已经在排查中了。
直接把该节点下掉
好的 看下需要保存现场吗 不需要我就缩容扩容了
这个应该region的缓存问题,一会就自动加载,如果异常 可以通过 curl 清理下 会自动恢复
都异常4天了- -
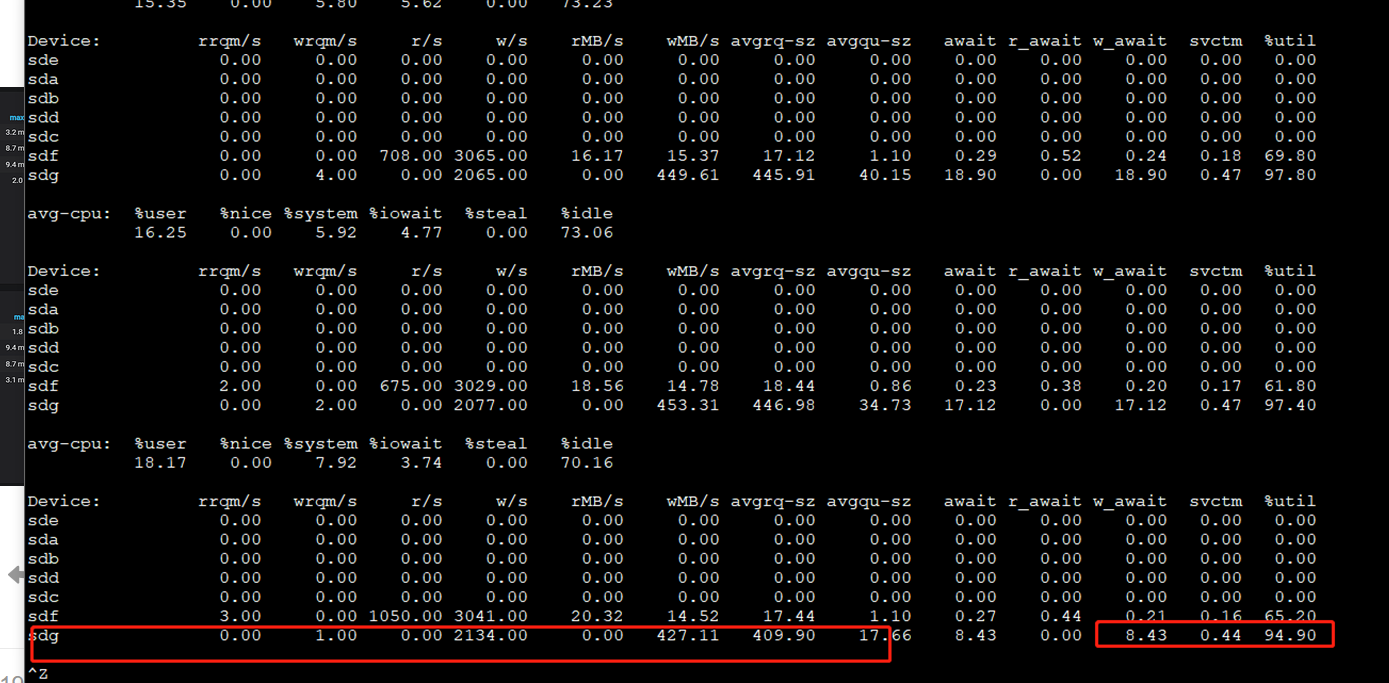
我也遇到很多无法解释的问题,要下线的节点 磁盘吞吐能达到500MB/S 直接影响了服务器上的另外一个TIKV 直接关闭 异常节点+驱逐 慢慢搞
如果重业务,不建议集群用的版本这么新呀,,目前我还在3和4版本 一切稳定为主,出问题了 在升级版本![]()
才开始用呢- - 直接布的最新版本 之前就踩了tidbserver内存溢出的坑 还得调整回以前的分析参数
可以控制会话级别的内存,可以考虑用4.0.14(360/知乎大佬建议),我用的有4.0.8、4.0.9 3.0.13 3.0.19 这几个版本 供参考
没缩容吧。。。
通过 dashboard 把所有 tikv 日志用 97957472 筛选 导出后,然后对这个节点进行缩容就可以了。
先说下初步判断:
第一次 panic 是 [FATAL] [lib.rs:465] [“unexpected error getting unapplied entries [5623, 6339): Store(Compacted), raft_id: 97957474, region_id: 97957472”],这次 panic 导致重启后触发了另一个 bug,https://github.com/tikv/tikv/pull/10501
需要提供的信息:
通过 dashboard 把所有 tikv 日志用 97957472 筛选,导出相关信息。我们继续跟进下
workaround 方法:
对该节点缩容即可。
find . -name “tikv.log*” |xargs grep “97957472”
那就在所有 tikv 节点查一下这个信息吧,这样全面一些。
可以网上搜索下,基本上是程序异常了,很多情况下是程序没有考虑到的点,bug 居多。
好的 感谢感谢。目前不需要什么信息了。
1 个赞
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。