操作就是加索引,然后突然有个tikv挂了 看监控一直是在被拉,但是都没拉起来
请问,这个该怎么排查
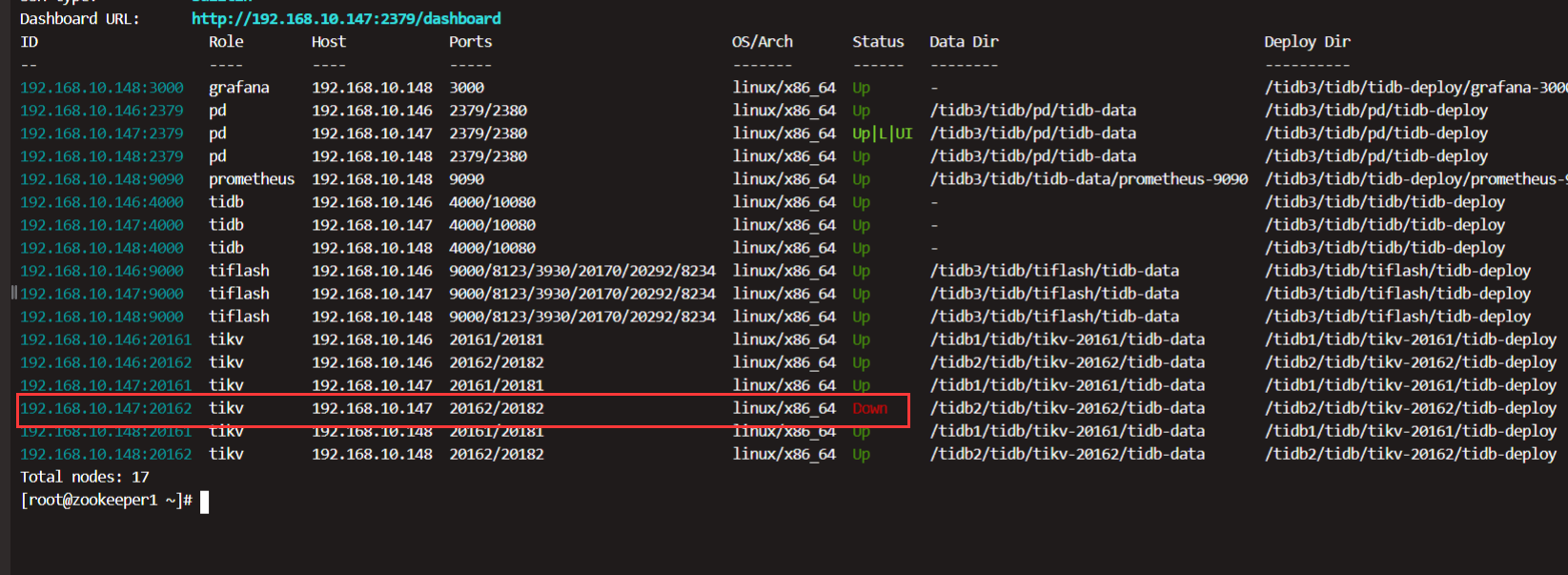
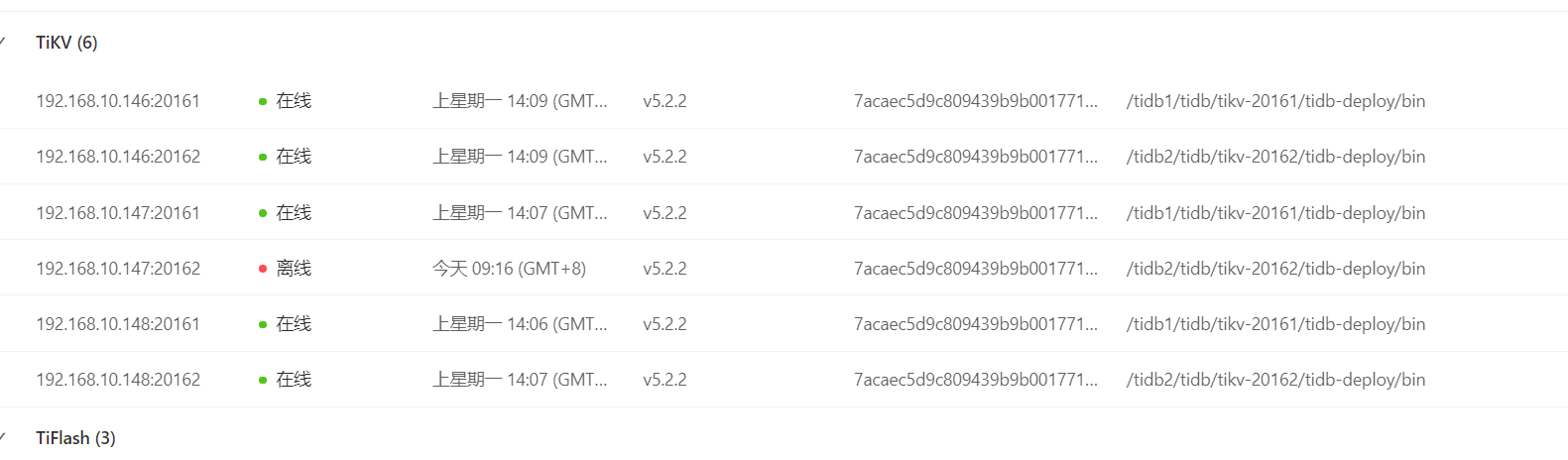
2 个赞


tikv 的配置可以贴出来么?
1 个赞
是指这个配置么
[coprocessor]
split-region-on-table = false
[readpool]
[readpool.coprocessor]
use-unified-pool = true
[readpool.storage]
use-unified-pool = true
[readpool.unified]
max-thread-count = 21
[rocksdb]
[rocksdb.defaultcf]
block-cache-size = “20000MB”
[rocksdb.lockcf]
block-cache-size = “500MB”
[rocksdb.writecf]
block-cache-size = “13000MB”
[server]
[server.labels]
host = “tikv147”
[storage]
[storage.block-cache]
capacity = “42GB”
shared = true
对,这个节点的硬件配置是什么样的? 如果配置不合理,也会造成不断重启的
storage.block-cache.capacity = (MEM_TOTAL * 0.5 / TiKV 实例数量)
`shared block cache` 的大小。正常情况下应设置为系统全部内存的 30%-50%。
假设 tiflash 是占用内存 128G, 那另外两台tikv 就一共 128G
按照以上的公式来计算, 32G 会比较好…
这个大了应该不是这个tikv起不起来的原因吧,因为这个机器上另一个节点是正常的,其他机器的两个节点也是正常的,而且机器的内存占用率没上去



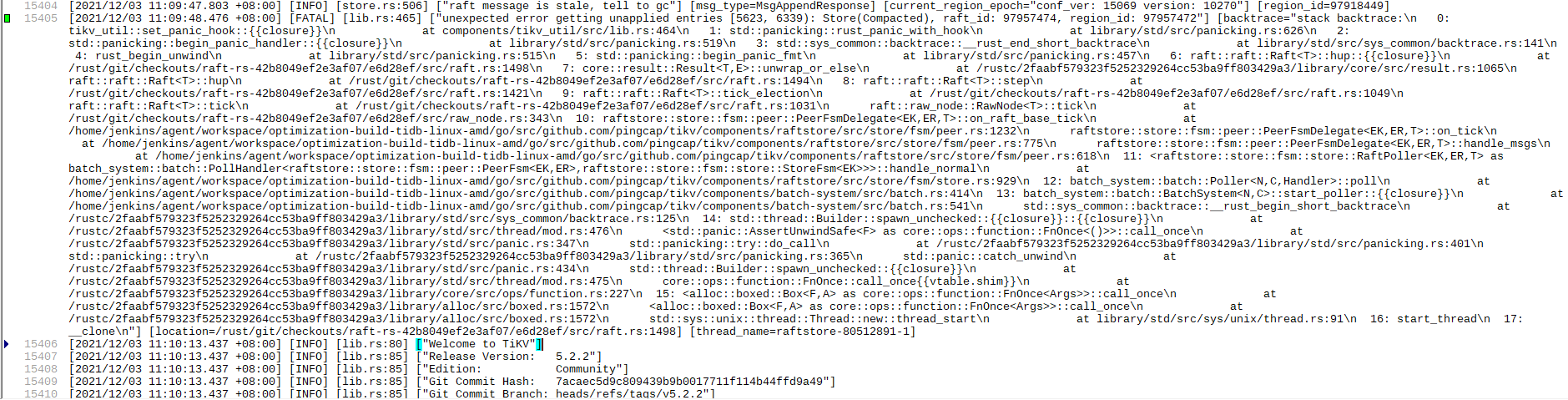
你好,可以确认第一次 tikv 重启的时间嘛,不清楚是不是 [2021/12/03 11:10:13.437 +08:00] 时间,还想再确认下。
辛苦帮忙确认下
1.麻烦把这台 TiKV 第一次 panic 的前后的日志都上传一下吧,方便我们定位原因和提供解决方法
2.同时麻烦对这个 TiKV 当前 data/snap 目录 ls -lh|grep 97957472 并贴一下结果
排查思路参考该帖子 tikv日志内不断重启失败
如果是线上业务,需要优先恢复业务的话,可以尝试先缩容再扩容
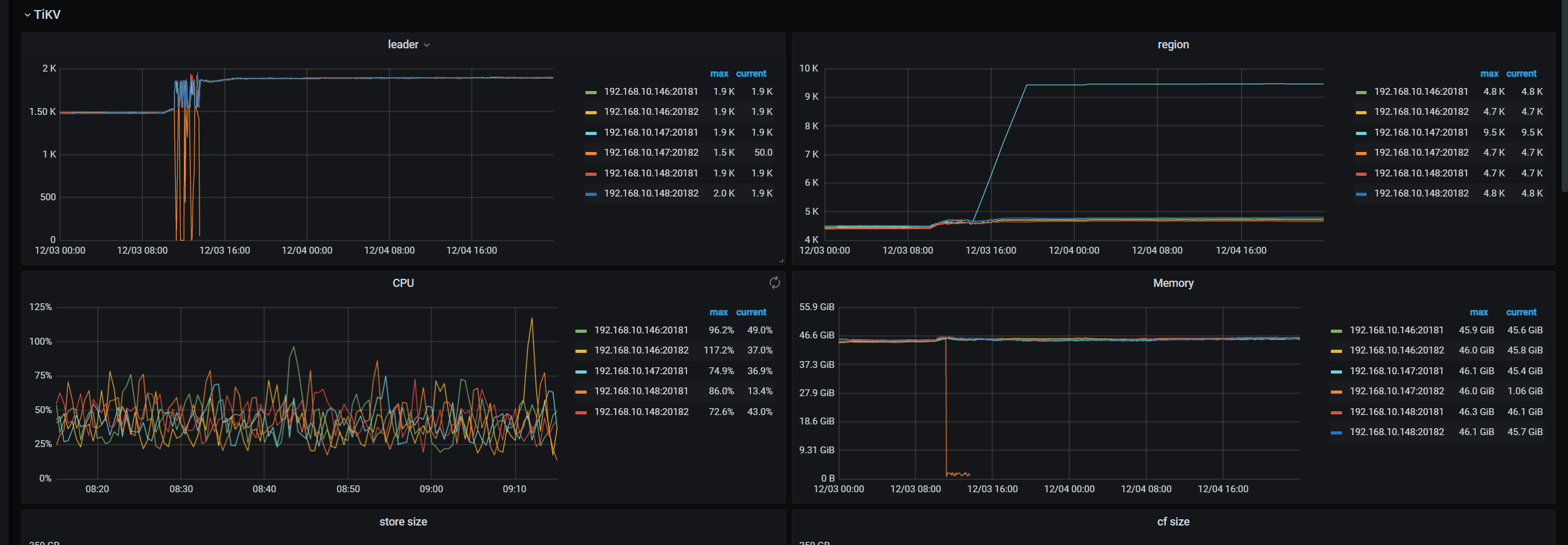
从监控上来看 重启的时间就是在11:10分左右
我把那一天的日志都上传了
log.7z (59.3 MB)
然后ls的结果是空的

那个帖子似乎没有什么有用信息吧,和你让我做的操作是一样的
是线上的业务 但是如果缩容了现场就没了吧 你们看下需要其他信息吗,如果不需要我就缩容扩容了
补充个信息,我在加索引的时候调整过这两个参数,原先是之前是被调整成了20和2048 我缩小了值,具体缩小到多少忘记了
set global tidb_ddl_reorg_worker_cnt = 20
set global tidb_ddl_reorg_batch_size = 2048
在帮忙确认下 region 97957472 的情况,可以在 pd-ctl 中执行 region 97957472 看下

另外集群版本是 5.2.2 么 ?
再拿一下 tikv-details 和 tidb 的完整监控吧,从加索引开始的时间,到 14:00 就行。
用这个 [FAQ] Grafana Metrics 页面的导出和导入 工具导出下。
是的 5.2.2
tidb-online-TiKV-Details_2021-12-06T09_31_46.817Z.json (41.0 MB) tidb-online-TiDB_2021-12-06T09_32_48.218Z.json (9.6 MB)
hello 有后续吗