为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:5.7.25-TiDB-v3.0.1
- 【问题描述】:
数据从mariadb-10.2.16迁移到tidb中,导出使用 mydumper,源数据库有74G数据,导出时间3个小时,导出服务器2C8G配置,导出后SCP到另外的服务器做导入,导入服务器配置为8C32G
数据导入使用 loader,导入耗时近5个小时,请问
1 如何提高输入导入性能,后面还有很多数据迁移
2 数据导入后,在tidb的information_schema.tables.table_rows值为0,做了analyze后值仍然为0,表中有上亿的数据。
3 导入的时候,发现有慢sql,使用pt-query-digest观察发现大部分都是commit,一次commit耗时接近6秒,有没有参数可以优化这个commit,比如调整innodb_flush_log_at_trx_commit为0或2是否有效。
希望有大佬能够解惑,不胜感激!
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
- 如果是导入数据太慢,全量导入的场景推荐使用 lighting
https://pingcap.com/docs-cn/dev/reference/tools/tidb-lightning/overview/
-
第二个问题麻烦看下 mudumper 备份的命令以及 loader 导入的命令
-
tidb 中目前没有 innodb_flush_log_at_trx_commit 参数,参数显示时会出现,但是只是为了与 MySQL 兼容,实际设置没有效果
备份和导入命令
mydumper -h 127.0.0.1 -P 3306 -u root -p ‘password’ -t 16 -F 64 -B mydb --skip-tz-utc -o /data/bak
loader -h 172.16.1.129 -u root -P 4000 -t 32 -d /data/bak
如果tidb中这个参数无效,commit一次6秒这个问题如何做优化呀
谢谢
另外,由于后续需要做syncer,观察发现metadata文件中没有binlog的数据,是不是我导出的命令少加参数了呢,相同的命令,在mysql中能导出binlog记录,但是mariadb就不行
是官方的,下载地址
wget http://download.pingcap.org/tidb-enterprise-tools-latest-linux-amd64.tar.gz
commit 6 秒这个问题,可以提供一下慢日志看下
1219.rar (13.0 KB)
满日志见附件
从慢日志中看到 commit 语句的 prewrite 阶段耗时比较高,这个可以看下磁盘 io 的情况
我的集群是4个节点,平时CPU20%左右,io wait在1%左右,导入的时候只观察了cpu,会上涨至80%左右,io wait未及时观测到,但是IO,可以看到中间凸起部分,就是在load的操作
这是 tikv 节点的监控吗,这边看起来 磁盘使用率已经达到 60% 左右,写入吞吐在 150MB/s,看起来当时磁盘比较繁忙。
是所有 tikv 节点负载都是一样的吗?
这是阿里云的监控,三个TIKV节点资源使用情况是一样的,导入的时候磁盘繁忙,停止loader后,磁盘写入就降下来了。
而且很奇怪的是,如果按照150M每秒的写入,我这个250G的数据应该半个多小时就导入完成了,实际上导入了19个小时,数据才导入50%的进度
zzzzzz
(Tz)
13
表结构中是否有较多的索引,这边可能就会放大数据。
然后可以关注 tidb 的 grafana 的监控里面的各项指标,qps 等等
你好,表结构中,索引不多的。表有60张,大表没有索引,只有必须的一个主键,表中只有4、5个字段。
grafana还没有安装,所以监控不到。
现在是由于只要导入就会导致CPU、IO上升比较高,影响生产使用,都暂停迁移了。
不知道还有没有什么方式,能够优化这种commit一次6秒的情况呢
1、建议安装 grafana 和 Prometheus ,并且导入官方的相关模板,帮助我们能够高效利用丰富的 metric 信息来分析 TiDB 的集群状态或进行故障诊断。因为目前您那里无法提供相关的信息,不便于问题的跟踪和定位哈~~
2、在大量导入数据的时候,CPU,IO 的利用率会升高,这是预期内的现象。另外,如果要看资源消耗到了哪个地方,需要看下是消耗在 scheduler 、raft 还是 rocksdb。这部分需要借助于 grafana + Prometheus 采集的信息。
3、另外,在 tidb 中使用自增的 id 主键时,有可能会出现热点,下述文档有部分说明:
https://pingcap.com/docs-cn/stable/reference/best-practices/high-concurrency/#热点产生的实例
方便给一个“安装 grafana 和 Prometheus ,并且导入官方的相关模板”的操作链接吗,非常感谢
另外,在导入数据后,发现一个现象,就是tidb中information_schema.tables.table_rows值为0,做了analyze后,值仍然为0,实际上表中有上亿的数据,这可能是什么原因导致的呢
请问你的是分区表吗?
如果是分区表,现象是符合的,在 v3.0.5 版本中已经修复
https://github.com/pingcap/tidb/pull/12631
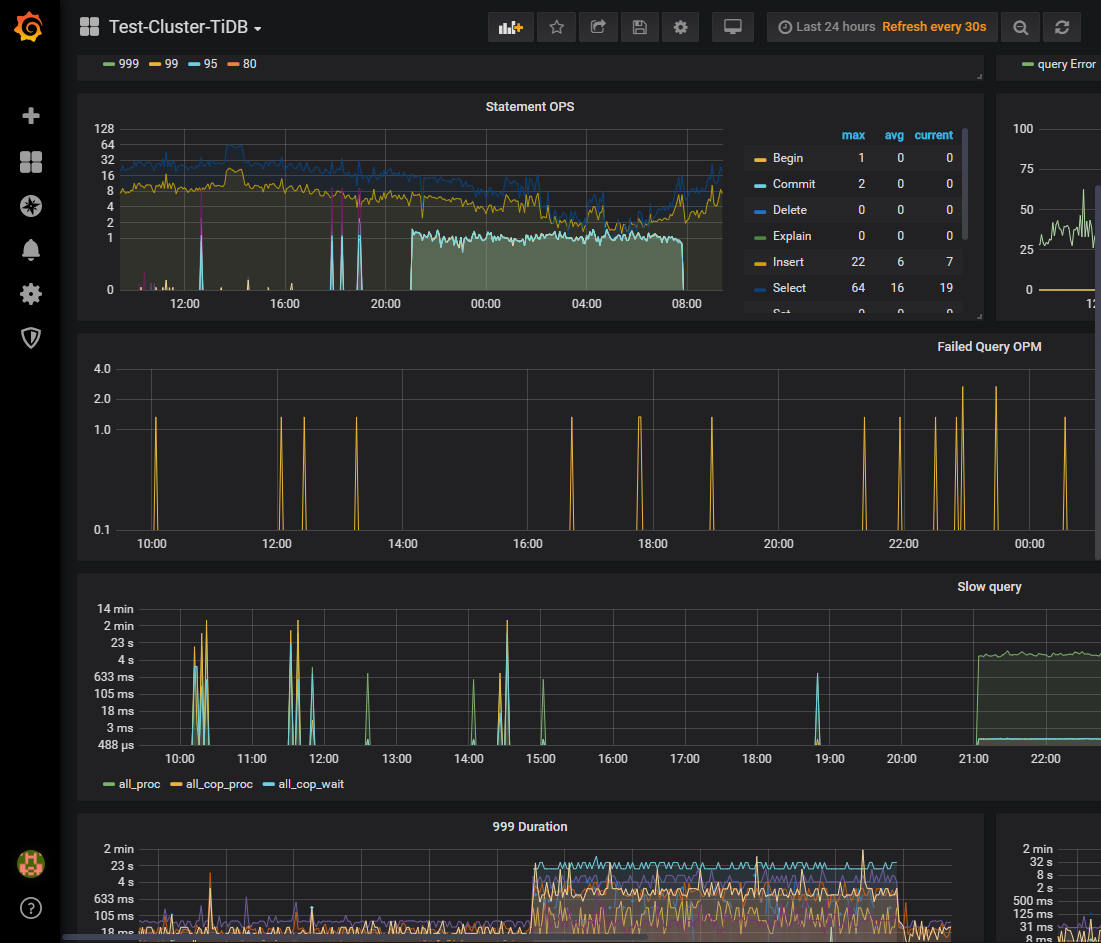
您好,我这边找回了grafana监控,由于导入只能在晚上执行。
请问下,想要定位出commit一次6秒的导入问题,需要观察哪些指标记录呢。
下图波峰时间段,为导入数据的操作
你好 可以把 tikv 面板都展开然后导出来发给我们看一下
看了提供的监控是磁盘 io 能力不行,你们这个盘是 机械盘吗