- 如果是为了测试,可以用那个地址的原代码,手动 build 个 binary 跑(安装个 rust 环境, make 一下);
- 我看了下那个链接中没有 tikv-server 的 binary,报出来这个问题是预期行为(不报反而不正常),可以手动将 build 出来的 tikv-server 替换到 {/path/deploy-path/bin/tikv-server} 中,验证是这个问题后,再找 Kongdom 老师,向 PingCAP 提个商业交付物申请吧,或者我看交流群里有人有现成的 hotfix ,如果可以直接私下要一下


tiup cluster patch {cluster-name} tikv-server.tar.gz -R tikv --overwrite
收到。我其实是想问的那个补丁包怎么打,刚才已经在群里获取到现成的了。感谢~
昨晚打完补丁后,今天中午又重新进行了断网测试,这是提取的日志https://clinic.pingcap.com.cn/portal/#/orgs/64/clusters/6846941113233660477
还是会报Region is unavailable的错误;具体:
202节点断开,连接201,203查不出数据,有报错;
201节点断开,连接202,203查不出数据,有报错;
203节点断开,连接201,202查出数据,有报错;
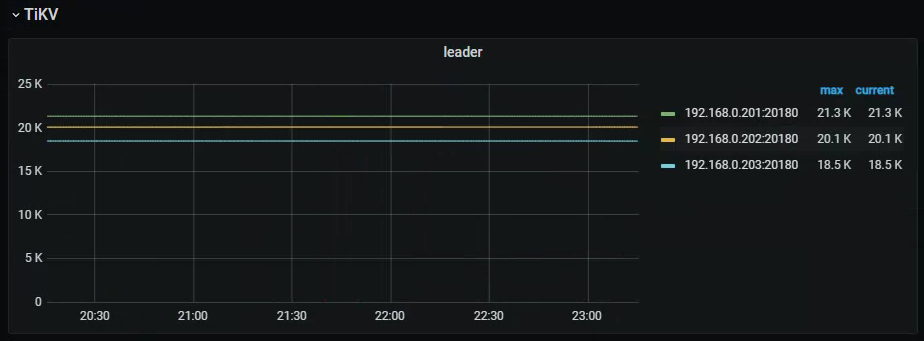
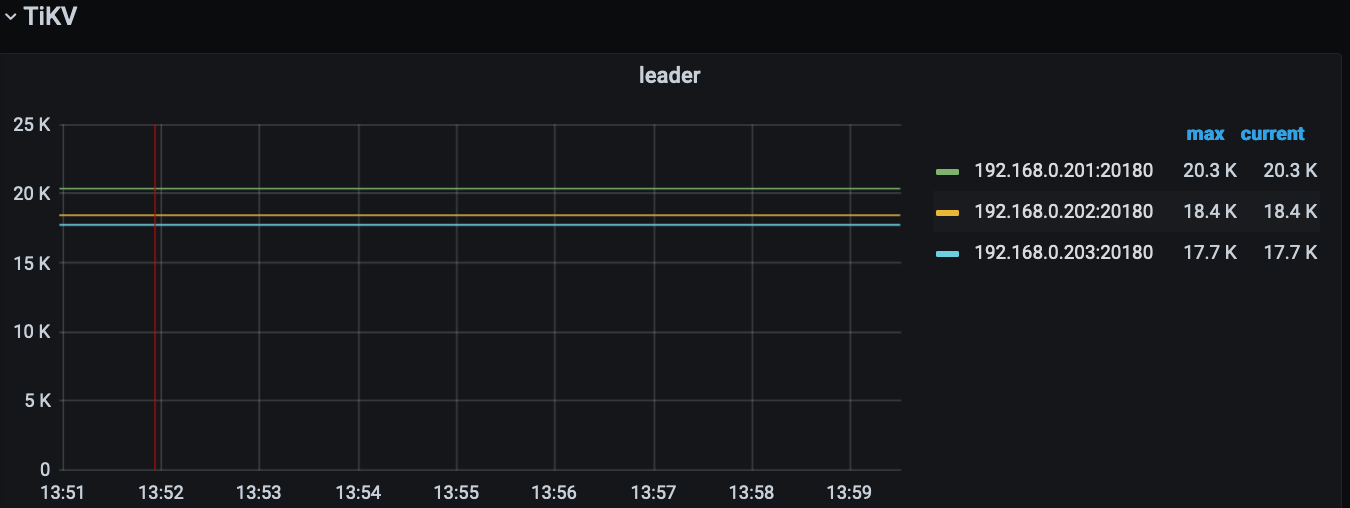
目前就看 kill 一个 node 的情况(13:54~13:59):
-
是怎么模拟的断网测试,应该不是真正的拔网线吧(下面第一张图跟以前又不同,以前的能感知到这个 tikv 根本就没有往 prometheus 里写数据的能力了),看这个时间点 tikv 的监控数据还能写到 prometheus,且网络流量还陆续的有进进出出:laughing:。 不过 pd 确实是接不到新 pd leader 的信息了。
-
第二个奇怪的点,真的有全部开到 debug log level 吗?在 tiflash 确实看到了 debug 的日志,但其他组件还是没有,像 kill pd 的这种情况 不可能不打 info 日志的啊:rofl: 。 这个是 clinic 的问题吗? 真实 log 文件中应该也没有吧?
-
看了下能查到的测试记录,相似的几乎没有🤔,要不把测试方案发我模拟下(包括怎么模拟的断网)?(不方便可以私信发)


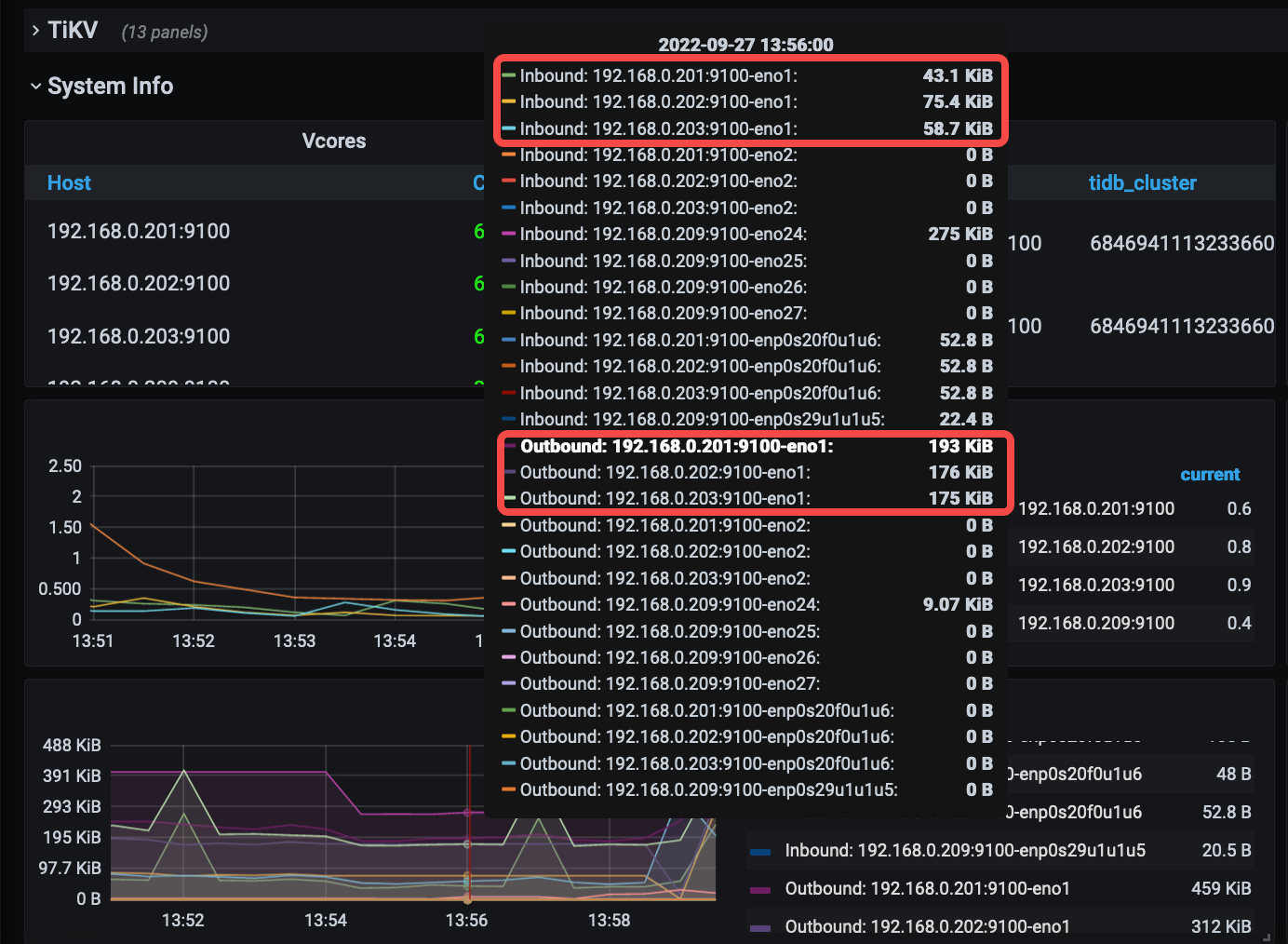
测试方案就是上面说的:
202节点服务器拔网线,连接201,203查不出数据,有报错;
201节点服务器拔网线,连接202,203查不出数据,有报错;
203节点服务器拔网线,连接201,202查出数据,有报错;
不过需要注意的是,每个节点上都有一套tidb、pd、tikv组件。
另外,操作不是我们在机房操作的,是机房值班人员操作的,所以具体怎么操作的不知道,要求是拔网线。断开第一个节点的时候,我也在看监控,当时监控根本看不出节点断开了,也很奇怪,但是查询数据确实是报错了。
借了几台机器,模拟了下,确实有问题,能稳定复现;
步骤如下,开启防火墙能模拟出来,稍等 内部交流下 给反馈;
我看了半天,暂时没发现啥~,感觉 PD 傻了:rofl:
tiup cluster deploy jan-szp-cluster v5.2.4 topology.toml -u root -p
tiup cluster start jan-szp-cluster
tiup cluster display jan-szp-cluster
tiup is checking updates for component cluster ...
Starting component `cluster`: /home/tidb/.tiup/components/cluster/v1.11.0/tiup-cluster display jan-szp-cluster
Cluster type: tidb
Cluster name: jan-szp-cluster
Cluster version: v5.2.4
Deploy user: tidb
SSH type: builtin
Dashboard URL: http://172.16.6.196:2379/dashboard
Grafana URL: http://172.16.6.196:3000
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
172.16.6.196:9093 alertmanager 172.16.6.196 9093/9094 linux/x86_64 Up /home/szp_tidb_cluster/jan/tidb-data/alertmanager-9093 /home/szp_tidb_cluster/jan/tidb-deploy/alertmanager-9093
172.16.6.196:3000 grafana 172.16.6.196 3000 linux/x86_64 Up - /home/szp_tidb_cluster/jan/tidb-deploy/grafana-3000
172.16.6.155:2379 pd 172.16.6.155 2379/2380 linux/x86_64 Up|L /home/szp_tidb_cluster/jan/tidb-data/pd-2379 /home/szp_tidb_cluster/jan/tidb-deploy/pd-2379
172.16.6.194:2379 pd 172.16.6.194 2379/2380 linux/x86_64 Up /home/szp_tidb_cluster/jan/tidb-data/pd-2379 /home/szp_tidb_cluster/jan/tidb-deploy/pd-2379
172.16.6.196:2379 pd 172.16.6.196 2379/2380 linux/x86_64 Up|UI /home/szp_tidb_cluster/jan/tidb-data/pd-2379 /home/szp_tidb_cluster/jan/tidb-deploy/pd-2379
172.16.6.196:9090 prometheus 172.16.6.196 9090 linux/x86_64 Up /home/szp_tidb_cluster/jan/tidb-data/prometheus-9090 /home/szp_tidb_cluster/jan/tidb-deploy/prometheus-9090
172.16.6.155:4000 tidb 172.16.6.155 4000/10080 linux/x86_64 Up - /home/szp_tidb_cluster/jan/tidb-deploy/tidb-4000
172.16.6.194:4000 tidb 172.16.6.194 4000/10080 linux/x86_64 Up - /home/szp_tidb_cluster/jan/tidb-deploy/tidb-4000
172.16.6.196:4000 tidb 172.16.6.196 4000/10080 linux/x86_64 Up - /home/szp_tidb_cluster/jan/tidb-deploy/tidb-4000
172.16.6.155:9000 tiflash 172.16.6.155 9000/8123/3930/20170/20292/8234 linux/x86_64 Up /home/szp_tidb_cluster/jan/tidb-data/tiflash-9000 /home/szp_tidb_cluster/jan/tidb-deploy/tiflash-9000
172.16.6.194:9000 tiflash 172.16.6.194 9000/8123/3930/20170/20292/8234 linux/x86_64 Up /home/szp_tidb_cluster/jan/tidb-data/tiflash-9000 /home/szp_tidb_cluster/jan/tidb-deploy/tiflash-9000
172.16.6.196:9000 tiflash 172.16.6.196 9000/8123/3930/20170/20292/8234 linux/x86_64 Up /home/szp_tidb_cluster/jan/tidb-data/tiflash-9000 /home/szp_tidb_cluster/jan/tidb-deploy/tiflash-9000
172.16.6.155:20160 tikv 172.16.6.155 20160/20180 linux/x86_64 Up /home/szp_tidb_cluster/jan/tidb-data/tikv-20160 /home/szp_tidb_cluster/jan/tidb-deploy/tikv-20160
172.16.6.194:20160 tikv 172.16.6.194 20160/20180 linux/x86_64 Up /home/szp_tidb_cluster/jan/tidb-data/tikv-20160 /home/szp_tidb_cluster/jan/tidb-deploy/tikv-20160
172.16.6.196:20160 tikv 172.16.6.196 20160/20180 linux/x86_64 Up /home/szp_tidb_cluster/jan/tidb-data/tikv-20160 /home/szp_tidb_cluster/jan/tidb-deploy/tikv-20160
alter table test.sbtest1 set TIFLASH REPLICA 1;
alter table test.sbtest2 set TIFLASH REPLICA 1;
alter table test.sbtest3 set TIFLASH REPLICA 1;
alter table test.sbtest4 set TIFLASH REPLICA 1;
alter table test.sbtest5 set TIFLASH REPLICA 1;
alter table test.sbtest6 set TIFLASH REPLICA 1;
alter table test.sbtest7 set TIFLASH REPLICA 1;
alter table test.sbtest8 set TIFLASH REPLICA 1;
alter table test.sbtest9 set TIFLASH REPLICA 1;
alter table test.sbtest10 set TIFLASH REPLICA 1;
sysbench oltp_read_write --mysql-host=127.0.0.1 --mysql-port=4000 --mysql-db=test --mysql-user=root --mysql-password= --table_size=5000 --tables=50 prepare
mysql>SELECT * FROM information_schema.tiflash_replica;
+--------------+------------+----------+---------------+-----------------+-----------+----------+
| TABLE_SCHEMA | TABLE_NAME | TABLE_ID | REPLICA_COUNT | LOCATION_LABELS | AVAILABLE | PROGRESS |
+--------------+------------+----------+---------------+-----------------+-----------+----------+
| test | sbtest8 | 74 | 1 | | 1 | 1 |
| test | sbtest4 | 62 | 1 | | 1 | 1 |
| test | sbtest7 | 71 | 1 | | 1 | 1 |
| test | sbtest1 | 53 | 1 | | 1 | 1 |
| test | sbtest2 | 56 | 1 | | 1 | 1 |
| test | sbtest5 | 65 | 1 | | 1 | 1 |
| test | sbtest3 | 59 | 1 | | 1 | 1 |
| test | sbtest6 | 68 | 1 | | 1 | 1 |
| test | sbtest10 | 80 | 1 | | 1 | 1 |
| test | sbtest9 | 77 | 1 | | 1 | 1 |
+--------------+------------+----------+---------------+-----------------+-----------+----------+
+------------------------------+---------+---------+-------------------+---------------+---------------------------------------------------------------------------------------------------------------------------
| id | estRows | actRows | task | access object | execution info
+------------------------------+---------+---------+-------------------+---------------+---------------------------------------------------------------------------------------------------------------------------
| HashAgg_23 | 1.00 | 1 | root | | time:5.52ms, loops:2, partial_worker:{wall_time:5.473661ms, concurrency:5, task_num:1, tot_wait:27.163385ms, tot_exec:4.78
| └─TableReader_25 | 1.00 | 1 | root | | time:5.36ms, loops:2, cop_task: {num: 1, max: 0s, proc_keys: 0, copr_cache_hit_ratio: 0.00}
| └─ExchangeSender_24 | 1.00 | 1 | batchCop[tiflash] | | tiflash_task:{time:3.78ms, loops:1, threads:1}
| └─HashAgg_8 | 1.00 | 1 | batchCop[tiflash] | | tiflash_task:{time:3.78ms, loops:1, threads:1}
| └─TableFullScan_22 | 5000.00 | 5000 | batchCop[tiflash] | table:sbtest1 | tiflash_task:{time:3.78ms, loops:1, threads:1}
+------------------------------+---------+---------+-------------------+---------------+---------------------------------------------------------------------------------------------------------------------------
[root@bj-az1-155 ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
[root@bj-az1-155 ~]# systemctl start firewalld
[root@bj-az1-155 ~]# date
Sat Oct 8 00:21:35 CST 2022
[root@bj-az1-155 ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: active (running) since Sat 2022-10-08 00:21:26 CST; 24s ago
Docs: man:firewalld(1)
Main PID: 13095 (firewalld)
CGroup: /system.slice/firewalld.service
└─13095 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid
[root@bj-az1-155 ~]# firewall-cmd --list-ports
# 空,即:没有开放的端口
[root@bj-az1-155 ~]#
mysql> select * from test.sbtest7;
ERROR 9012 (HY000): TiFlash server timeout
mysql> select /*+ READ_FROM_STORAGE(TIKV[sbtest7]]) */ * from test.sbtest7;
ERROR 9005 (HY000): Region is unavailable
#######################################################################
## 至此复现问题
感谢老师国庆加班测试~申请给老师加个鸡腿![]() ~
~
问题一
mysql> select * from test.sbtest7;ERROR 9012 (HY000): TiFlash server timeout
因为只添加了一个 tiflash 副本,因为断网的那台机器上的 tiflash region 连不上,所以 server timeout 符合预期,想要规避这种现象,可以添加两个 tiflash 副本进行验证。
问题 二
select /*+ READ_FROM_STORAGE(TIKV[sbtest7]]) */ * from test.sbtest7;ERROR 9005 (HY000): Region is unavailable
- 如果删除的副本所在 leader 正好在这台断网的机器上,因为 raft 要 2-10 s 之后才会重新选主,所以那一瞬间会爆 region is unavailable. 另外还有一个问题是,这台机器断网后,如果需要选主的 region 特别多,这会儿可能会卡,但是最终都会选主 region leader, 恢复正常查询。
但是在 raft 重新选主后,就可以查到结果了,在测试机器上已经复现:
mysql> select /+ READ_FROM_STORAGE(tikv[sbtest7]) / count() from sbtest7;
±---------+
| count() |
±---------+
| 5000 |
±---------+
1 row in set (0.01 sec)
所以是不是等待时间太短,还没来得及选主?等个几分钟看看有没有类似的错误?
另外,需要注意的一点是, 在 leader 所在节点断网后,pd 虽然会发现,但是选主的操作是 tikv 进行的。如果遇到静默 region, 选主的操作则会等待更久。
向 Aunt-Shirly 老师请教了下,引发 Region is unavailable 的主要原因应该是 老师说的 raft 要 2-10 s 之后才会重新选主,看了下你这边的集群数据量好像是几十 TB(region 更多),等的时间可能更长。我的数据量较少,恢复的快些。

![]() 感谢老师的回复
感谢老师的回复
那这个问题就是和数据量、硬件有关,在数据量较大,硬件不够时,表现的特别明显?
通过哪个监控视图可以确认raft重新选主完成?
其实我们做这个测试主要是为了验证高可用,期望是无感的,但现在看来还是由于硬件资源问题,导致出现空白期。之前低版本的PD Leader切换也出现过类似情况。
Hello,因为问题前面断网我看是一会断这台,恢复,断另一台,再恢复,这种情况下分析引入条件比较多,分析起来也比较复杂,而且也不是特别贴近我们的实际应用场景。所以我们这边暂不分析。
我们只说三副本情况下,能够保证剩余幅本数 >=2 的情况(即保证多数副本可用的情况),如果忽然有一台(机房)断网了,这边主要涉及两个地方重新选主:
- 如果切掉的正好是 pd-leader 所在机器,则 PD 需要重新选主,这个时间大概是 15 s 左右能够完成。
- 对于那些 leader 在断网上的 region, 剩下的两个副本会发现自己没有 leader, 重新开始选举。其中 发现自己没有 leader 的时间大概是 2-8s, 重新选举出 leader 的时间是个概率值,内部大部分测试下来体感应该是在分钟级以内。
关于我们的监控:
确保监控服务未断网的情况下,理论上监控数据是应该能够和上述结论一致,即:
- pd 监控上能大概 20 s 内能看到 leader 切换完成。
- tikv 监控中 leader 相关页面未断网节点在半分钟后 leader 个数开始上涨。这些数据代表着对应 region 的选主完成。
![]() 收到,感谢老师。那我们再按这个方案测试一下,某一节点断网下集群可用情况。
收到,感谢老师。那我们再按这个方案测试一下,某一节点断网下集群可用情况。
嗯嗯,另外特别注意的是,监控节点不要部署在断网那台机器上,会导致其他实例无法上报监控信息导致监控不准确。
好的。我们的grafana、prometheus是在另外一台单独服务器上。