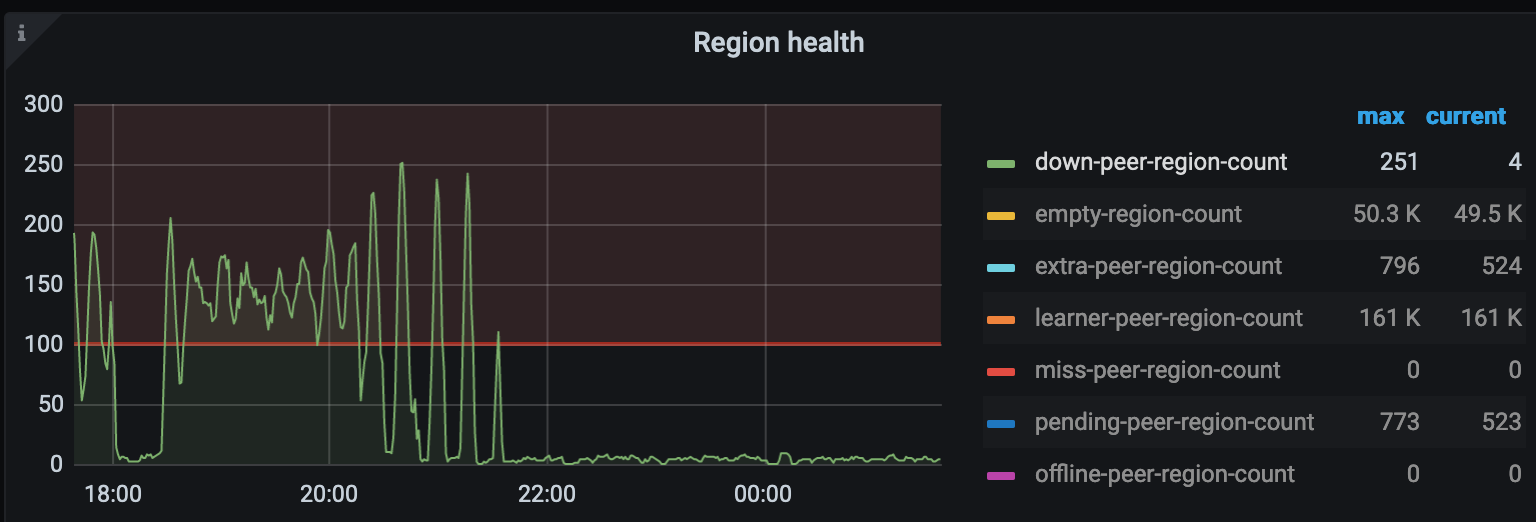
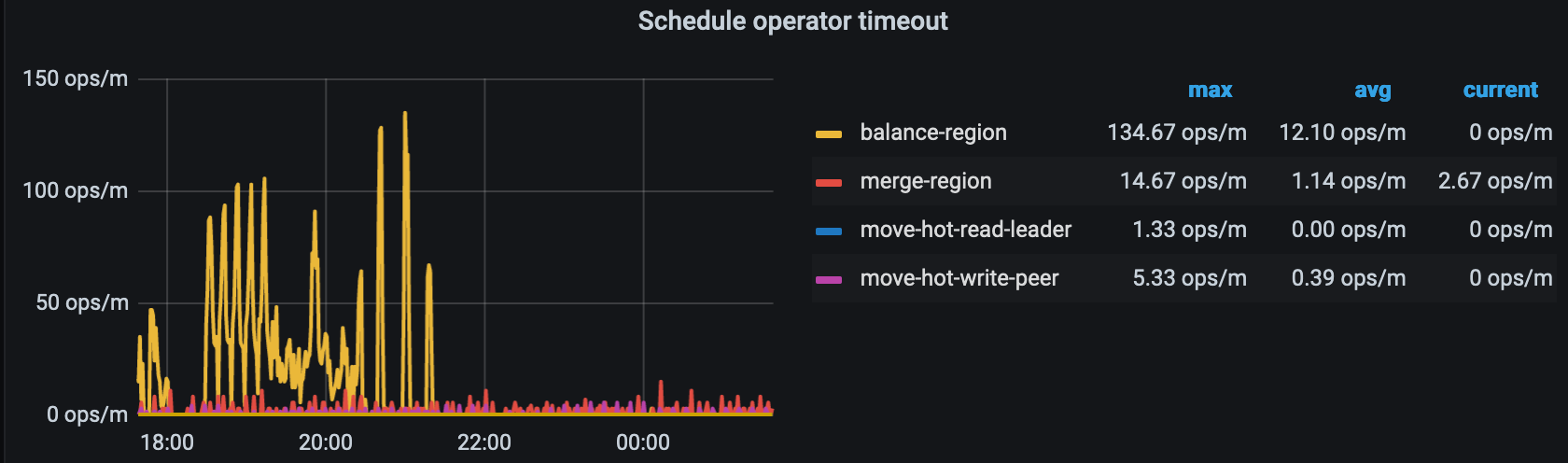
发现在region-balance过程中出现大量operator timeout

排查过DISK IO,NET,CPU无明显任何异常。


查了下异常的这批region,发现都是有varchar1024字段,类似TiDB schedule operator timeout - #20,来自 ojsl
但是我这边的数据是不允许删除的,无法通过删除这批数据恢复。目前调小下述参数,但是超时现象还是很多
- replica-schedule-limit 32
- region-schedule-limit 512
- max-snapshot-count 256
- max-pending-peer-count 256
想知道如何调大超时时间?或者哪里导致出现这个超时?
【关键日志】
pd日志
[2022/12/13 18:03:20.507 +07:00] [INFO] [operator_controller.go:566] ["operator timeout"] [region-id=34716892] [takes=10m0.583050683s] [operator="\"balance-region {mv peer: store [4] to [8]} (kind:region, region:34716892(1784,5556), createAt:2022-12-13 17:53:19.92478222 +0700 WIB m=+433284.308074027, startAt:2022-12-13 17:53:19.92485945 +0700 WIB m=+433284.308151282, currentStep:0, steps:[add learner peer 106156659 on store 8, use joint consensus, promote learner peer 106156659 on store 8 to voter, demote voter peer 34716894 on store 4 to learner, leave joint state, promote learner peer 106156659 on store 8 to voter, demote voter peer 34716894 on store 4 to learner, remove peer on store 4]) timeout\""]
store 4 tikv日志
[2022/12/13 17:53:19.689 +07:00] [INFO] [apply.rs:1370] ["execute admin command"] [command="cmd_type: ChangePeer change_peer { change_type: AddLearnerNode peer { id: 106156657 store_id: 8 role: Learner } }"] [index=22] [term=17] [peer_id=38182467] [region_id=38182463]
[2022/12/13 17:53:19.689 +07:00] [INFO] [apply.rs:1736] ["exec ConfChange"] [epoch="conf_ver: 13520 version: 2102"] [type=AddLearner] [peer_id=38182467] [region_id=38182463]
[2022/12/13 17:53:19.689 +07:00] [INFO] [apply.rs:1876] ["add learner successfully"] [region="id: 38182463 start_key: 7480000000000004FFC25F728000000099FFCDDD990000000000FA end_key: 7480000000000004FFC25F72800000009AFF242E650000000000FA region_epoch { conf_ver: 13520 version: 2102 } peers { id: 38182464 store_id: 32051340 role: Learner } peers { id: 38182465 store_id: 6 } peers { id: 38182466 store_id: 5 } peers { id: 38182467 store_id: 4 }"] [peer="id: 106156657 store_id: 8 role: Learner"] [peer_id=38182467] [region_id=38182463]
[2022/12/13 17:53:19.689 +07:00] [INFO] [raft.rs:2605] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {38182465, 38182466, 38182467} }, outgoing: Configuration { voters: {} } }, learners: {38182464, 106156657}, learners_next: {}, auto_leave: false }"] [raft_id=38182467] [region_id=38182463]
store 8 tikv 日志
[2022/12/13 17:53:19.690 +07:00] [INFO] [peer.rs:250] ["replicate peer"] [peer_id=106156657] [region_id=38182463]
[2022/12/13 17:53:19.690 +07:00] [INFO] [raft.rs:2605] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=106156657] [region_id=38182463]
[2022/12/13 17:53:19.690 +07:00] [INFO] [raft.rs:1088] ["became follower at term 0"] [term=0] [raft_id=106156657] [region_id=38182463]
[2022/12/13 17:53:19.690 +07:00] [INFO] [raft.rs:389] [newRaft] [peers="Configuration { incoming: Configuration { voters: {} }, outgoing: Configuration { voters: {} } }"] ["last term"=0] ["last index"=0] [applied=0] [commit=0] [term=0] [raft_id=106156657] [region_id=38182463]
[2022/12/13 17:53:19.690 +07:00] [INFO] [raw_node.rs:315] ["RawNode created with id 106156657."] [id=106156657] [raft_id=106156657] [region_id=38182463]
[2022/12/13 17:53:19.690 +07:00] [INFO] [raft.rs:1332] ["received a message with higher term from 38182466"] ["msg type"=MsgHeartbeat] [message_term=17] [term=0] [from=38182466] [raft_id=106156657] [region_id=38182463]
[2022/12/13 17:53:19.690 +07:00] [INFO] [raft.rs:1088] ["became follower at term 17"] [term=17] [raft_id=106156657] [region_id=38182463]