【 TiDB 使用环境`】生产环境
【 TiDB 版本】v4.0.0
【遇到的问题】三节点混合部署,一台断网后集群不可用
【复现路径】无
【问题现象及影响】
集群包含三台服务器,每台服务器部署tidb、tikv、pd节点。
192.168.0.244 tidb+pd+tikv
192.168.0.247 tidb+pd+tikv
192.168.0.248 tidb+pd+tikv
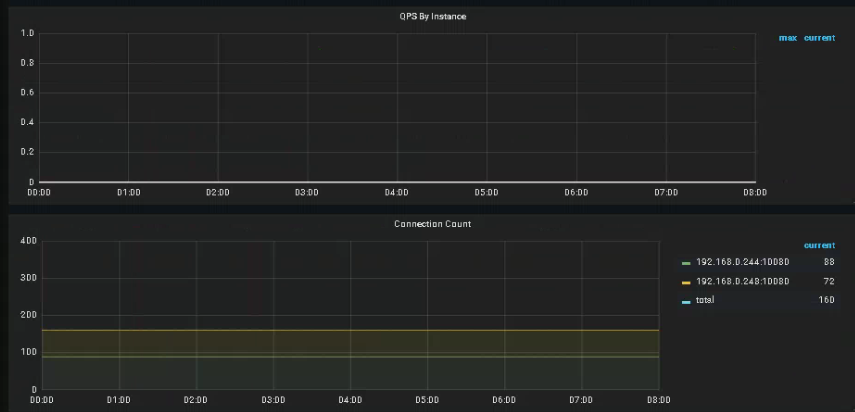
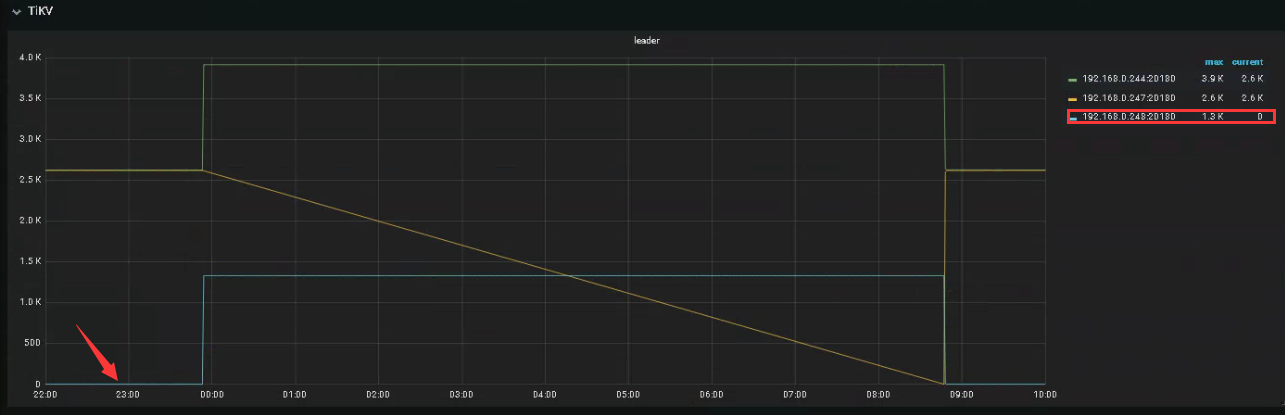
20日0点开始247服务器断网,之后整个集群不可用,检查Grafana当时leader是248,region图表如下。
奇怪的是,downpeer和region数量一致,那是否就意味着都宕掉了。
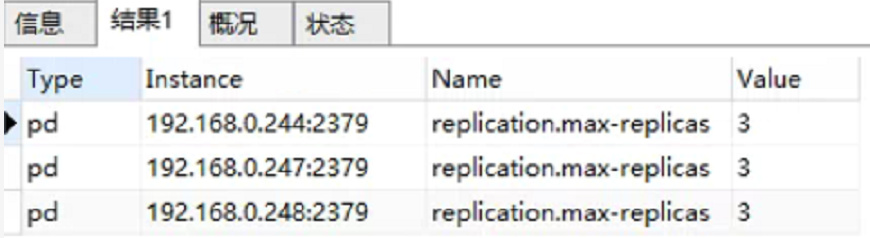
检查副本是3副本
检查pd日志,247一直在向leader发送请求,244和248没有记录。
[2022/04/19 23:52:49.395 +08:00] [ERROR] [client.go:171] [“region sync with leader meet error”] [error=“rpc error: code = Unavailable desc = transport is closing”]
[2022/04/19 23:52:54.396 +08:00] [ERROR] [client.go:163] [“server failed to establish sync stream with leader”] [server=pd_crm247] [leader=pd_crm248] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = "transport: Error while dialing dial tcp 192.168.0.248:2379: i/o timeout"”]
[2022/04/19 23:52:55.421 +08:00] [ERROR] [client.go:163] [“server failed to establish sync stream with leader”] [server=pd_crm247] [leader=pd_crm248] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = "transport: Error while dialing dial tcp 192.168.0.248:2379: connect: network is unreachable"”]
[2022/04/19 23:52:56.210 +08:00] [ERROR] [etcdutil.go:108] [“load from etcd meet error”] [error=“context deadline exceeded”]
检查tidb日志,244和248中都有类似报错
[2022/04/19 23:53:25.370 +08:00] [ERROR] [domain.go:498] [“reload schema in loop failed”] [error=“[tikv:9002]TiKV server timeout”]
三个节点宕掉一个,集群应该可以正常提供访问才对。
【附件】
pd-244.log (2.9 KB) pd-247.log (12.0 MB) pd-248.log (1.5 KB)
tidb-244.log (260.3 KB) tidb-247.log (19.7 MB) tidb-248.log (90.4 KB)