TiKV 的底层存储是基于 RocksDB 的,所以数据最终是写入 RocksDB 中存储的。本章介绍 TiDB 写入流程中,关于 RocksDB 部分的写入流程,以及数据写入 RocksDB 之后数据是如果进行 Compaction 压缩以及如果和通过 GC 机制清理数据的。
6 个赞

1. 接收到 put/delete 请求
TiKV-Details → RocksDB KV/RocksDB raft → Write operations

记录的是接收到的 put/delete 请求数量以及完成情况。正常情况下 with_wal 数量和 done 的数量应该是保持一致的,有多少请求就完成多少请求。写入慢的时候可以看下:1. 请求量是不是有上升 2. 有没有请求 timeout 的情况,如果有 timeout 的情况,可以进一步排查是否有 write stall。
1 个赞
2. 进行 WAL 步骤,先写日志到 WAL 日志文件,方便 crash recovery 的时候可以根据日志恢复
默认情况下,RocksDB 的写是异步的,仅仅把数据写进了操作系统的缓存区就返回了,而这些数据被写进磁盘是一个异步的过程。RocksDB 由于有 WAL 机制保证,所以即使奔溃,起重启后也会进行写重放保证数据一致性。
TiKV-Details → RocksDB KV/RocksDB raft → Write WAL duration
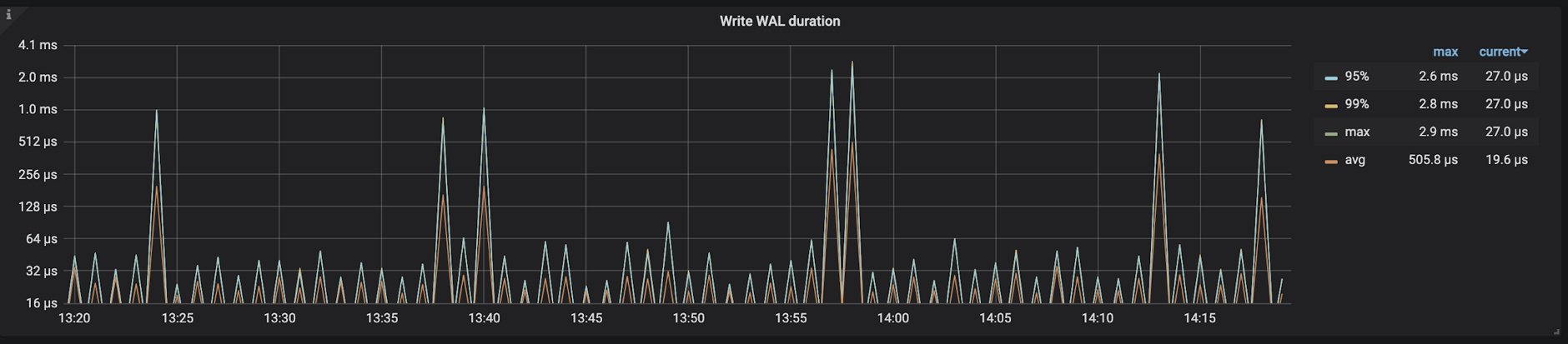
记录的是 RocksDB 在进行 WAL 操作时所花费的时间,主要关注 99 线以及 max 线,如果该监控指标耗时比较高,说明写日志花费了比较多的时间,需要排查一下机器磁盘压力以及磁盘写入性能。
3. 如果设置了 sync-log = true ,那么会调用操作系统的 fsync ,将 WAL 日志文件持久化到磁盘,避免日志数据还在操作系统文件缓存中(导致操作系统掉电重启的时候日志丢失)。
TiKV-Details → RocksDB KV/RocksDB raft → WAL sync operations
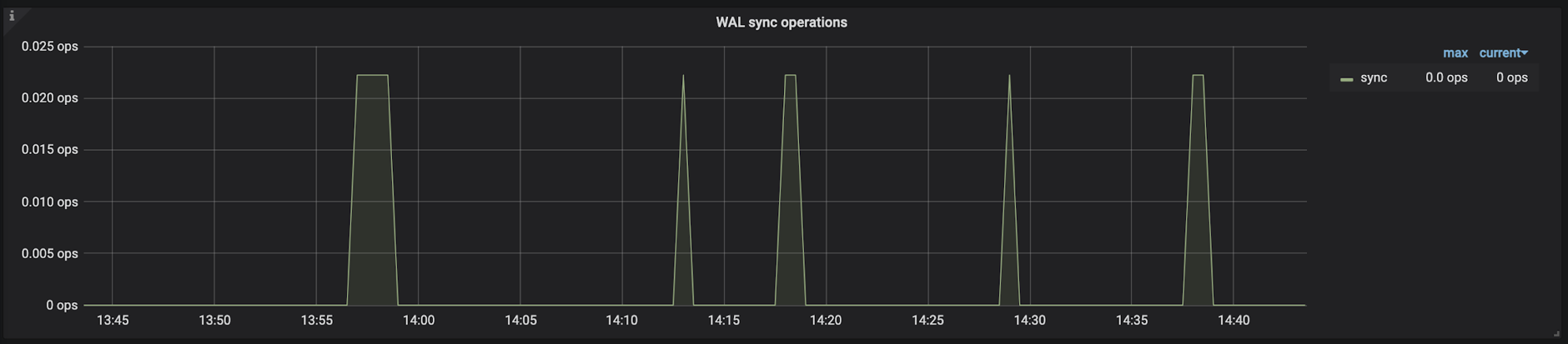
记录的是 RocksDB 写日志,调用操作系统 fsync 的次数。
TiKV-Details → RocksDB KV/RocksDB raft → WAL sync duration
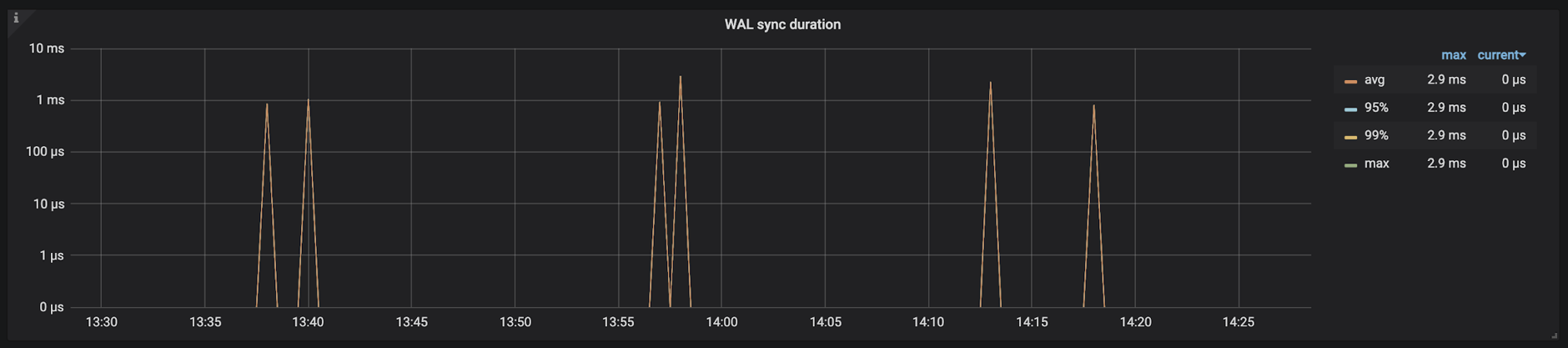
记录的是 RocksDB 写日志,调用操作系统 fsync 将数据持久化到硬盘上耗时,主要关注 99 线及 max 线,如果该监控指标耗时比较高,需要排查一下机器磁盘压力以及磁盘写入性能。
1 个赞
4. 将请求写入到 memtable 中,并返回写入成功信息给客户端。数据后台进行 Compact
TiKV-Details → RocksDB KV/RocksDB raft → Write Durtion
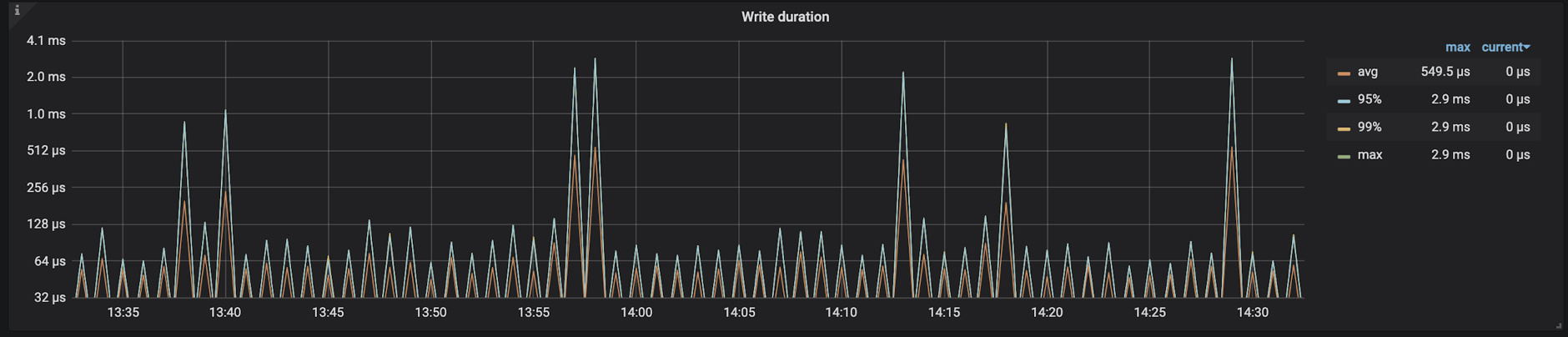
记录的是 RocksDB 收到 put/delete 请求到完成请求返回给 client 所花费的时间,主要关注 99 线及 max 线。
1 个赞
5. memtable 转化成 immutable
当写入 memtable 的数据大小达到 write_buffer_size 参数设置值,memtable 会转变成 immutable 等待 flush 到 L0 层。如果 memtable 已经达到 write_buffer_size 大小,内存中 memtable 数据量达到了 max_write_buffer_number 限制,那么会触发 RocksDB 的 write stall ,等待 immutable flush 到 L0 层。
这种由于 memtable 太多导致 stall 的情况一般是因为瞬间写入量比较大,memtable flush 到磁盘比较慢导致的。如果磁盘写入速度不能改善,并且只有业务高峰值会出现这种情况,可以通过调大对应 cf 的 max_write_buffer_number 参数来缓解。
write_buffer_size 控制一个写内存 memtable 的大小,当这个 memtable 写满之后数据会被固化到磁盘上,这个值越大批量写入的性能越好。max_write_buffer_number 控制写内存 memtable 数目数量。但是这两个值不是越大越好,太大会延迟一个 DB 被重新打开时的数据加载时间。
在这一步骤可能会有 memtable 文件过多导致 write stall,影响写入速度。
可以根据 TiKV-Details → RocksDB KV/RocksDB raft → Write Stall Reason 或者 RocksDB 日志(查找 Stalling 关键字)确认是否是 level0 sst 文件过多导致 write stall
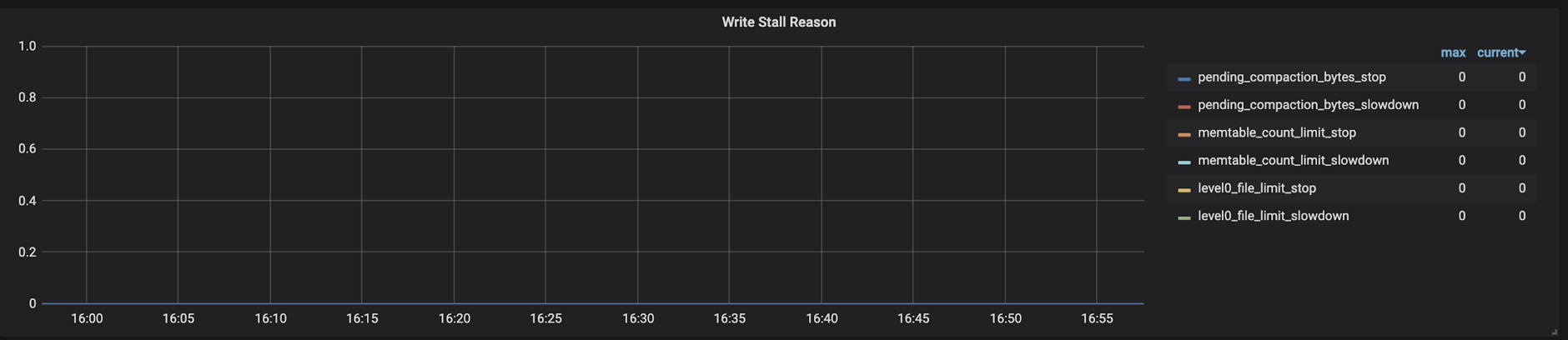
该情况一般发生在瞬间写入量比较大,并且 memtable flush 到磁盘的速度比较慢的情况下。如果磁盘写入速度不能改善,并且只有业务峰值会出现这种情况,可以通过调大对应 cf 的 max-write-buffer-number (默认是 5)来缓解。
1 个赞
6. immutable compaction 到 L0 层
immutable 数量达到 min-write-buffer-number-to-merge (TiKV 中默认是 1)之后就会触发 flush。
1 个赞
7. L0 层 compaction 到 L1 层
L0 Compaction 采用 Universal Compaction(size tiered) 的方式进行 Compaction。触发 Compation 条件:L0 层 SST 文件数量达到 level0-file-num-compaction-trigger 设定值,TiKV 中默认是 4。
当 L0 层 SST 文件数量达到 level0-slowdown-writes-trigger 设定值之后,TiKV 中默认是 20。RocksDB 会减慢写入速度,让 L0 尽快 Compaction 下去。
当 L0 层 SST 文件数量达到 level0-stop-writes-trigger 设定值之后,TiKV 中默认是 36,RocksDB 会停止写入文件,尽快对 L0 进行 Compaction
在这一步骤可能会有 level0 sst 文件过多导致 write stall,影响写入速度。
可以根据 TiKV-Details → RocksDB KV/RocksDB raft → Write Stall Reason 或者 RocksDB 日志(查找 Stalling 关键字)确认是否是 level0 sst 文件过多导致 write stall
如果是 level0 sst 文件过多导致 stall ,可以修改 TiKV 参数 rocksdb.max-sub-compactions 默认值是 3 。加快 level0 sst 往下 compact 的速度,该参数的意思是将 从 level0 到 level1 的 compaction 任务最多切成 max-sub-compactions 个子任务交给多线程并发执行。
2 个赞
8. L1~L6层 compaction
L1~Ln 层是否需要 Compaction 是依据每一层 SST 文件大小是否超过阈值。每一层的大小阈值是不一样的。
Compaction 相关监控判断是否是 flush 或者 compaction 导致 write stall 影响写入性能
- TiKV-Details → RocksDB KV/RocksDB raft → Compaction operations
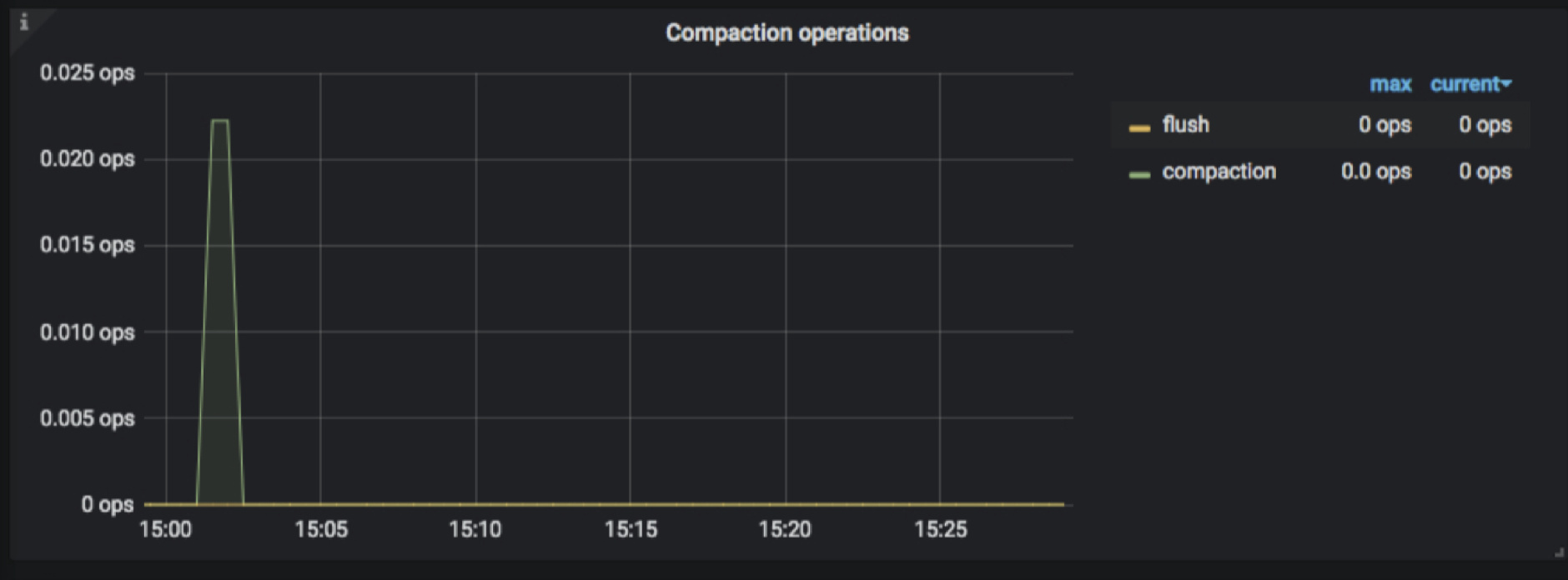
记录的是 compaction 和 flush 操作的数量,immutable 刷到 L0 是 flush ,L0~L6 刷到下一层是 compaction。
- TiKV-Details → RocksDB KV/RocksDB raft → Compaction reason
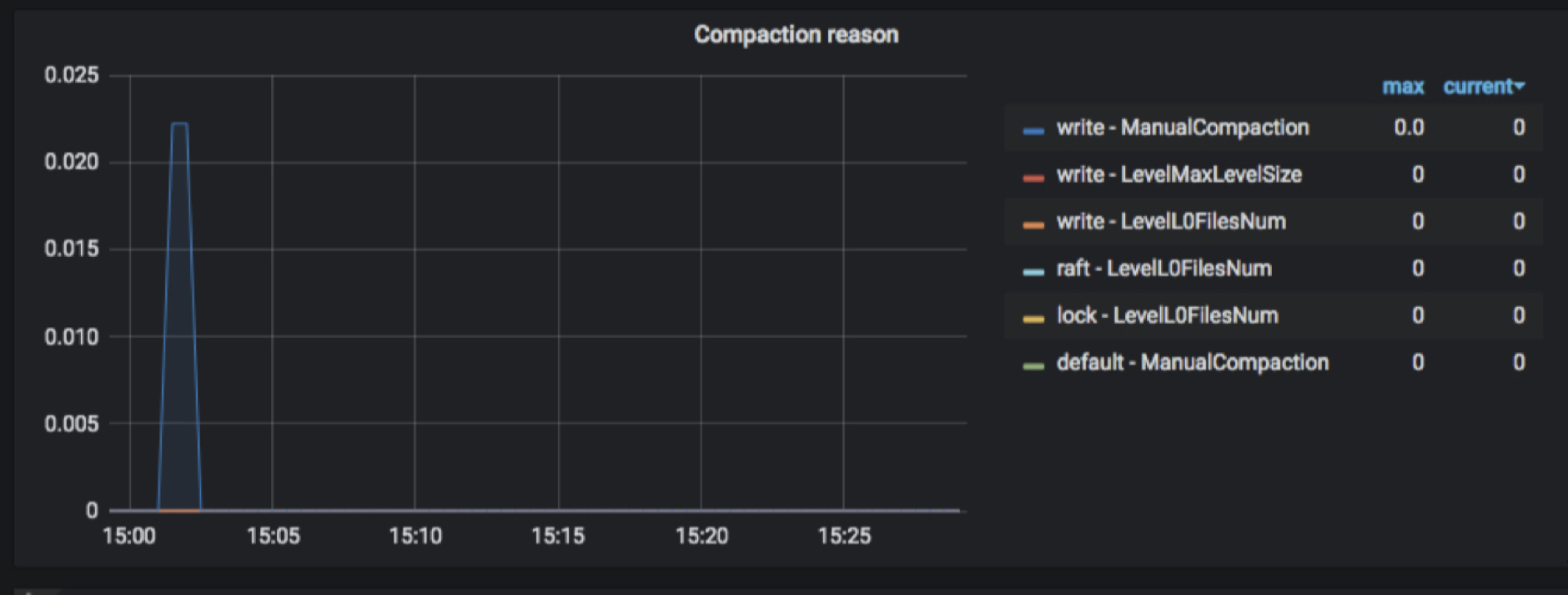
记录的是 flush/compaction 发生的原因以及时间,因为 compaction 的过程是以 column family 为单位,所有监控这边以 column family 做了区分(default/write/lock/lock),column famaily 后面是具体触发 compaction 的原因。比如 Flush 表示 immutable flush 到 L0 层,LevelL0FilesNum 表示 L0 层 sst 文件数量达到 level0-file-num-compaction-trigger 设定值触发 compaction。
具体 compaction 原因列表:https://github.com/facebook/rocksdb/blob/db03172d08d85472fe70d9f6a0a901f6ae090821/db/compaction/compaction_job.cc#L70
TiKV-Details → RocksDB KV/RocksDB raft → Compaction duration
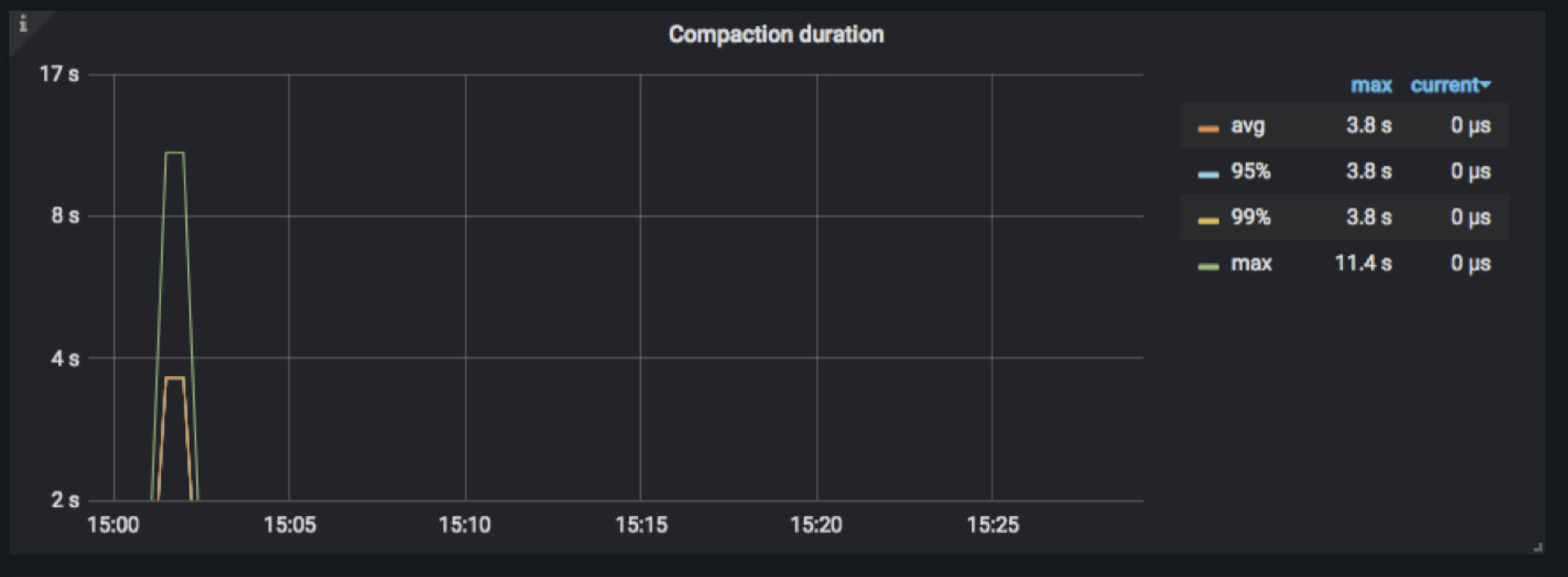
记录的是 compaction 和 flush 操作的耗时
- TiKV-Details → RocksDB KV/RocksDB raft → Compaction flow
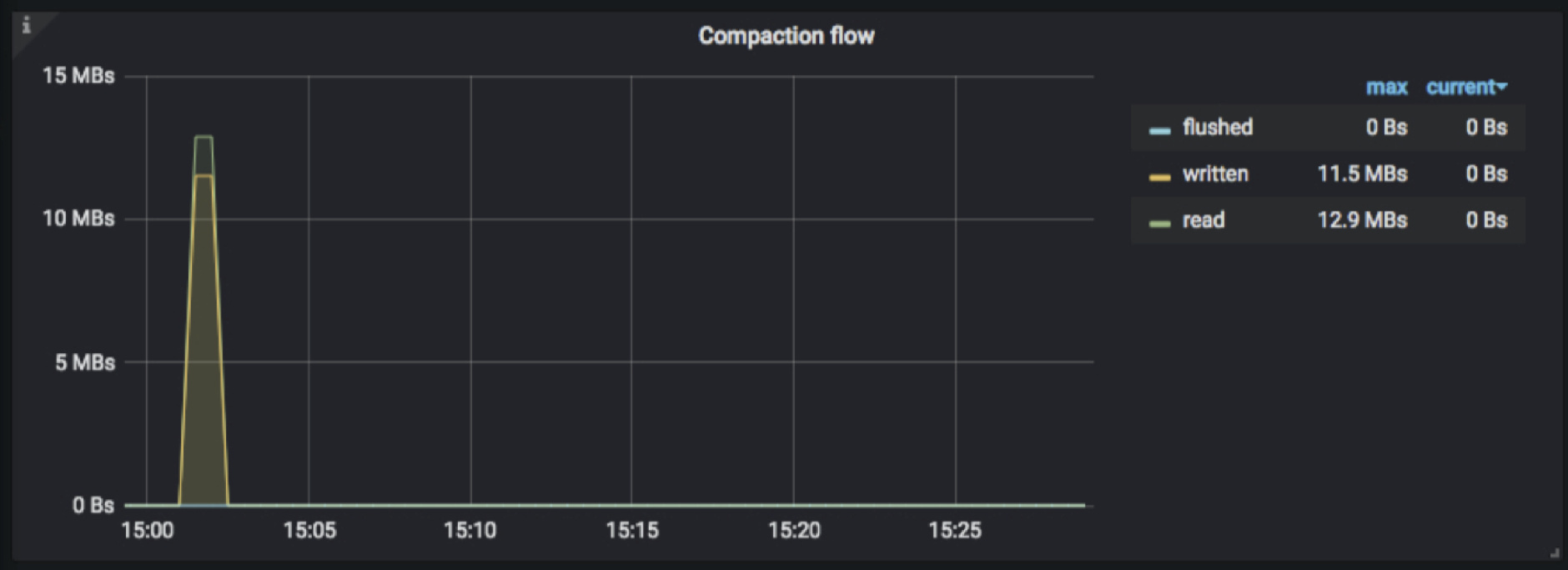
compaction 相关的流量。
- TiKV-Details → RocksDB KV/RocksDB raft → Compaction pending bytes
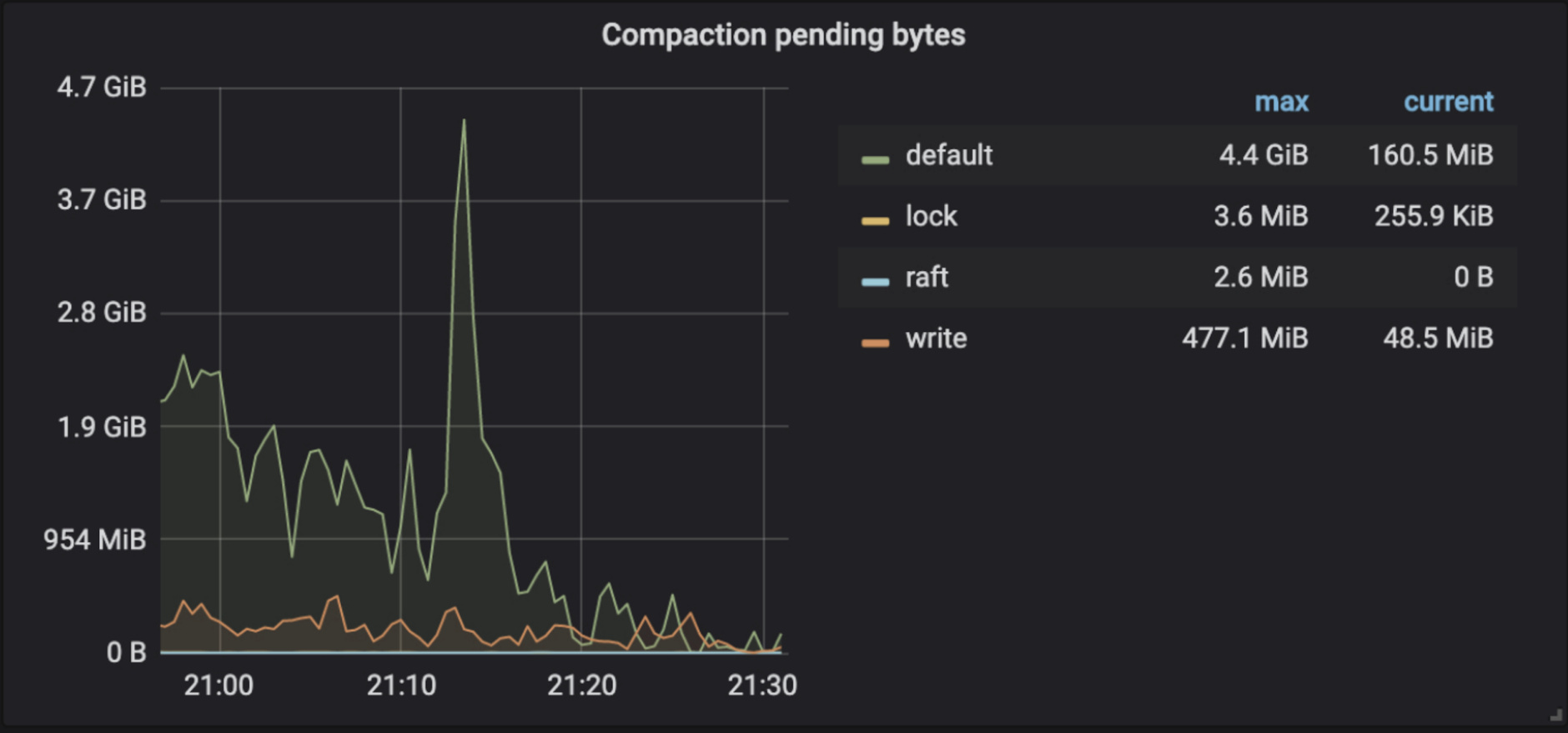
等待 compaction 的大小。Compaction pending bytes 太多会导致 stall,,当 Compaction pending bytes 达到 rocksdb.defaultcf.soft-pending-compaction-bytes-limit 参数值(默认是 64G)之后,RocksDB 会放慢写入速度;如果 Compaction pending bytes 达到 rocksdb.defaultcf.hard-pending-compaction-bytes-limit 参数值(默认是 256G)之后,RocksDB 会停止写入。
但是这个监控数据可能不太准确,可以根据 TiKV-Details → RocksDB KV/RocksDB raft → Write Stall Reason 或者 RocksDB 日志(查找 Stalling 关键字)确认是否有 compaction 导致 write stall 以及具体原因
如果是 Compaction pending bytes 过多导致 write stall 有几种解决方案:
- 调大 soft-pending-compaction-bytes-limit 和 hard-pending-compaction-bytes-limit 参数,防止触发 write stall ,但是这个只是治标不治本,根本原因应该是 compaction 慢
- 确认用户是否有做过 compaction 限流,如果有,那需要放开一点限制看看
- 如果磁盘 IO 能力持续跟不上,建议扩容。
- 如果磁盘的吞吐达到了上限导致 write stall ,但是 CPU 资源比较充足,可以尝试采用压缩率更高的压缩算法来缓解磁盘压力,使用 CPU 资源换磁盘资源。比如 default cf compaction 压力比较大,调整参数 [rocksdb.defaultcf] compression-per-level = [“no”, “no”, “lz4”, “lz4”, “lz4”, “zstd”, “zstd”] 改成 compression-per-level = [“no”, “no”, “zstd”, “zstd”, “zstd”, “zstd”, “zstd”]
- TiKV-Details → RocksDB KV/RocksDB raft → Compression ratio
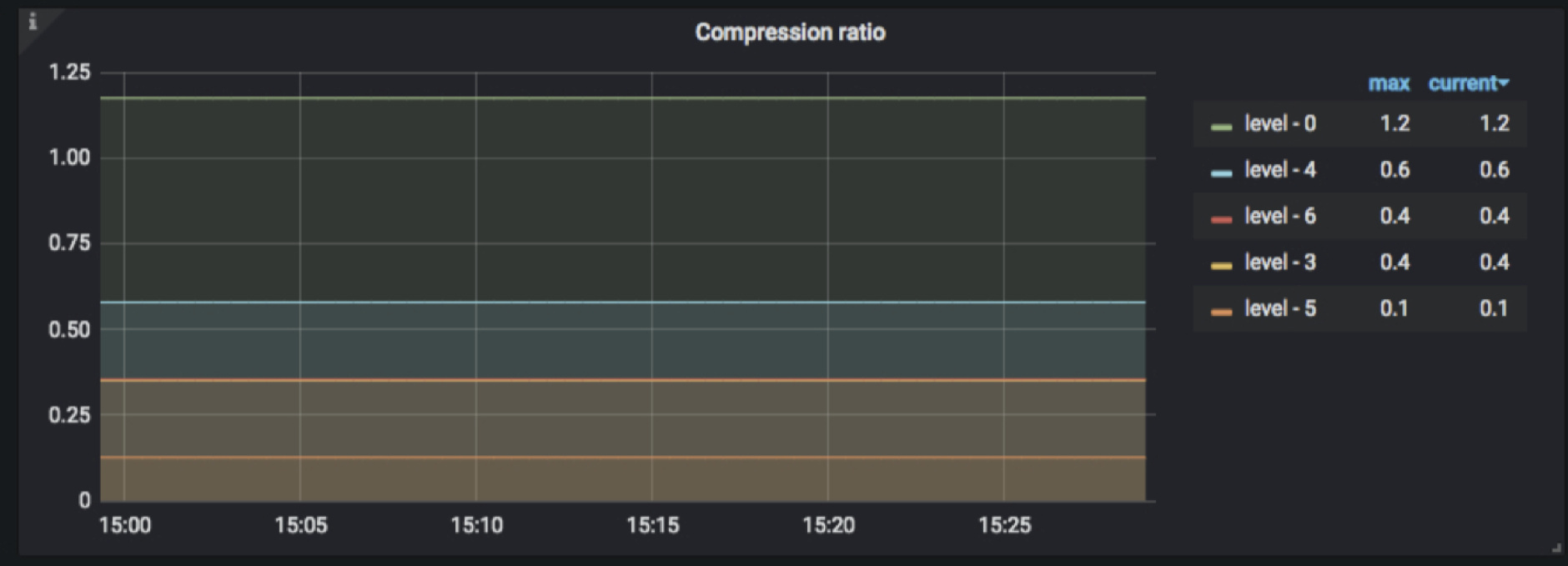
记录的是每一层的压缩比,但是这个压缩率是估算的,使用 sst 的 data_size/sst_file_size,但因为有前缀压缩和 meta/fliter block 等元信息,所以即使不开压缩,这个比值也不一定是 1
参考链接:https://rocksdb.org/blog/2016/07/26/rocksdb-4-8-released.html
3 个赞