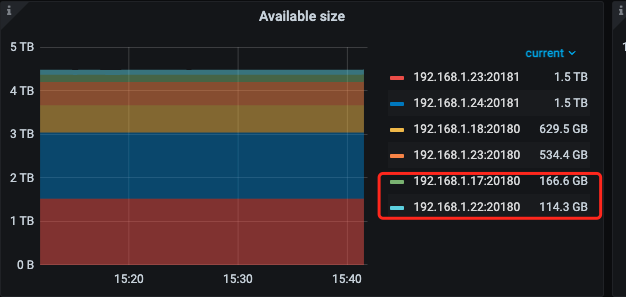
【 TiDB 集群 】
- PD :3个
- TiDB:2个
- TIkV:5个(原来)=> 7个(扩容后)
【 TiDB 版本】
- v5.1.1
【操作步骤】
1、因为有个 TiKV 节点(24)有问题,所以把它手动 stop 掉了,状态是 DOWN
2、在 23、24 两个机器扩容多两个 tikv 实例
3、缩容有问题的 TiKV 节点(24),状态是 Pending Offline
4、display 集群情况
192.168.1.17:20160 tikv linux/x86_64 Up
192.168.1.18:20160 tikv linux/x86_64 Up
192.168.1.22:20160 tikv linux/x86_64 Up
192.168.1.23:20160 tikv linux/x86_64 Up
192.168.1.23:20161 tikv linux/x86_64 Up(扩容)
192.168.1.24:20160 tikv linux/x86_64 Pending Offline(缩容)
192.168.1.24:20161 tikv linux/x86_64 Up(扩容)
【遇到的问题】
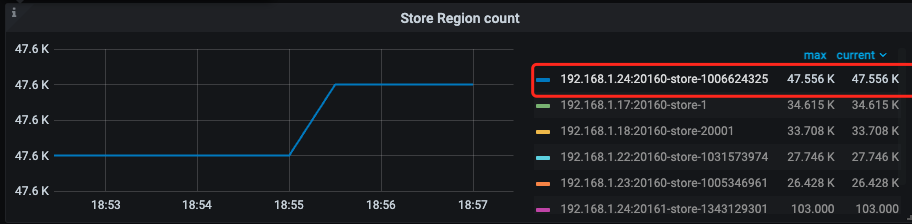
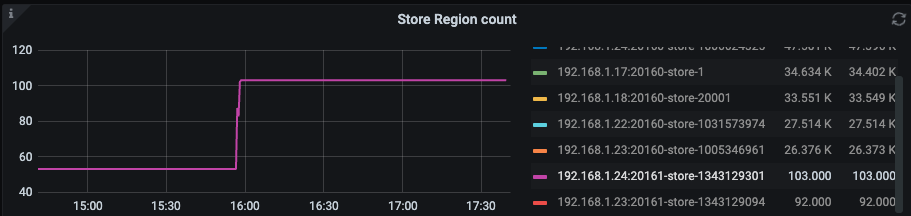
1、刚扩容的时候是有在 blance region 的,后面突然就停了

2、region count 也是上不去
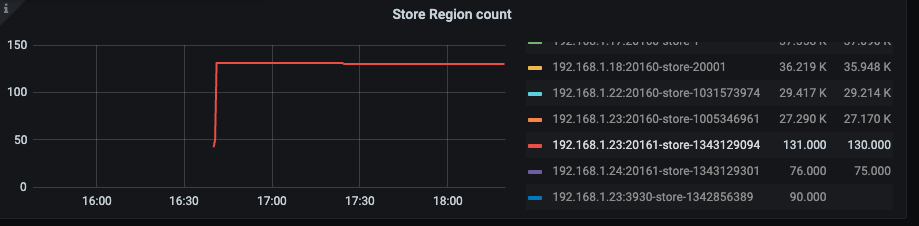
【处理方法】
我根据以下文档去操作
- https://docs.pingcap.com/zh/tidb/v5.1/pd-scheduling-best-practices#leaderregion-分布不均衡
- 【SOP 系列 19】region 分布不均问题排查及解决不完全指南
一、store 打分
新扩容的节点分数较低,合理
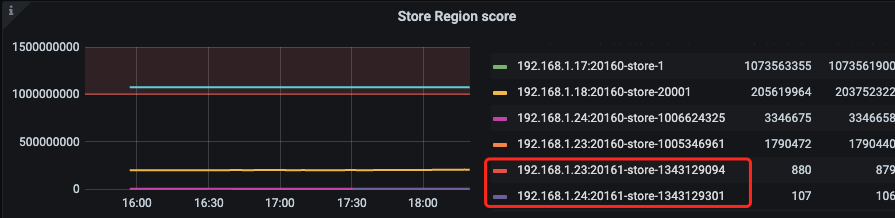
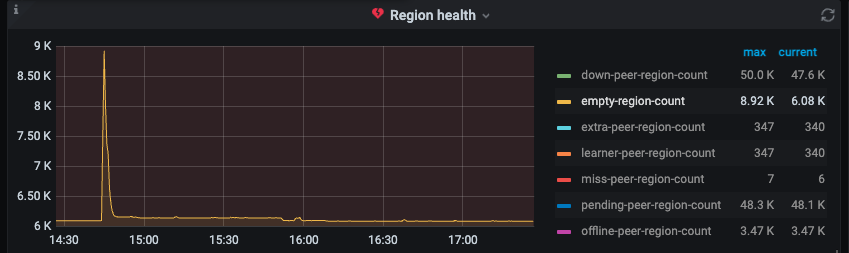
二、排查空 region 或者小 region
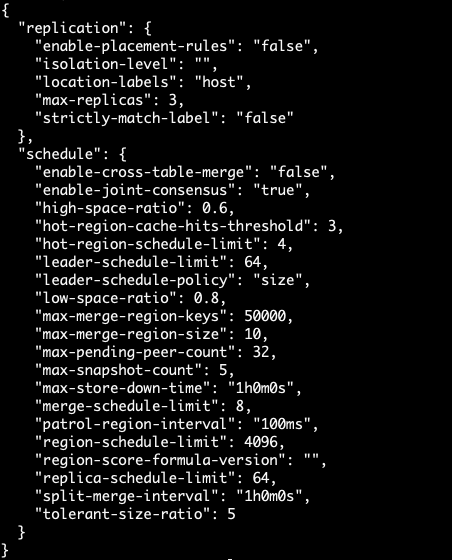
开启了 region merge ,并且调大了这些值
"max-merge-region-keys": 50000,
"max-merge-region-size": 10,
但是空 region 还是很多
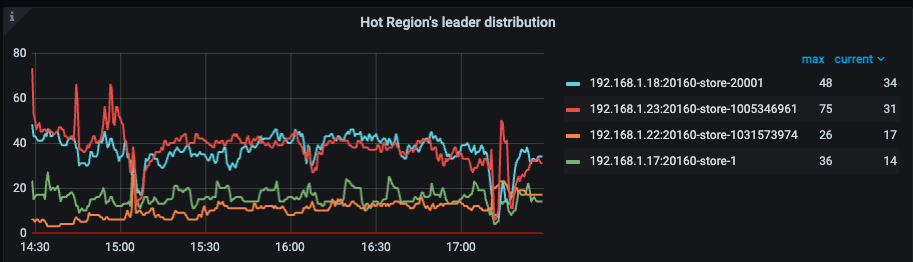
三、热点负载问题
- 写热点
- 读热点
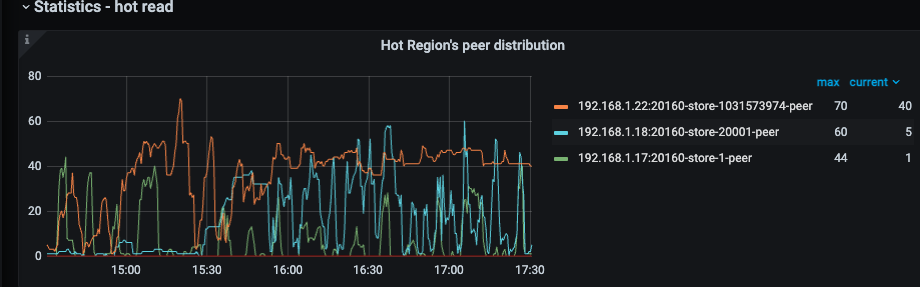
没有明显的热点问题
四、调整 leader-weight 和 region-weight
1、在新扩容的两个节点调整权重 leader = 1 ,region = 2
{"id":1343129094,"address":"192.168.1.23:20161","state_name":"Up","capacity":"1.455TiB","available":"1.381TiB","used_size":"190.3MiB","region_count":92,"region_size":841,"leader_count":52,"leader_size":544,"region_weight":2,"leader_weight":1}
{"id":1343129301,"address":"192.168.1.24:20161","state_name":"Up","capacity":"1.455TiB","available":"1.381TiB","used_size":"1007MiB","region_count":103,"region_size":4232,"leader_count":67,"leader_size":3101,"region_weight":2,"leader_weight":1}
2、刚调整的时候 balance 了一会,突然又不行了!
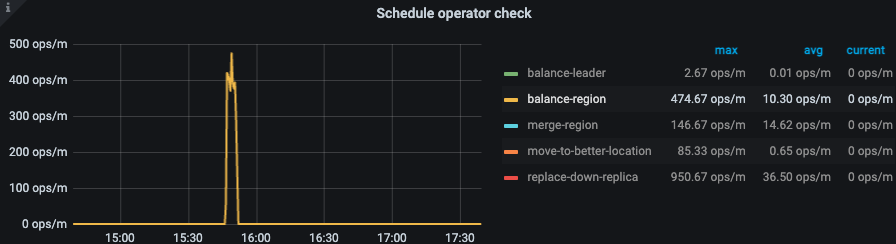
五、排查 operator 调度的问题
1、调整调度的参数
2、怀疑是原来 24 TIKV 节点缩容占用资源,所以把 offline 也关掉了
config set disable-replace-offline-replica true
3、cpu 使用情况还好,都是很高配置的服务器

4、调度器正常

【疑问】
现在的情况是上线新节点不行,下线旧的节点也不行,请问有什么办法解决吗,以上推荐的方法都已经排查过了,不知道还有没有什么漏洞没有排查,希望大神们帮忙看看!