5. 其他原因
5.1 PD 调度
由于读写请求都是根据 Region 来进行的,所以集群内部的各种调度,也会对读写请求的延迟有影响。可以从两方面进行确认,如果调度的数量较多,可以通过修改调度相关的参数 store-limit 来限制对集群使用的影响。另外,调度 Region 后,可能会触发 RocksDB kv 进行 compaction ,compaction 会对集群的性能产生一定的影响,具体见 Compation 流程
5.1.1 PD Metrics
Operator
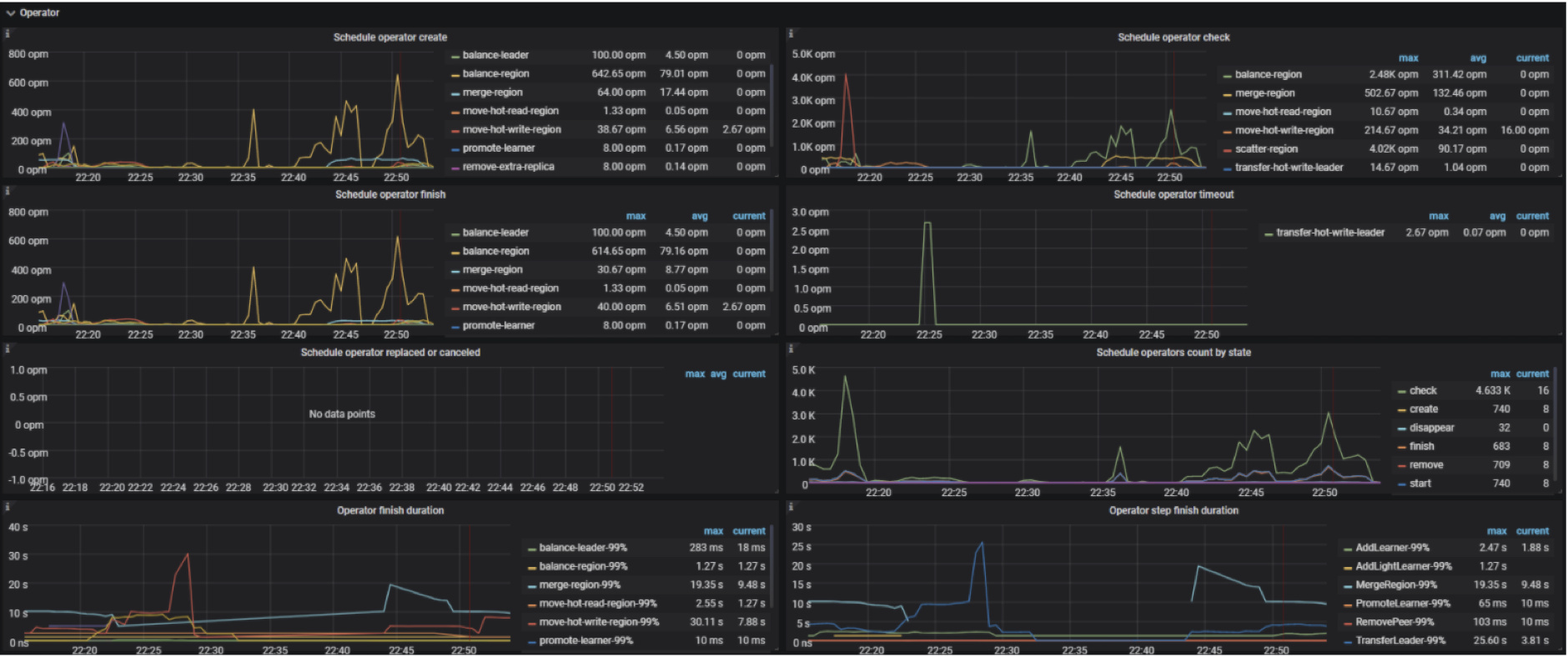
PD → Operator → Schedule operator create:新创建的不同 operator 的数量,单位 opm 代表一分钟内创建的个数
PD → Operator → Schedule operator check:已检查的 operator 的次数,主要检查是否当前步骤已经执行完成,如果是,则执行下一个步骤
PD → Operator → Schedule operator finish:已完成调度的 operator 的数量
PD → Operator → Schedule operator timeout:已超时的 operator 的数量
PD → Operator → Schedule operator replaced or canceled:已取消或者被替换的 operator 的数量
PD → Operator → Schedule operators count by state:不同状态的 operator 的数量
PD → Operator → Operator finish duration:已完成的 operator 所花费的最长时间
PD → Operator → Operator step duration:已完成的 operator 的步骤所花费的最长时间
Statistics-balance
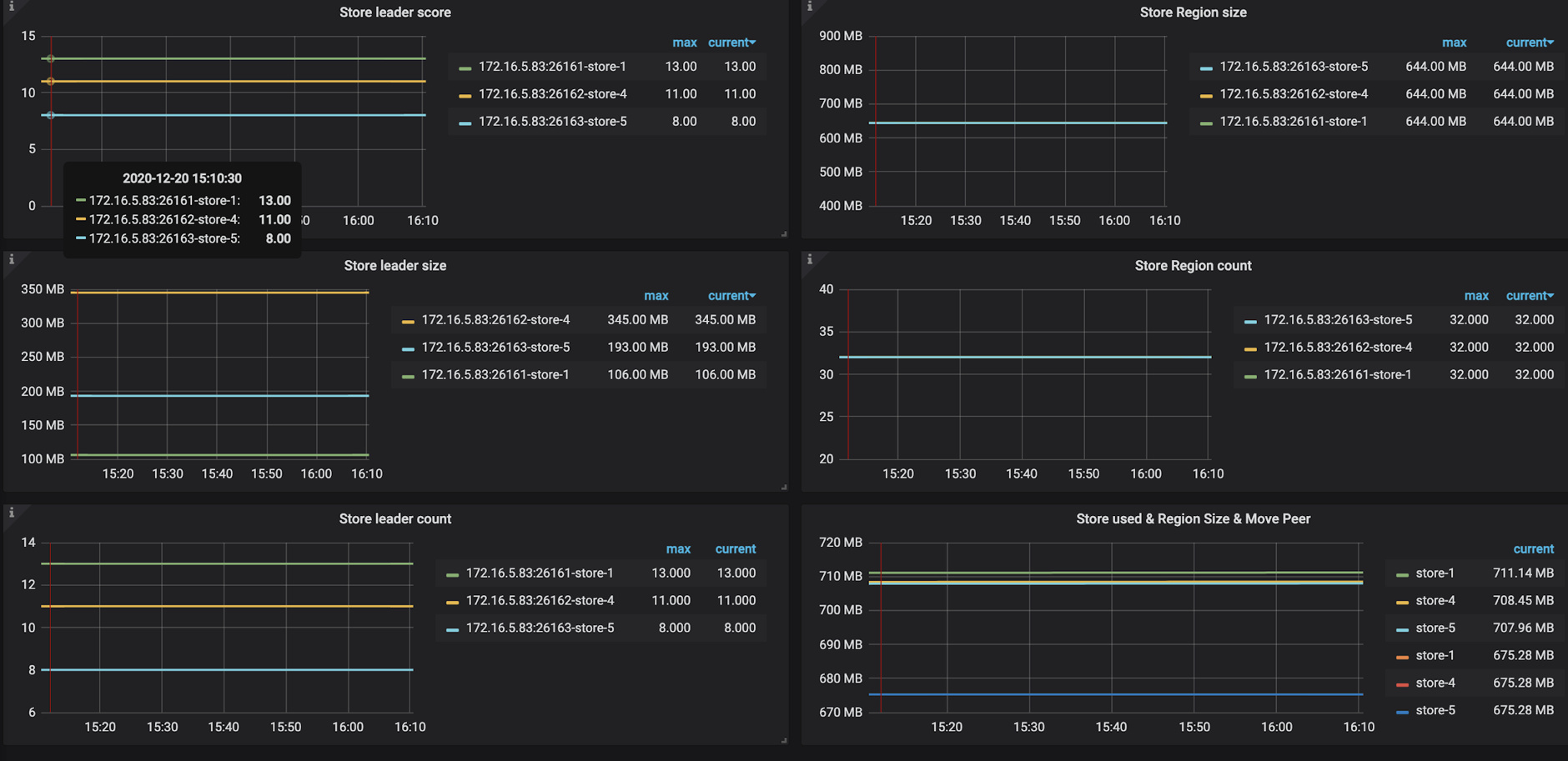
PD → Statistics-balance → Store leader score:每个 store 上面的 leader 分数
PD → Statistics-balance → Store region size:每个 store 上面的 region 大小
PD → Statistics-balance → Store leader size:每个 store 上面的 leader 大小
PD → Statistics-balance → Store region count:每个 store 上面的 region 数量
PD → Statistics-balance → Store leader score:每个 store 上面的 leader 数量
5.2 TiKV Details Metrics
5.2.1 Snapshot
Region 在调度时,会先获取这个 Region 的 Snapshot ,然后将这个 Region 调度到目标 Store 。在生成 Snapshot 时,也会扫描 TiKV。如果调度非常频繁,那么在 Snapshot 面板中会看到持续不断的生成 Snapshot 的操作,并且会不断的对 TiKV 造成压力,从而影响集群性能:

TiKV Details → Snapshot → Rate snapshot message:发送 Raft snapshot 消息的速率
TiKV Details → Snapshot → 99% Handle snapshot duration:99% 的情况下,处理 snapshot 所需花费的时间
TiKV Details → Snapshot → Snapshot state count:不同状态的 snapshot 的个数
TiKV Details → Snapshot → 99.99% Snapshot size:99.99% 的 snapshot 的大
TiKV Details → Snapshot → 99.99% Snapshot KV count:99.99% 的 snapshot 包含的 key 的个数
5.2.2 RocksDB KV
调度 Region 后,生成的 Snapshot 会使用 Ingest SST 的方式快速的将数据写入到 RocksDB 中,在 Ingest SST 时,整个集群会阻塞写入。相关监控如下:
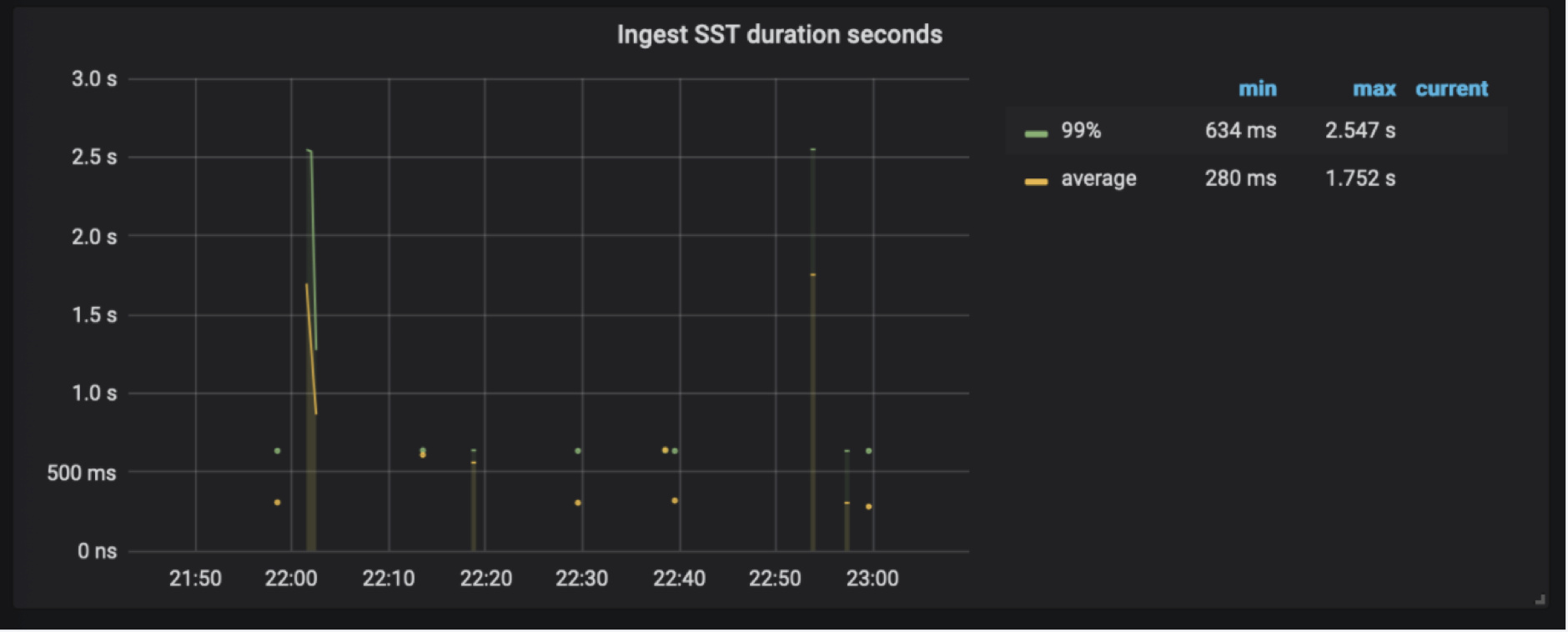
TiKV Details → RocksDB kv → Ingest SST duration seconds : ingest SST 所花费的时间。当该监控项出现连续的 Ingest SST ,并且耗时较长时,也会影响整个集群的写入性能。