支持的呀,clinic 和集群版本没关系,没记错的话,4.0 以上版本 clinic 都支持收集信息的。
不支持 ansible 部署的集群。
2 个赞
好哒,后面我尝试一下![]()
2 个赞
晚上收工插拔网线模拟还原,试了三次,
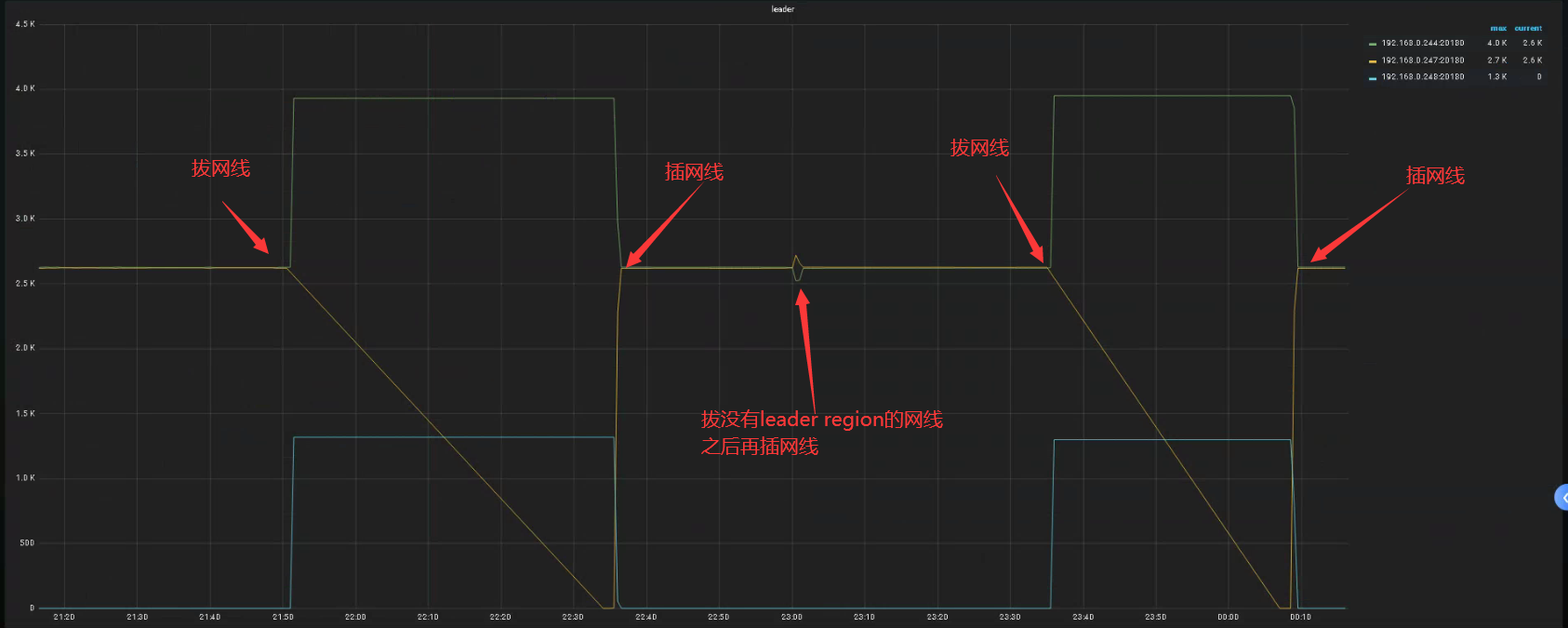
插拔247服务器,正常提供服务
插拔248服务器,正常提供服务
插拔247服务器,报错[tikv:9002]TiKV server timeout。
拔网线后,pending-peer会升高并且不下降。
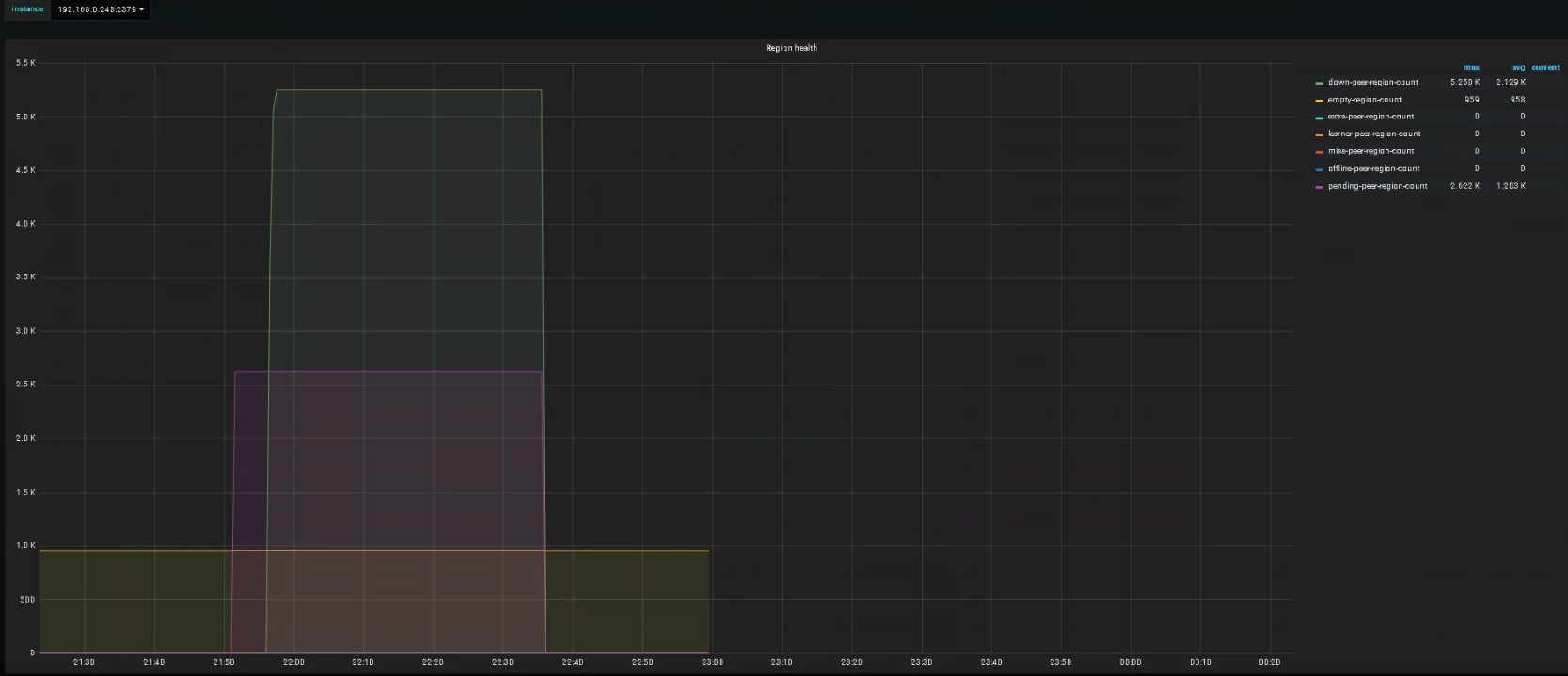

现在怀疑是leader分布不均导致的。
1 个赞
生产级别的,,拔网线测试… 霸气 ![]()
围观
![]() 关键没排查出原因,也没解决问题,就是复现了一下~
关键没排查出原因,也没解决问题,就是复现了一下~
一个个排查吧
PD 是不是leader 没了,如果 leader 没了会重新选举
再来看 Tikv 和 region,你要怀疑 region 分布有问题,通过调度是可以平衡的,但是需要时间(但是调度的话,需要满足集群基础配置的要求,如果不满足是不会调度的),我怀疑是这个问题
PD Leader一直有,并且没有down Leader节点服务器
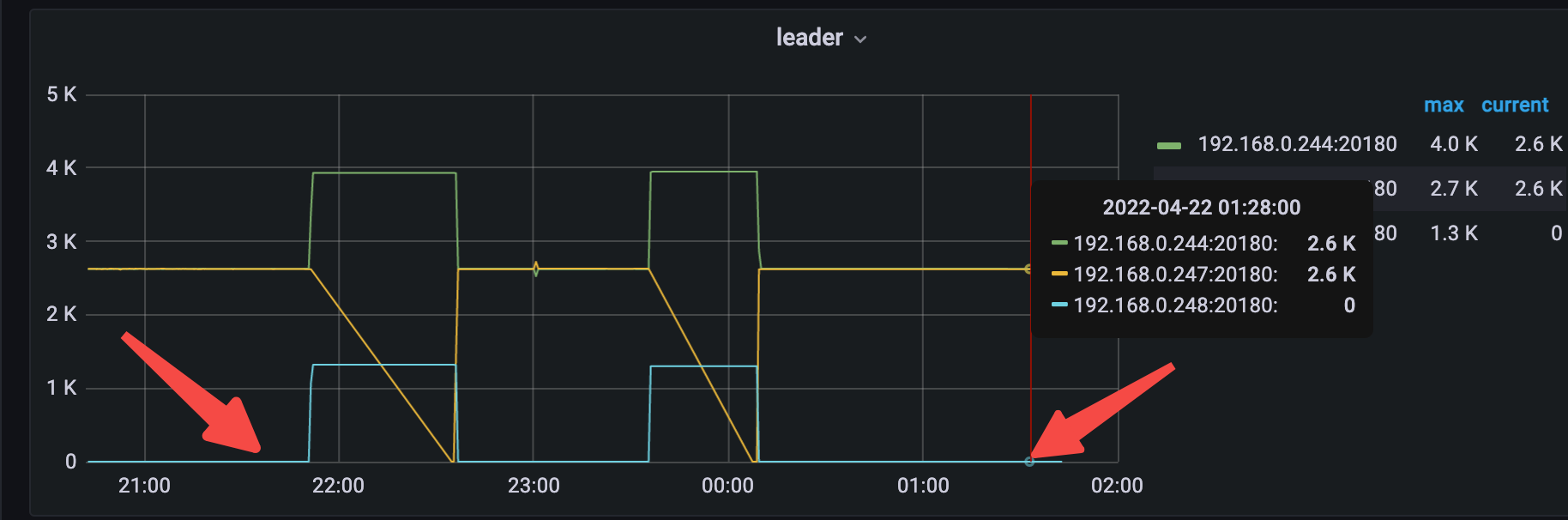
目前三台服务器,244和247是千兆带宽,248是百兆带宽,248中没有Leader副本。247down掉的时候,才会向248均衡Leader副本。
最关键的是,测试了三次,三个结果。![]()
这环境很 plus… 让我很有收获… ![]()
快速上手指南: https://docs.pingcap.com/zh/tidb/v6.0/quick-start-with-clinic
https://docs.pingcap.com/zh/tidb/v6.0/clinic-introduction
用这个上传一下数据
话说 集群不能提供访问是根据啥判断的,我觉得重点就是判断方法,及你的检查结果吧,我理解日志应该都有信息的才对
我觉得可以尝试跟踪一个 SQL 的region 来找一下原因
判断依据是通过4000端口连接,提示9102tikv超时
日志已上传附件。
现在断网了,稍后我采集一下信息
完成采集,链接已发
好的,我再来一遍。
![]() 尴尬了
尴尬了
一个一个问题看啊,集群正常的情况下,248 上没有 leader 的原因是因为存在 evict-leader,evict-leader 残留问题,是已知 bug,在 4.0.3 修复的,目前需要手动删除下。https://github.com/tikv/pd/pull/2608


尴尬了,昨天白天还想着查一下的,结果晚上给忘了,我处理一下。
按道理讲,单个节点宕机后,集群可正常提供服务。
第三个现象 [tikv:9002]TiKV server timeout。应该是 region cache 更新不及时导致的。从 tidb.log 中看到报 TiKV server timeout 是因为一直在下线的 tikv 节点,直到超过了 backoffer.maxSleep 时间,然后报了 TiKV server timeout 。和这个帖子类似 集群有一台服务器下线,集群扩缩容之后,性能很差
修复 PR 大概是这个 tikv: remove the update leader backoff by gengliqi · Pull Request #17541 · pingcap/tidb · GitHub
![]() 4.0.0 版本还是太老了,有很多已知 bug 新版本都修复了,可以先升级一下。
4.0.0 版本还是太老了,有很多已知 bug 新版本都修复了,可以先升级一下。