lutong
(南北有一禅)
1
三台服务器(201,202,203)组成tidb集群,每台服务器上面均部署了tibd/pd/tikv/tiflash,为了测试集群的高可用,进行断网测试:
20220831 22:36,断202服务器网络进行测试,数据库连接工具连接后,查询报Region is unavailable(haproxy的3390,单节点201:4000,203:4000端口查询均报此错误)
20220831 23:40, 断201服务器网络进行测试,数据库连接工具查询正常(haproxy的3390,单节点202:4000,203:4000端口查询均正常)
20220831 23:53,断203服务器网络进行测试,数据库连接工具查询正常(haproxy的3390,和单节点4000端口查询均正常)
20220901 0:21 全部服务器网络连上后进行测试取整体日志,数据库连接工具查询正常(haproxy的3390,和单节点4000端口查询均正常),附件是各服务器日志服务器日志20220901.rar (1.5 MB)
按照 @小王同学Plus 的建议升级到v5.4.2,还是有这个问题
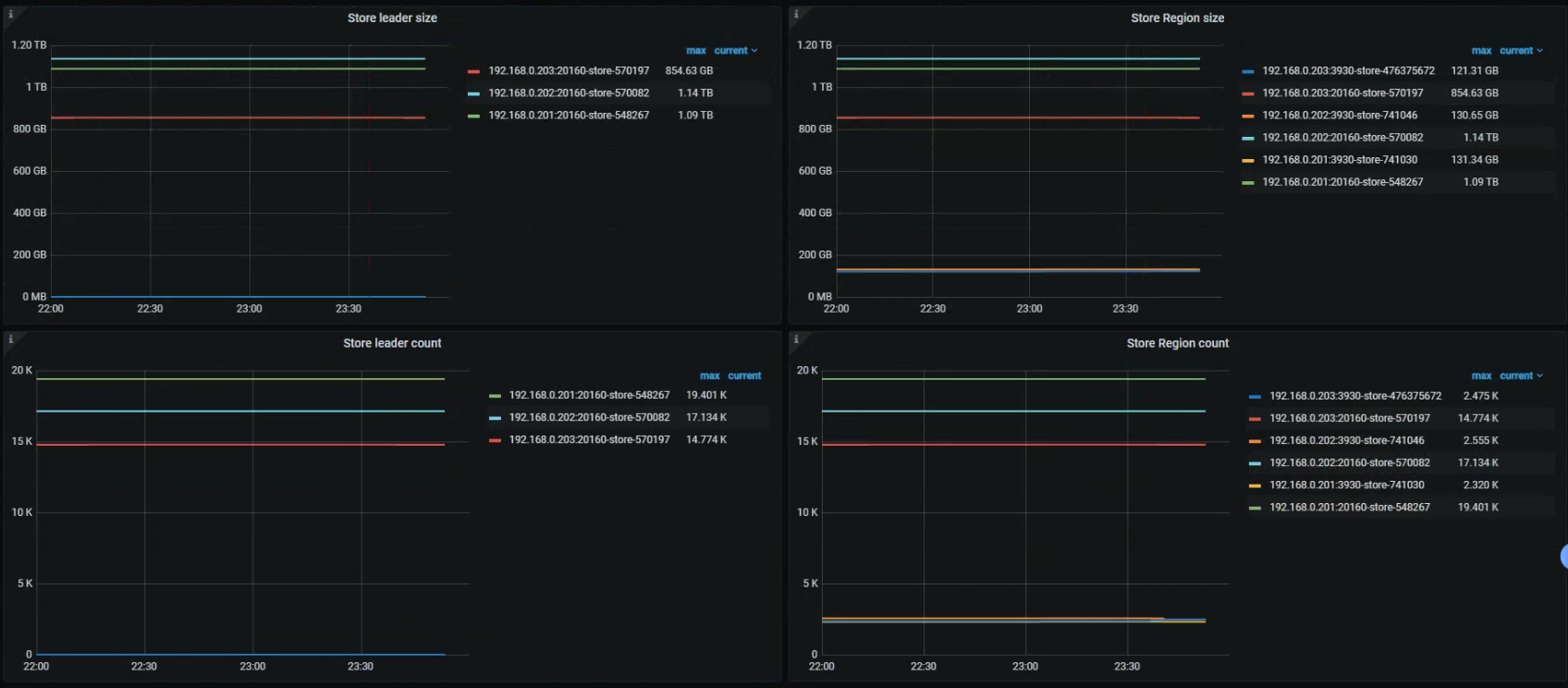
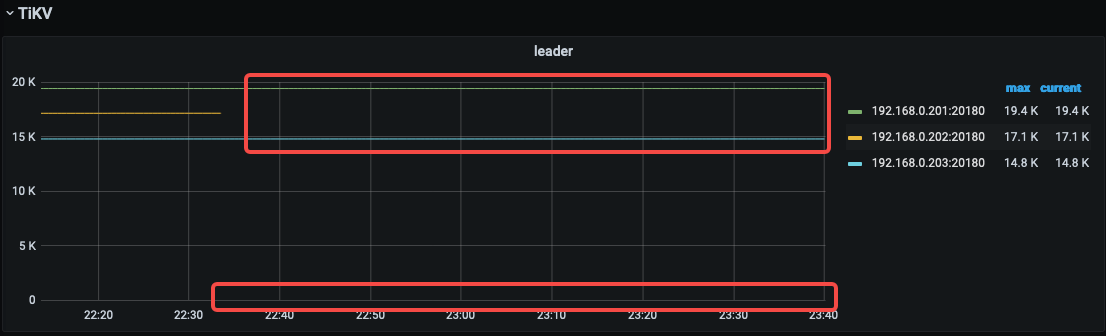
断网节点202 上应该有部分region 的leader 角色, 可以检查下段前是否有异常信息
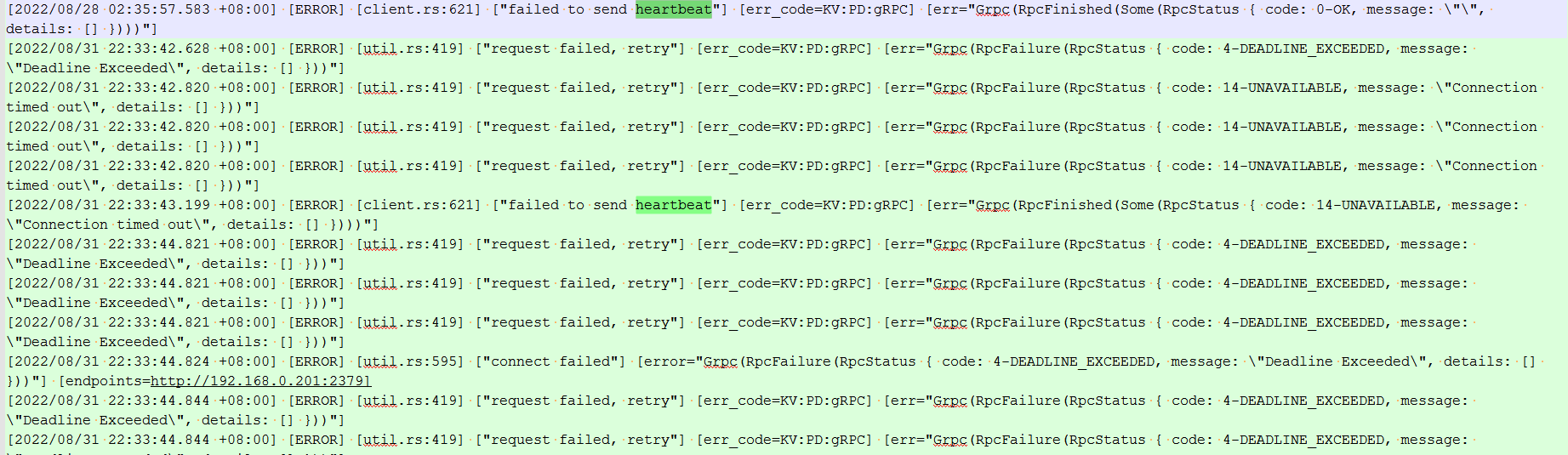
202 的kv 日志 中 28号 、31号 22:36 之前就有报错呀 ,这个节点应该断网之前就有问题
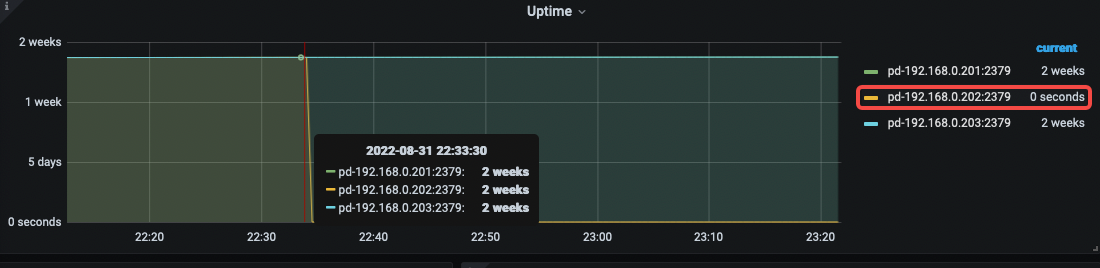
还是202 节点33分就断网了?
Aric
(Jansu Dev)
9
-
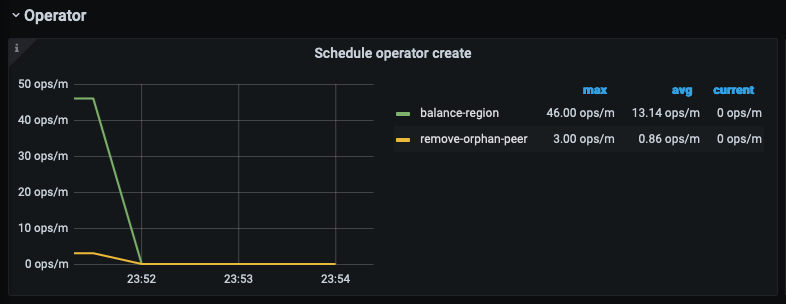
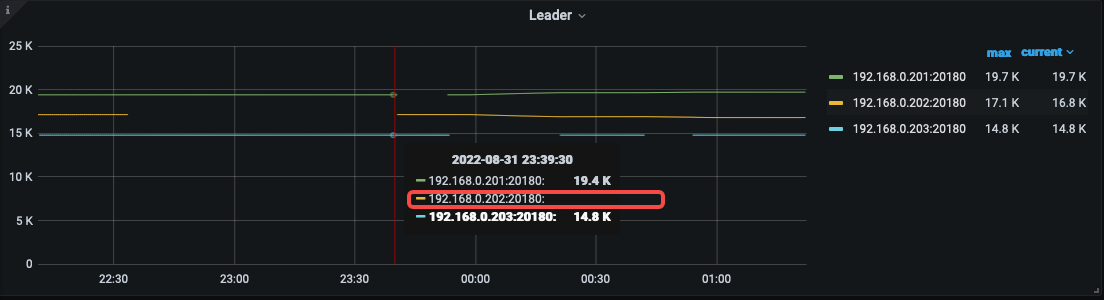
首先,再 22:33:00 左右断网,而其他 store 的 leader 却没有增长,是引发 Region is unavailable 的问题点;
-
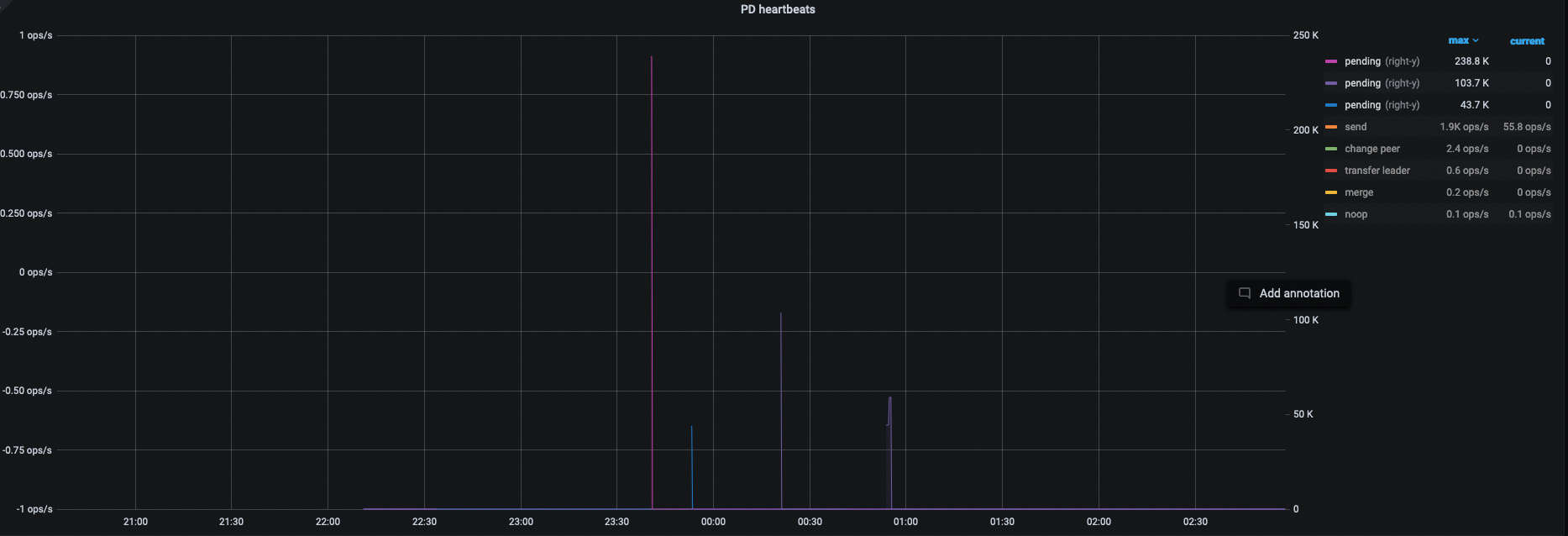
Region heartbeat report 消失预期之中,因为断网
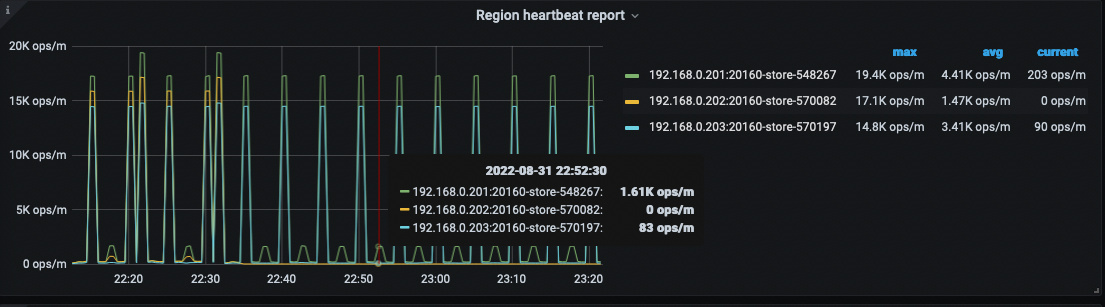
-
balance-leader operator 全无,意料之外,也是引发了 1;
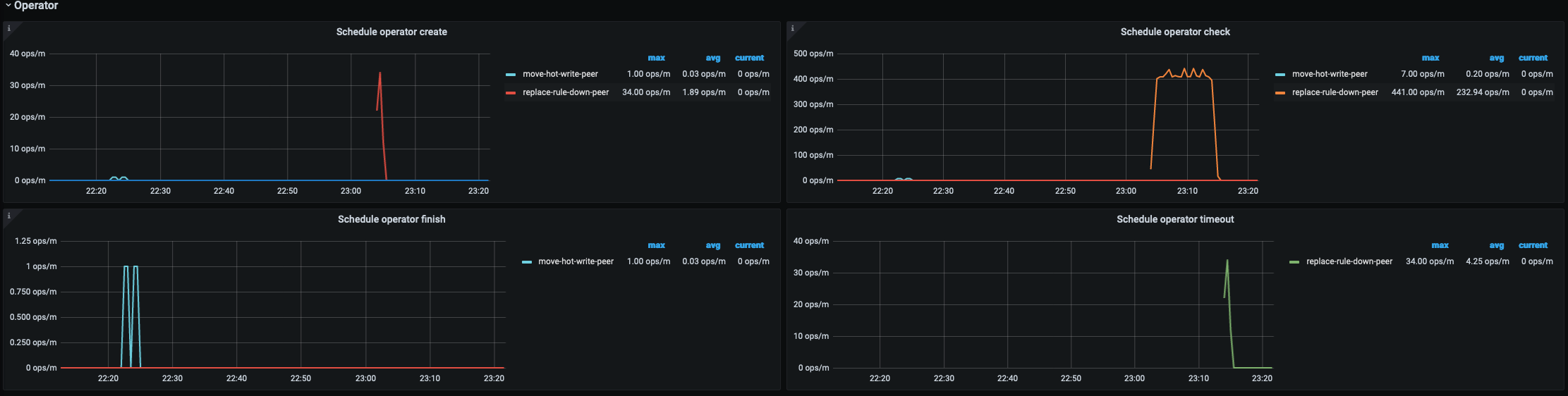
-
202 故障时间段内,PD leader 是 203,杀的也不是 PD leader

-
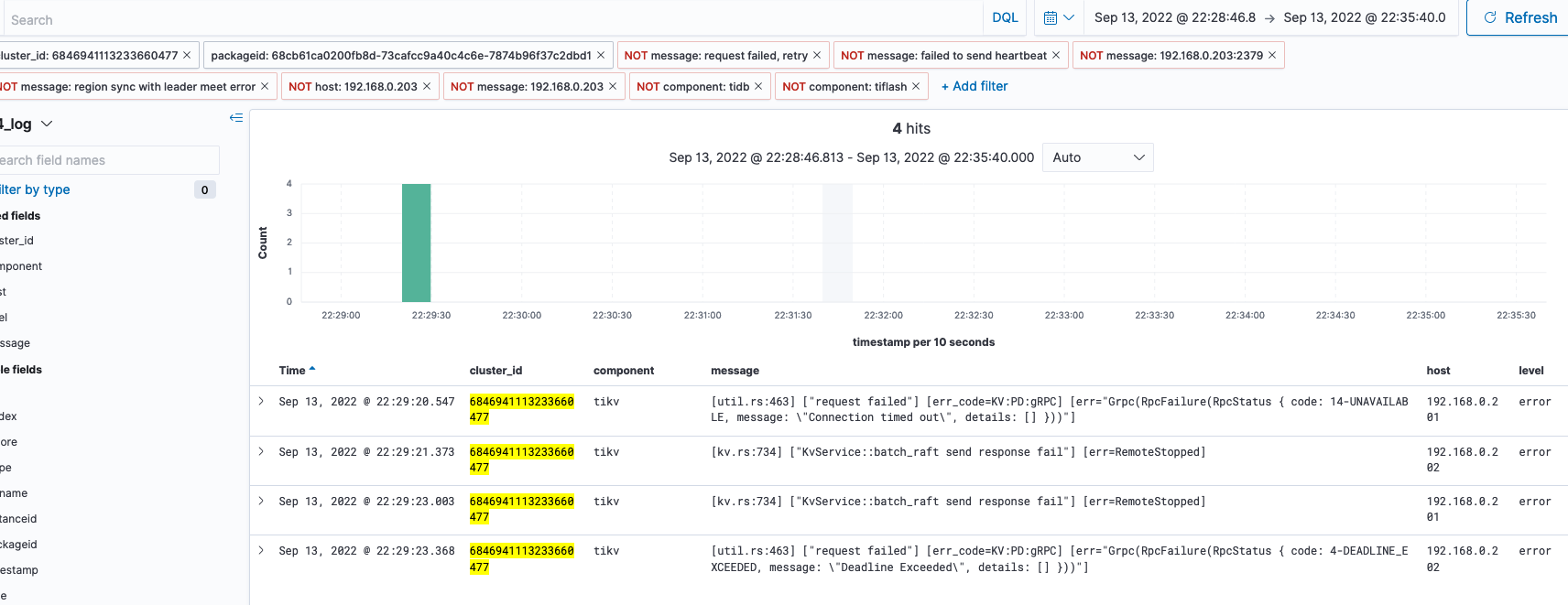
细看 log,用表达式去除一些无用日志后,内容如下,203 rpc 连自己失败了,但其实自己连自己网络应该是没问题的:

综上,应该是踩到这个 bug 了–> https://github.com/tikv/tikv/issues/12934 (此 BUG 影响 5.3 以上版本集群行为),这个 BUG 重启后会出现 Region Heartbeat Pending ,与本问题现象吻合,刚好是恢复的时间点。
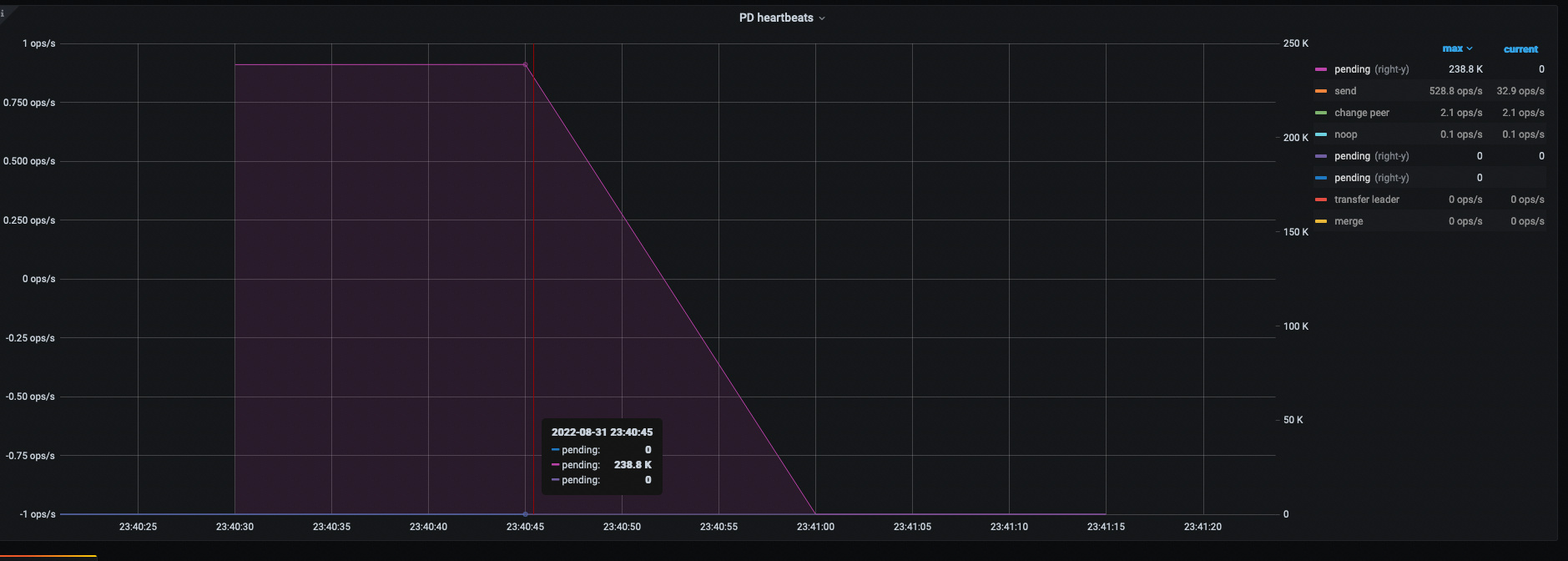
可以尝试用这个 hotfix → https://github.com/tikv/tikv/releases/tag/v5.4.2-20220802 看是否还会可复现问题。
3 个赞
Kongdom
(Kongdom)
10
Aric
(Jansu Dev)
13
clinic ,登陆账号之后(并点击提问者传的链接)就能看到了他上传的数据了。
lutong
(南北有一禅)
15
按照你说的这种方法进行了升级,升级后还是存在这种问题
Aric
(Jansu Dev)
16
新版本再来一份 clinic 吧,我手里的机器不够原样复现的。
- 是每次都是这个节点有问题吗?如果是 kill 这个节点 PD 之后就采集 clinic,避免其他信息干扰判断;
- 如果只有这一个节点有问题,可以问下网络那边,这个节点有没有什么特殊性;
- 现在奇怪的点是 kill leader 不报 region unavailable,kill 个无关紧要的 PD 反而报错,但是看监控 region 就没发生过调度;
- 如果愿意尝试,也可以试一下给他们配置 Lable 看是否会绕过(只是一种尝试,因为 region 默认不会调度到同一个 host,感觉调度这块出了什么问题);
2 个赞
lutong
(南北有一禅)
17
谢谢大佬
1、这是最新的clinic地址Download URL: https://clinic.pingcap.com.cn/portal/#/orgs/64/clusters/6846941113233660477
2、昨晚升级补丁的时候,这样执行的tiup cluster patch test-cluster /opt/tikv-5.4.2-20220802.tar.gz -R tikv
lutong
(南北有一禅)
19
Aric
(Jansu Dev)
21
-
这次看 scheduler 都正常,对了,是不是测试的时候,经常 ctrl + c 啊?这样容易残留 evict-leader-scheduler ,或者断网测试间隔太频繁;
-
pd 内部的 balance-leader 机制其实在运转,但没有产生真正的 balance leader operator
-
这次先把 evict-leader 干掉,然后检查下各个面板,均没有异常的情况下,断网(只断一台机器),然后使用下面的语句查。看时候会复现,如果可以复现,等 15min 后再查,如果还是会复现,再用下面的语句查看结果。最后,恢复网络,待集群恢复正常后,取断网前 10min,集群恢复正常后 10min 的 clinic 结果,及 trace select ..... 的几次结果。
trace select * from XXX;
顺便说下,这次的 clinic 中没有包含断网前的信息。
每次 clinic 给人的感觉都有些差异  不像是同一个问题的样子
不像是同一个问题的样子
Kongdom
(Kongdom)
22
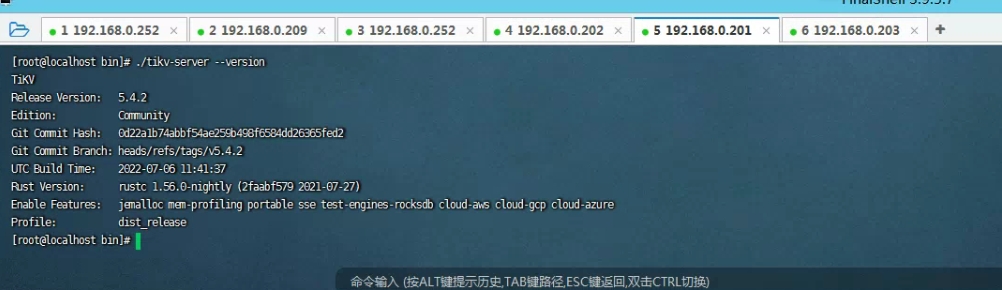
大佬,上面的version信息是对的么?上次值patch了一个节点。
Aric
(Jansu Dev)
23
对不太上,这个 PR 7 月 27 日才修,但 binary 的 build time 是 7 月 06 日;