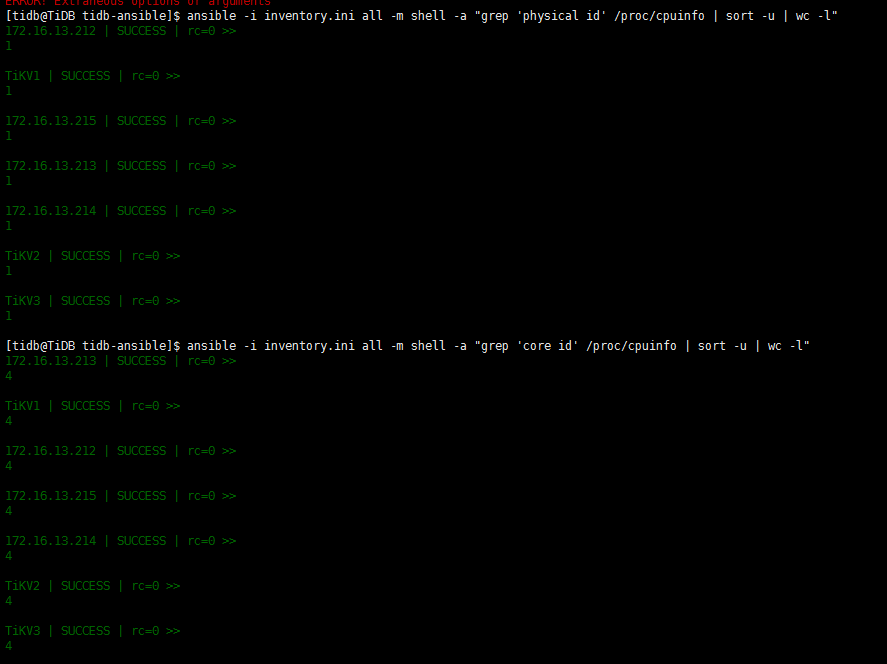
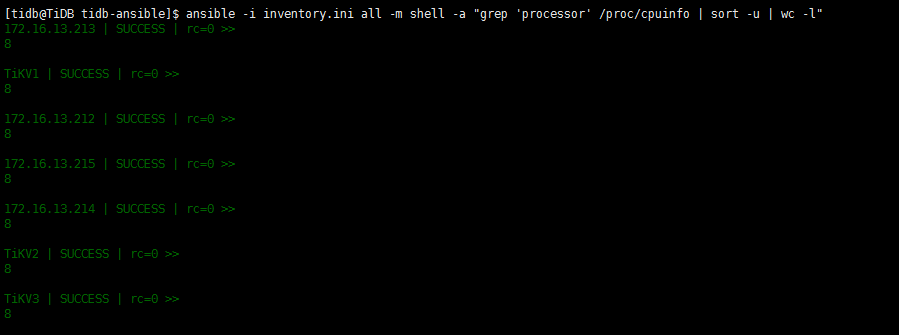
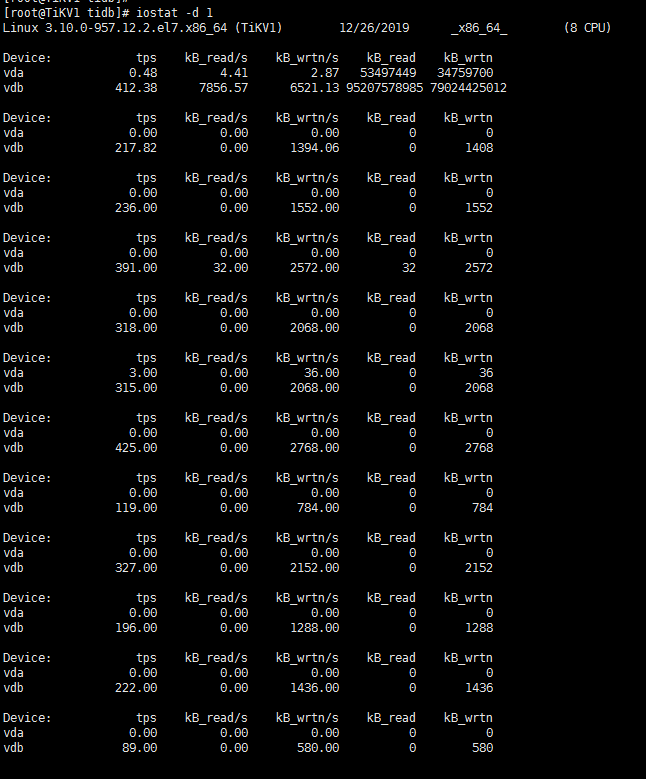
- 找一下 这个tikv的日志,查一下启动时的这个参数值吧 2. 需要的时IO util的监控,多谢 3. 这3个tikv的机器一样吗?看下其他两个的cpu和io配置
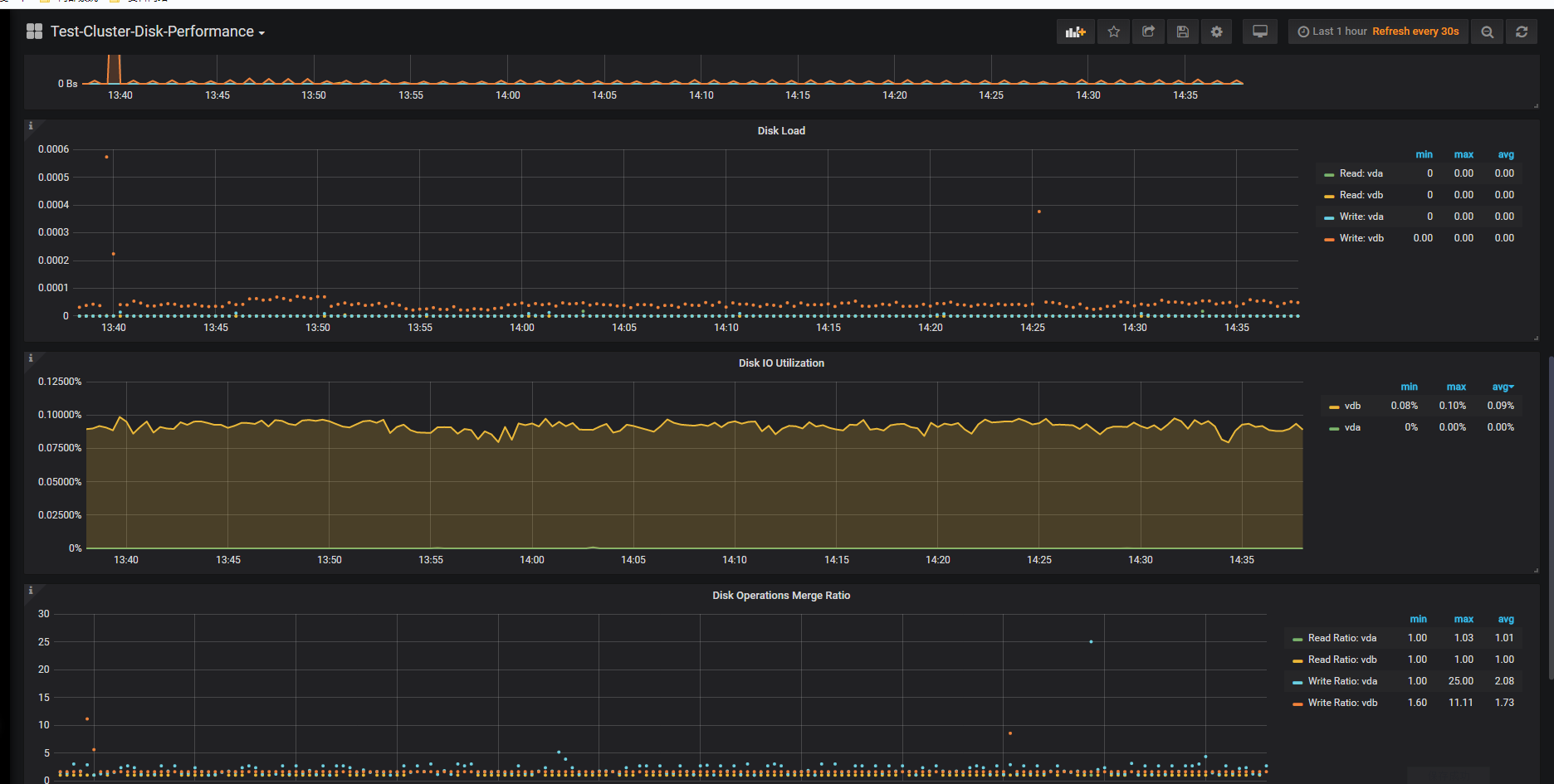
当前使用率确实很低,那就是说再导入之前,212的磁盘使用率已经100%了,你要看一下当时做什么操作了,再导入前最好可以降低212的IO使用率
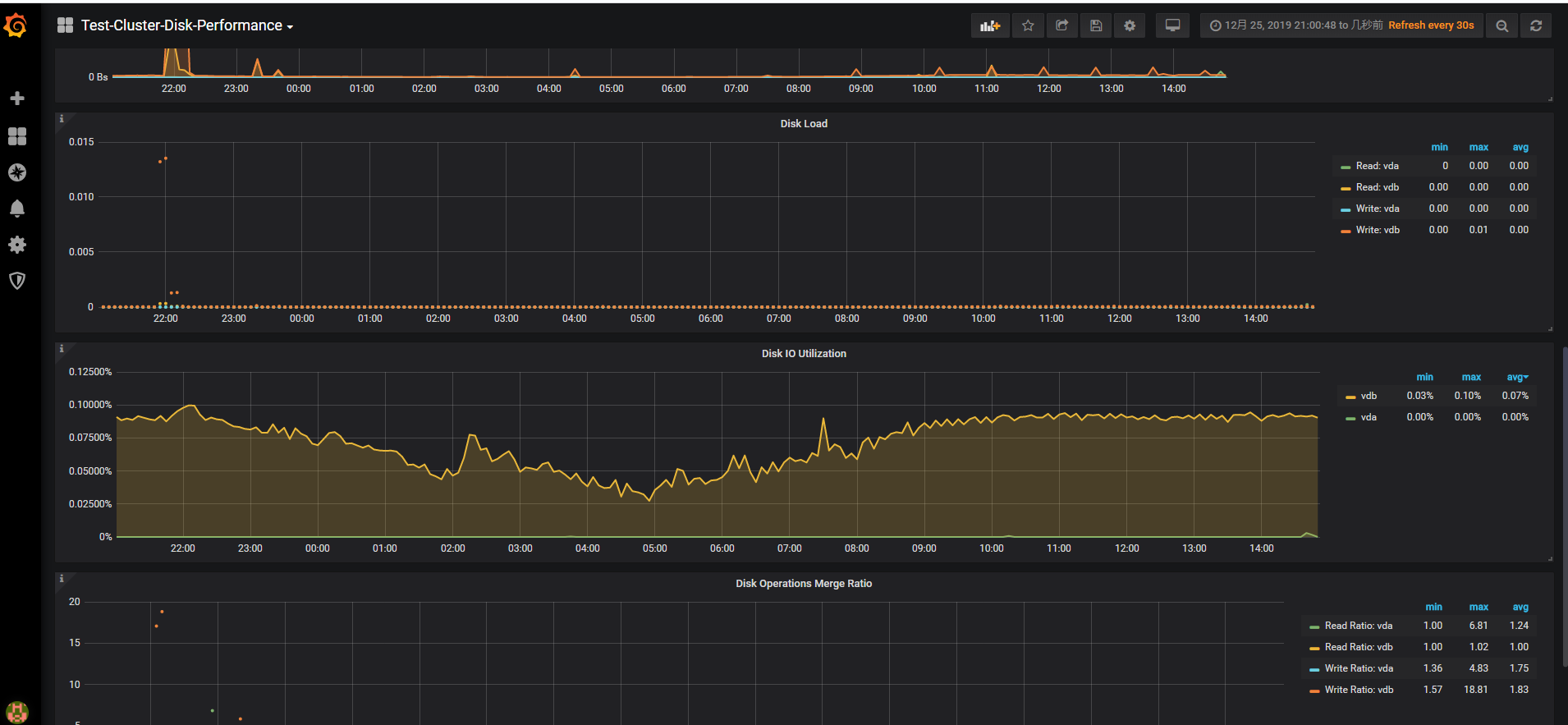


可以看到raft写log时非常慢,
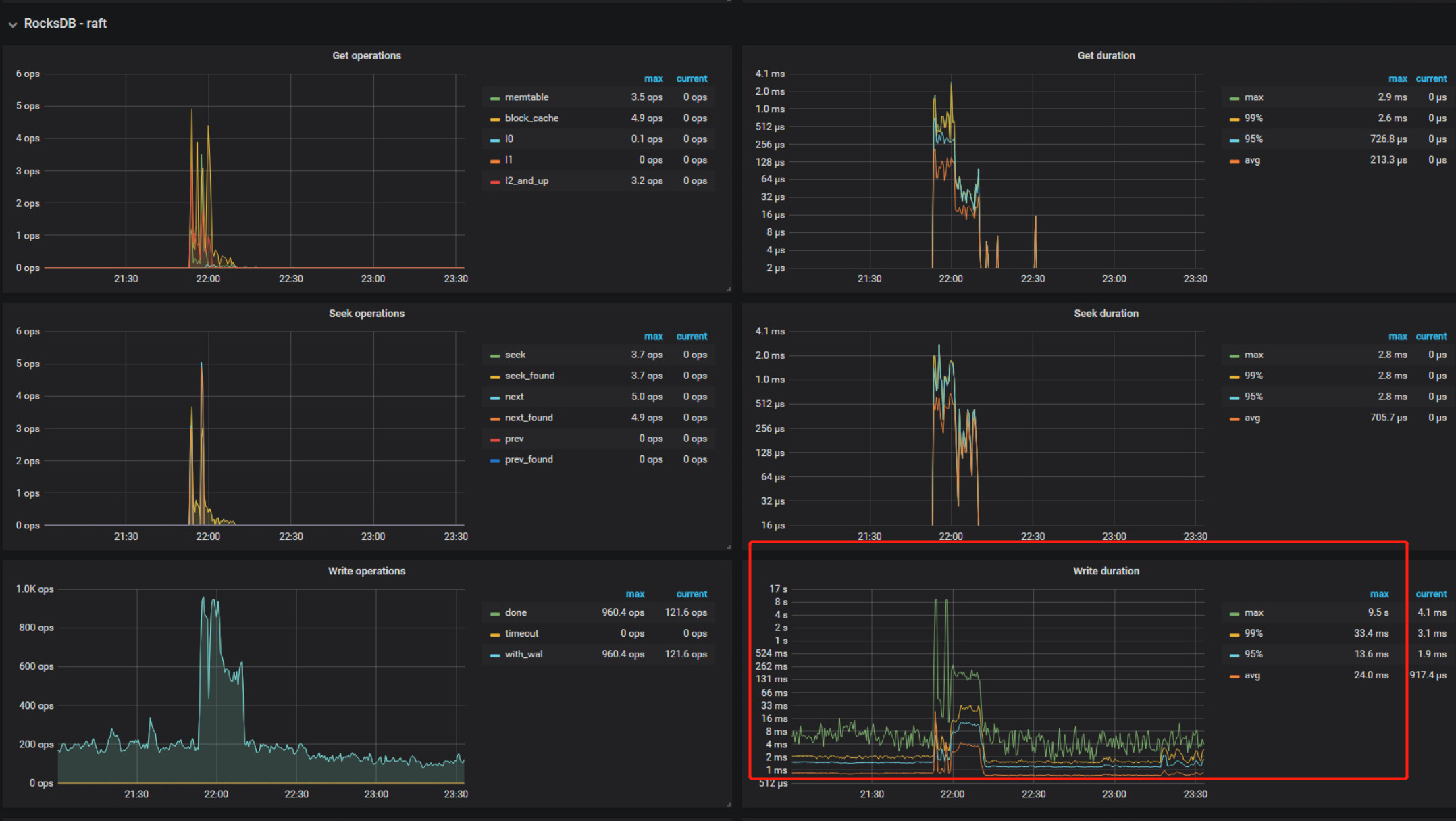
如果时测试环境,可以参考关闭sync-log参数,
https://pingcap.com/docs-cn/stable/benchmark/how-to-run-sysbench/#tikv-配置
另外,盘的写入看起来也到几毫秒了,是SSD的盘吗?
1 环境是生产环境,并不是测试环境。 2 磁盘已经是阿里云上面最贵的磁盘了,肯定是SSD。 会不会是因为上面监控数据不一样,引起tidb写入慢。
目前系统中写入量很小,多数是查询,而且大部分查询是没有结果的
- 生产环境建议还是按照标准配置,只有一个pd和tidb都是单点 2. 监控数据是从操作系统上传的,不会反过来影响操作系统. 3. 请问下,当时ansible安装的时候,磁盘检测都通过了吧?
您好,我这边是按照标准配置来的呢,组网情况如下
2 当时按照的时候,并不是我操作的,并不太清楚检测结果。
可以有什么方式或者参数,能够确认目前的磁盘是否达到要求呢
是不是版本的原因,有部分参数没有记录到启动日志中呢。
我刚刚在我测试环境版本5.7.10-TiDB-v2.0.11的tikv日志中,找到data_path关键字,提示我使用的不是SSD磁盘

但是在生产环境的版本,在tikv的log中,这个关键字都没有找到
你的home目录是系统盘吗? 阿里云的ssd是指你的数据盘是ssd还是说系统盘也是ssd? 执行下df -h ,这些和参数应该没有关系,日志记录不记录不重要。 这也不是标准配置,标准配置可以参考下官网,你的tidb和pd都是单点.
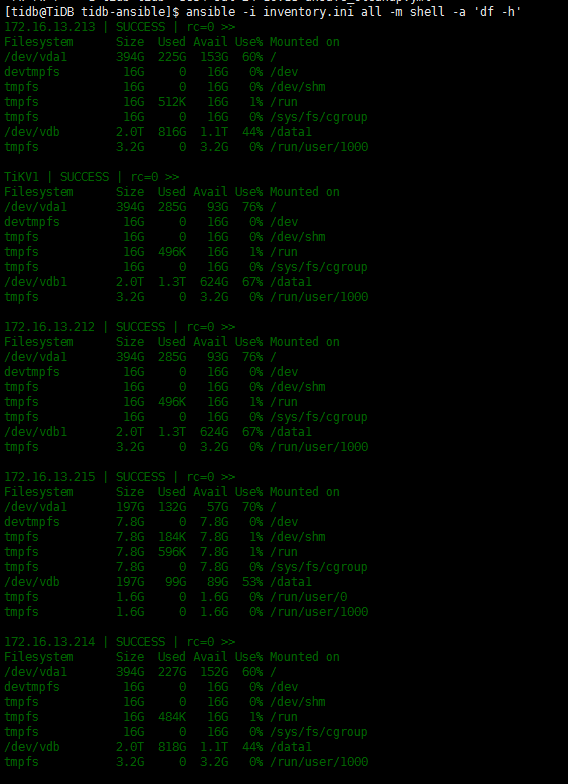
data1是你的deploy目录吧,看下212比其他两个213,214占用空间多,导致这个节点score比其他两个高很多,所以会优先写其他两个store, 用pd-ctl调度一下,将数据均衡
上面的截图,不是说明212的使用空间高吗,213、214都是使用44%,212使用了67%。
有这个差异,是因为我23号loader的文件,放到212的/data1目录下的,把loader的文件删除,三个tikv节点使用的空间就是一致的了。
但是25号晚上21点导的数据,并没有放到tikv上了,而是另外找的服务器做loader
是的,所以在25号导入的时候,空间是不同的对吧? 可以先把这个删除, 让空间保持一致。 这样就不会产生额外的调度, 然后可以把dumper文件放到其他目录,尝试导入看下效果,多谢
好的,我晚上再导入一部分数据,观察一下,后续我再反馈,感谢支持。
![]()
![]()
![]()
你好,把212节点上的其他文件删除后,导入性能有所提高,导入数据172G数据,从29号0点到7点40,用时7个半小时,完成80%。
导入日志loader.log.tar.gz (817.4 KB)
观察了tidb的慢日志情况,仍然一次commit,平均需要3秒多,慢日志文件如下1229.rar (22.3 KB)
tidb各个节点磁盘空间占用情况如下图
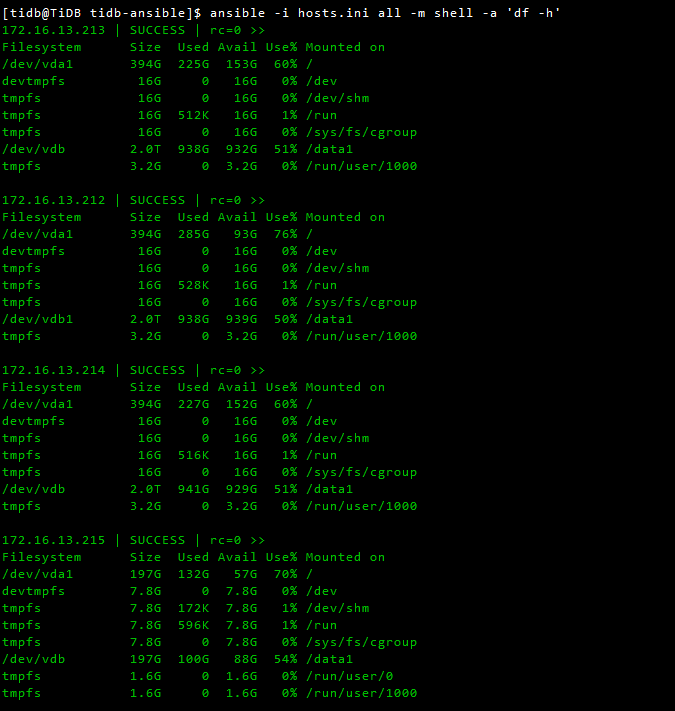
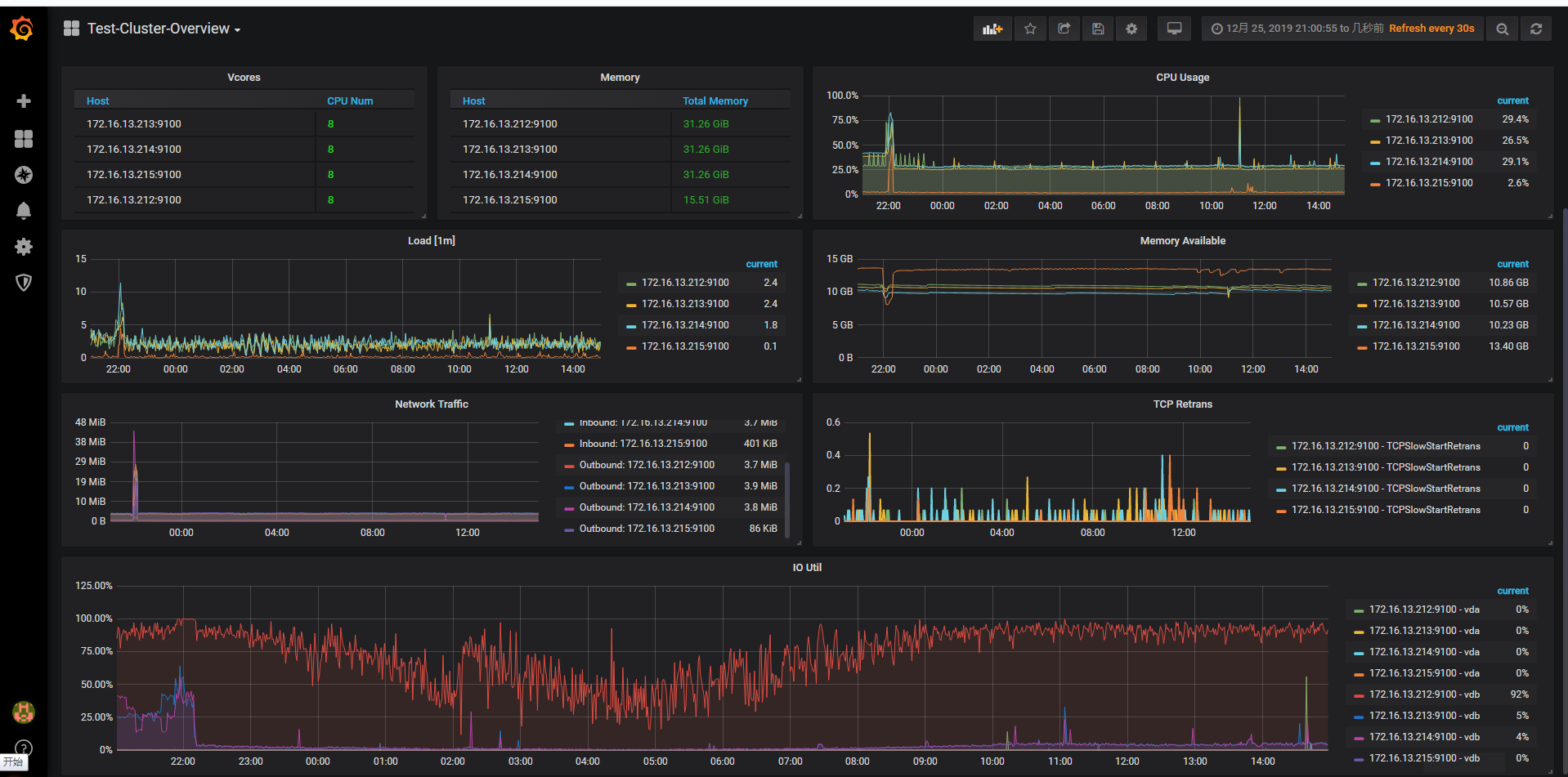
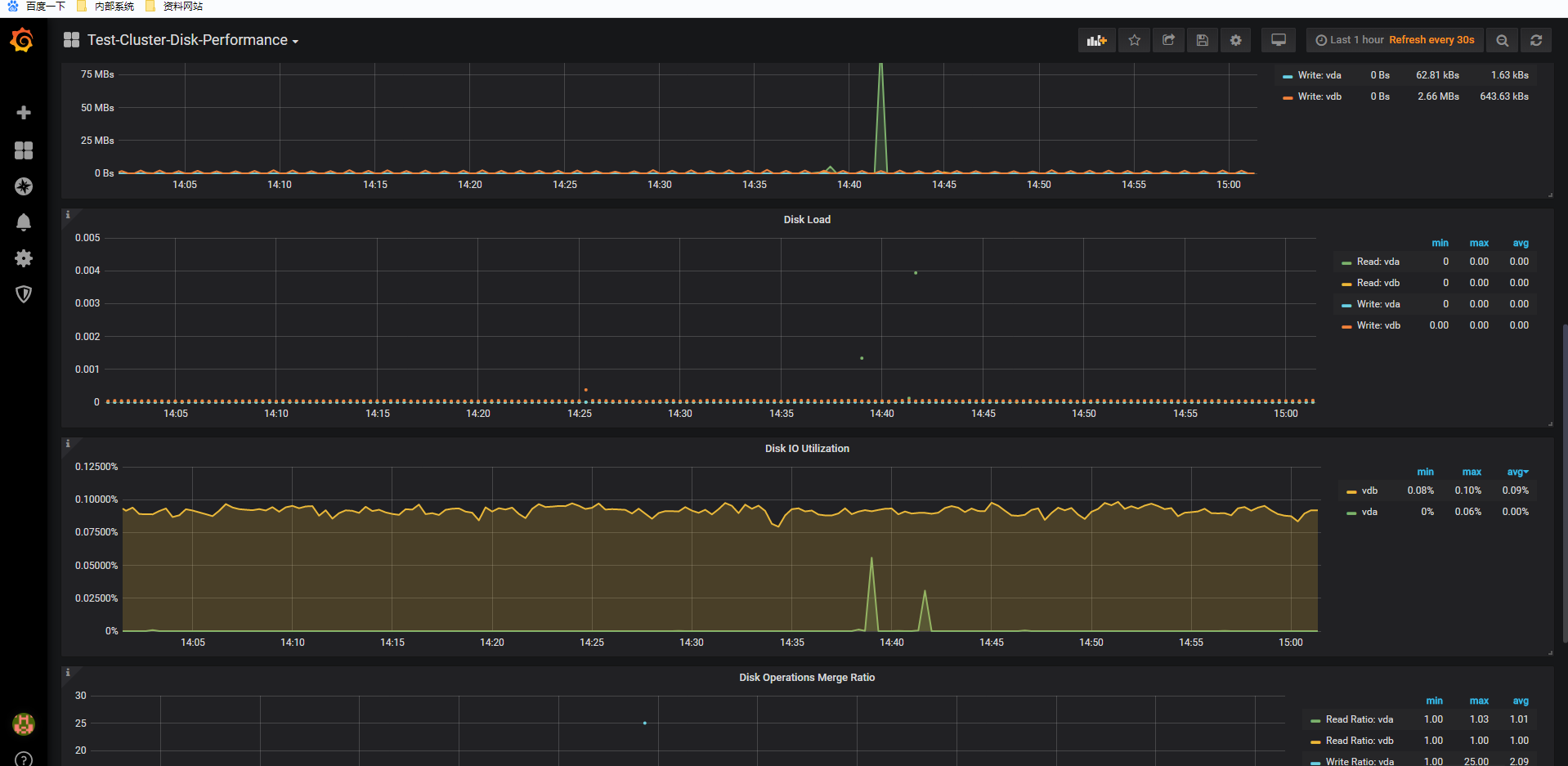
grafana的各项监控情况截图
tikv_detail_1.rar (2.8 MB) tikv_detail_2.rar (3.1 MB) disk.rar (481.0 KB) over_view.rar (1.6 MB) pd.rar (1.8 MB) tidb.rar (2.5 MB)