【 TiDB 使用环境】生产环境
【 TiDB 版本】v4.0.15
【复现路径】读慢其他人无法复现
【遇到的问题:问题现象及影响】
一、背景
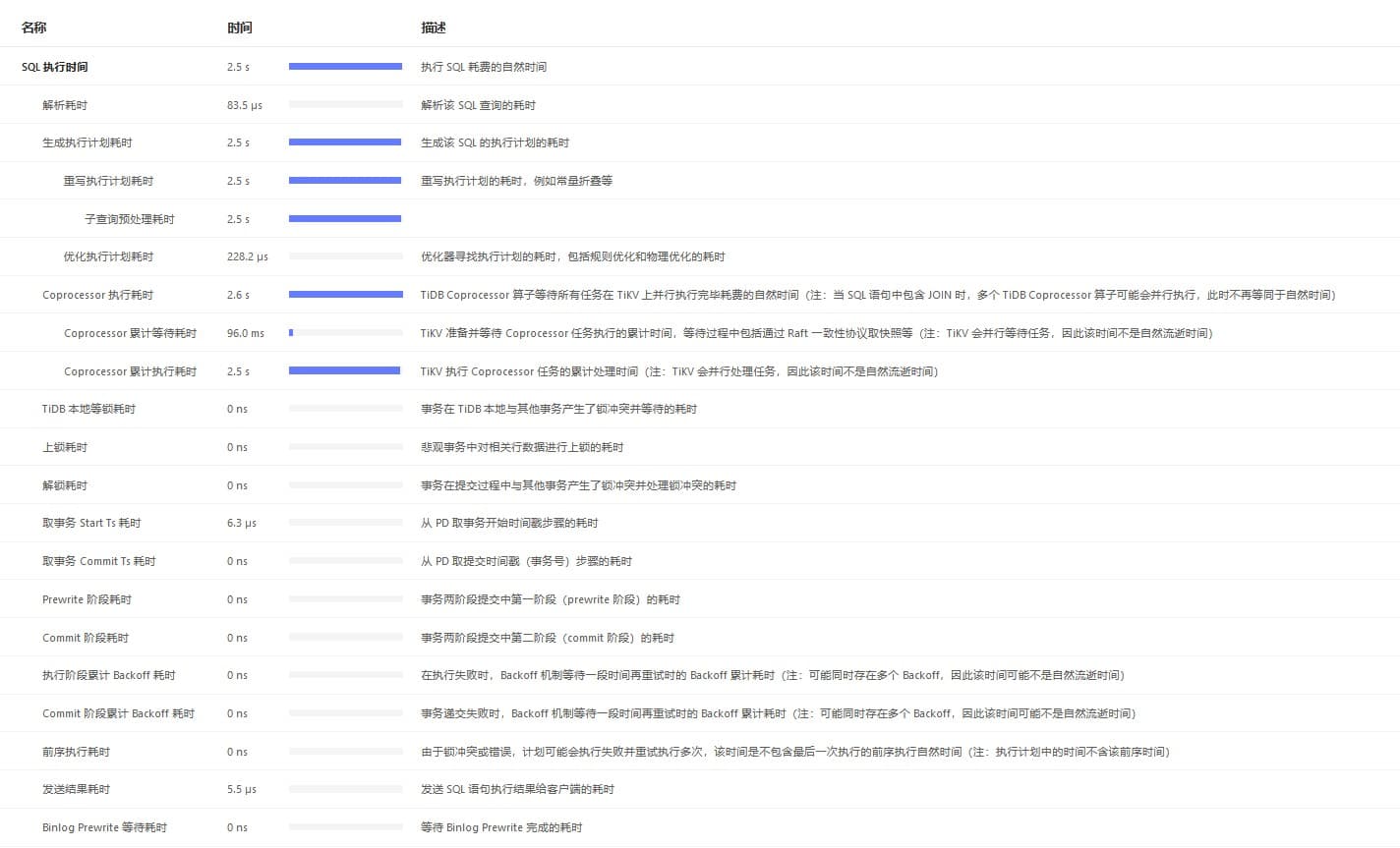
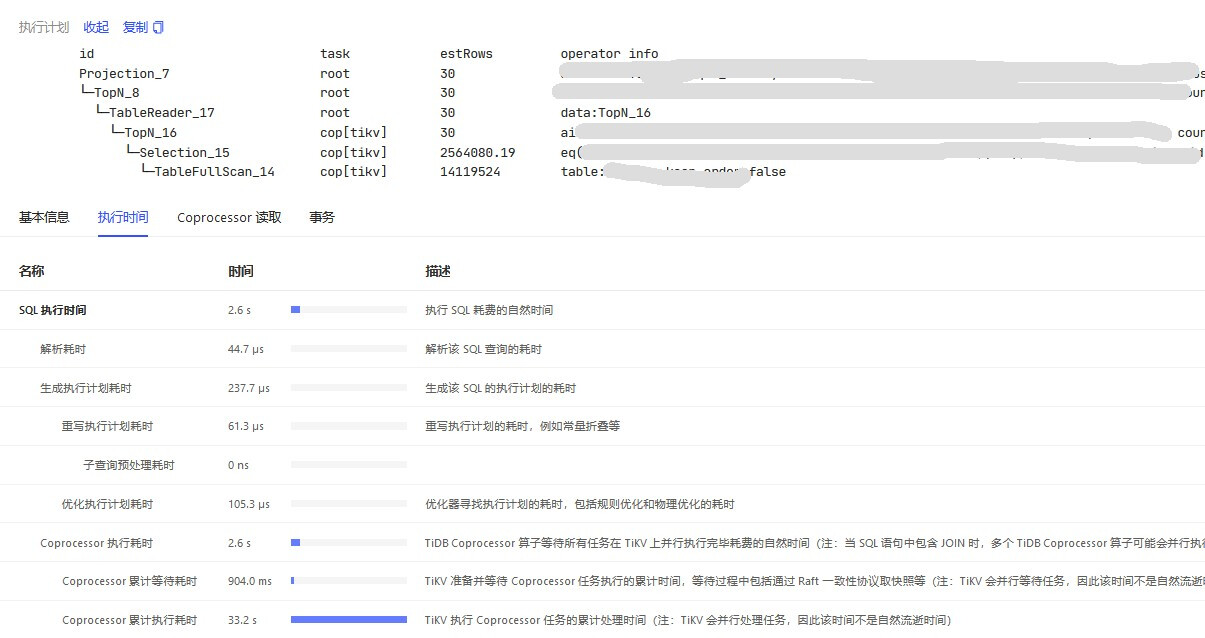
最近在排查慢请求,发现个人负责业务的慢SQL,均走索引(正常执行不慢15ms返回,扫描行数不大,表健康度99),Dashboard显示子查询预处理耗时和Coproessor执行耗时
慢请求时间点:00:50
二、排查思路
根据:
读性能慢-TiKV Server 读流程详解 - #5,来自 北京大爷 查看 TiKV-Details-Comprocessor Detail,Handle duration 与 Wait duration 确实有尖刺。
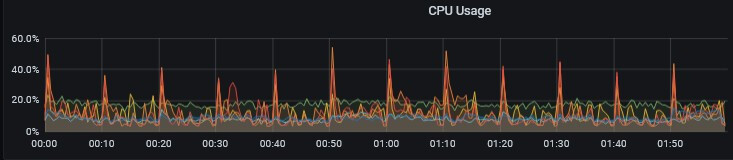
CPU 有尖刺,负载不高
Local Reader 基本命中,拒绝请求只有 92.22
三、个人推测
个人推测是其他慢请求有影响导致,查看 Dashboard 同时间确实有不少其他业务的 TableFullScan 请求在我排查的这个慢请求之前。
其他慢请求示例:
疑问:其他全表扫描的慢请求是否会影响我的 SQL 查询,个人理解是会的,但运维表示慢查询在不影响系统的情况下,应该不会影响我的查询,要影响应该是影响一大片,而非零星。
注:其他业务方的 TableFullScan 会推动改,不知道社区的小伙伴能不能解答下疑问,有没有理论依据会影响?
【资源配置】6 台 8 核 32 G 混部,资源整体使用都不高
【附件:截图/日志/监控】
人如其名
(人如其名)
2
根据我们实际情况是会影响,具体理论不清楚,猜测是一般来讲上全表扫描默认15个copTask,你三个tikv节点,一个平均5个并行task。那么多个大一点的表(超过15个region)全表扫描加上多个语句执行就很容易占用完task,其它的就得等待。tikv中有优先级好像只对pointget类好使。
有个疑惑点是如果占完资源这种,应该是会影响一大批请求,这个慢请求的量说实话不太多
看 Dashbaord 就影响我那几个
人如其名
(人如其名)
4
我也遇到过,没你这么慢,我没弄懂里面的逻辑,也有可能是内部排队机制问题?比如一个请求一直没拿到资源导致个别sql长尾?
嗯嗯,我也不太懂,蹲一波看看有没有产研或者其他大佬解释下
TiDB 支持改变全局或单个语句的优先级。优先级包括:
- HIGH_PRIORITY:该语句为高优先级语句,TiDB 在执行阶段会优先处理这条语句
- LOW_PRIORITY:该语句为低优先级语句,TiDB 在执行阶段会降低这条语句的优先级
全表扫会自动调整为低优先级
请问这个怎么解释非全表扫描的 SQL 耗时比较长,在等待嘛,恰巧嘛,如果在等待感觉应该有一批请求,但我看 Dashbaord 是零星
xfworld
(魔幻之翼)
8
一般慢SQL,会占用比较大的内存,因为全表扫描需要做一些条件比对,然后多个节点会将数据返回给tidb 节点,这个时候如果数据量较大,tidb 就很容易 OOM
第二种情况,tidb 和 tikv 节点的内存资源和计算资源被 slow query 占走了,刚好有其他的并发请求过来了需要处理,资源不足会怎么样呢? 会导致 OOM
第三种情况,slow query 较少,能够短时间内释放,tidb 和 tikv 节点资源足够,能够撑到GC 时间到来,帮助释放内存…这种情况OK
以此类推,太多状态和因素的影响了,比较复杂…
第四种情况…
…
第N种情况…
以上供你参考…
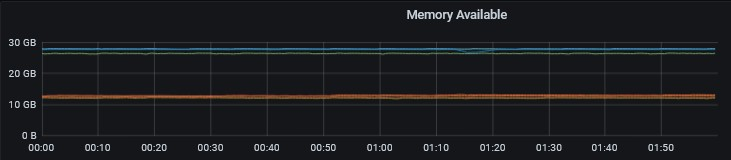
内存也没什么波动
比较纠结的点是慢请求如果不到一定程度好像不太会影响其他请求,如果能影响其他请求时,应该影响的是一批请求,不是几个请求
xfworld
(魔幻之翼)
10
不纠结嘛,注意记录 slow query,寻找优化方向就好了
注意配置好相应的告警,多用 prometheus 和 ganafa ,帮助你判断…
如果有多的资源,可以考虑上新的版本,比如 6.1.X ,测试下看看有没有提升
那也就是说一个表同时只允许15个task 并行扫描数据?
胡杨树旁
14
是不是可以看下监控 tikv-details -->Thread CPU —>Unified read pool CPU 读线程池的变化,这个监控项是否可以说明一些问题,不知道我这个思路对不对
看上去还好,99% 都是 level 0 的请求,但 level 0 请求就有最大几秒的,而且和 Run task 尖峰并非一一对应,Run task 是由尖峰,但最高就20来个并行
这周终于加了个索引,刚看了一下,确实和没加索引的那个慢查询成对出现的慢日志了,但还是有其他的慢日志和其他全表扫描的查询一起出现。
system
(system)
关闭
17
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。