感觉scheduler没干活,看一下配置呢
tiup ctl:v5.1.1 pd config show schedule --pd <PD_IP>:2379
好的,麻烦帮忙看下
{
"max-snapshot-count": 5,
"max-pending-peer-count": 32,
"max-merge-region-size": 10,
"max-merge-region-keys": 50000,
"split-merge-interval": "1h0m0s",
"enable-one-way-merge": "false",
"enable-cross-table-merge": "true",
"patrol-region-interval": "100ms",
"max-store-down-time": "1h0m0s",
"leader-schedule-limit": 64,
"leader-schedule-policy": "size",
"region-schedule-limit": 4096,
"replica-schedule-limit": 64,
"merge-schedule-limit": 8,
"hot-region-schedule-limit": 4,
"hot-region-cache-hits-threshold": 3,
"store-limit": {
"1": {
"add-peer": 1000,
"remove-peer": 1000
},
"1004812736": {
"add-peer": 1000,
"remove-peer": 1000
},
"1005346961": {
"add-peer": 1000,
"remove-peer": 1000
},
"1006624325": {
"add-peer": 1000,
"remove-peer": 1000
},
"1031573974": {
"add-peer": 1000,
"remove-peer": 1000
},
"1343129094": {
"add-peer": 1000,
"remove-peer": 1000
},
"1343129301": {
"add-peer": 1000,
"remove-peer": 1000
},
"20001": {
"add-peer": 1000,
"remove-peer": 1000
}
},
"tolerant-size-ratio": 5,
"low-space-ratio": 0.8,
"high-space-ratio": 0.6,
"region-score-formula-version": "",
"scheduler-max-waiting-operator": 3,
"enable-remove-down-replica": "true",
"enable-replace-offline-replica": "true",
"enable-make-up-replica": "true",
"enable-remove-extra-replica": "true",
"enable-location-replacement": "true",
"enable-debug-metrics": "false",
"enable-joint-consensus": "true",
"schedulers-v2": [
{
"type": "balance-region",
"args": null,
"disable": false,
"args-payload": ""
},
{
"type": "balance-leader",
"args": null,
"disable": false,
"args-payload": ""
},
{
"type": "hot-region",
"args": null,
"disable": false,
"args-payload": ""
},
{
"type": "label",
"args": null,
"disable": false,
"args-payload": ""
},
{
"type": "evict-leader",
"args": [
"1031573974"
],
"disable": false,
"args-payload": ""
}
],
"schedulers-payload": null,
"store-limit-mode": "manual"
}
1、值我已经调整成 10ms,但是感觉没起作用
"patrol-region-interval": "10ms"

2、监控好像没有触发

3、现在我写了个脚本,人工把 region 调度到其他两个空间充裕的 tikv 节点上,但是感觉这样治标不治本

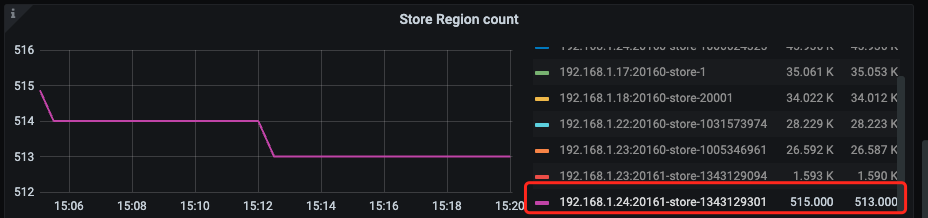
24这个节点似乎是集群自动重启恢复up状态了吧,是不是可以看看这个节点上的tikv.log日志,是不是有滚动重启。感觉应该操作是让24下线,Offline,然后等待变成 Tombstone后,再移除
我手动把 24 的 region 全部移到其他节点后就变成 Tombstone 了,感觉 pd 调度失效了
它自己不往24上移region了吗,感觉有点奇怪,你不是已经down掉24了吗
对啊,ps 查看进程都没看到
可以试试调整 region weight ,tikv 的空间相差太大了。
https://docs.pingcap.com/zh/tidb/stable/pd-scheduling-best-practices#负载均衡
举例:
设置 store id 为 1 的 store 的 leader weight 为 5,Region weight 为 10:
>> store weight 1 5 10