- 慢日志中很多 commit 问题,可以尝试升级到 3.0.7 ,https://pingcap.com/docs-cn/stable/releases/3.0.4/#tidb,我们有过优化
- 看了下监控,loader 导入其实是有热点的,因为是空表开始导入数据,数据比较集中,可以考虑调低并发导入,调试出最优并发
- 如果效率有问题,强烈推荐使用 lighting,lighting 不需要走 TIDB-server 这一层,一般效率是 loader 的好几倍:https://pingcap.com/docs-cn/stable/how-to/get-started/tidb-lightning/#tidb-lightning-教程
你好 1。版本升级需要先在测试环境做测试,我们后续会操作。 2。lighting导入需要把数据库模式切换到“导入模式”期间不能提供服务,但是我们的tidb不能中断服务,所以这种方式在我们的业务场景不太适用。
另外,在适用mydumper从mariadb导出的过程中,导出进程会有现超时的错误信息。
我的mariadb 数据文件450G,导出后170G,适用myloader导入后,发现有两张比较大的表,数据量差异很大,差了好几亿条记录,其他表都是正常的,这种情况下,除了重新导整个库,还有其他方式处理吗。由于我后续还需要做增量同步,所以就算现在把这两张表的数据全部dump下来,也和备份170G的时候的metadata中记录的binlog和position不一致了。
建议先查清楚问题再导数据,数据导入出现数据丢失问题排查下在导入时候是否出现报错或者异常(比如 OOM 之类),导致数据导入失败。

在 io util 高的机器上执行 iotop 看下有哪些进程在操作。

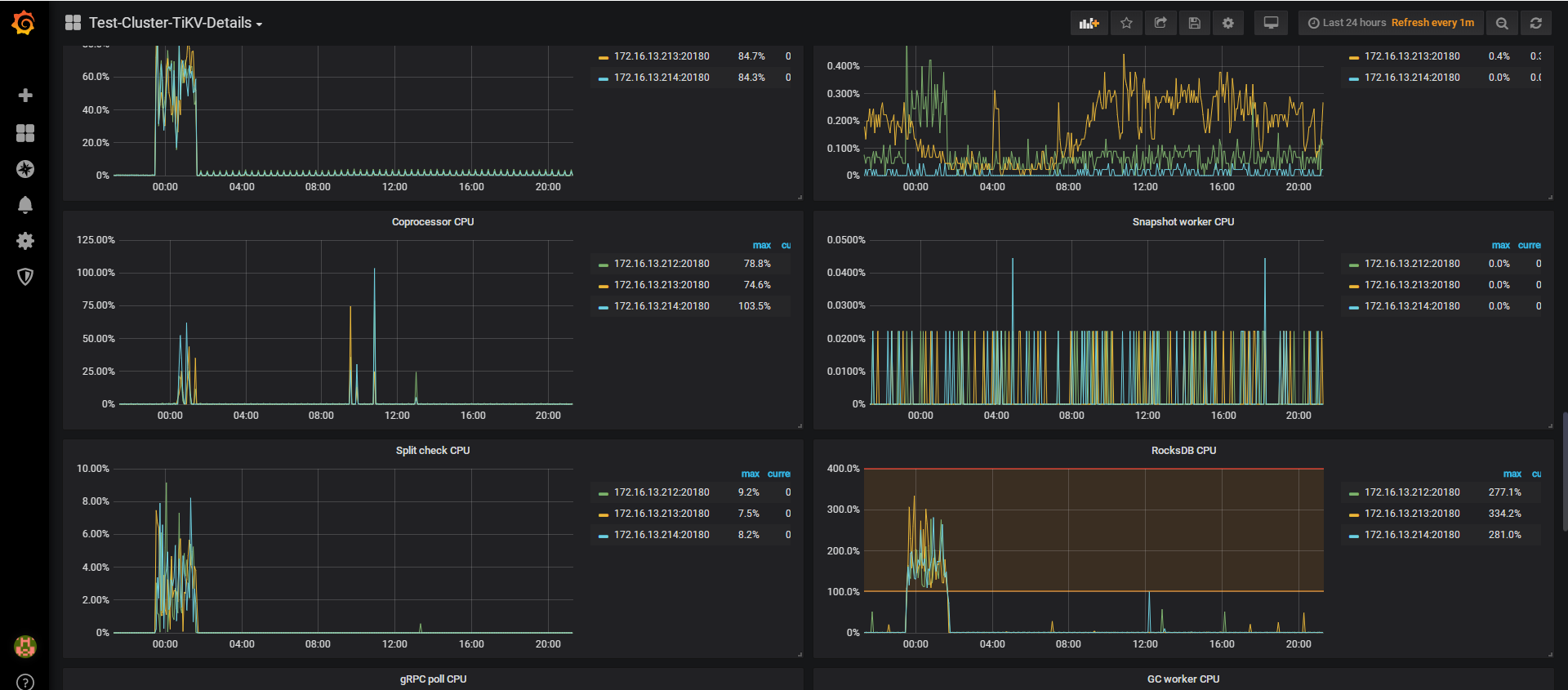
怀疑是热点问题,可以看下监控 TiKV 面板 -> Thread CPU -> Coprocessor CPU ,三个 TiKV 节点的 CPU 是不是不均衡。
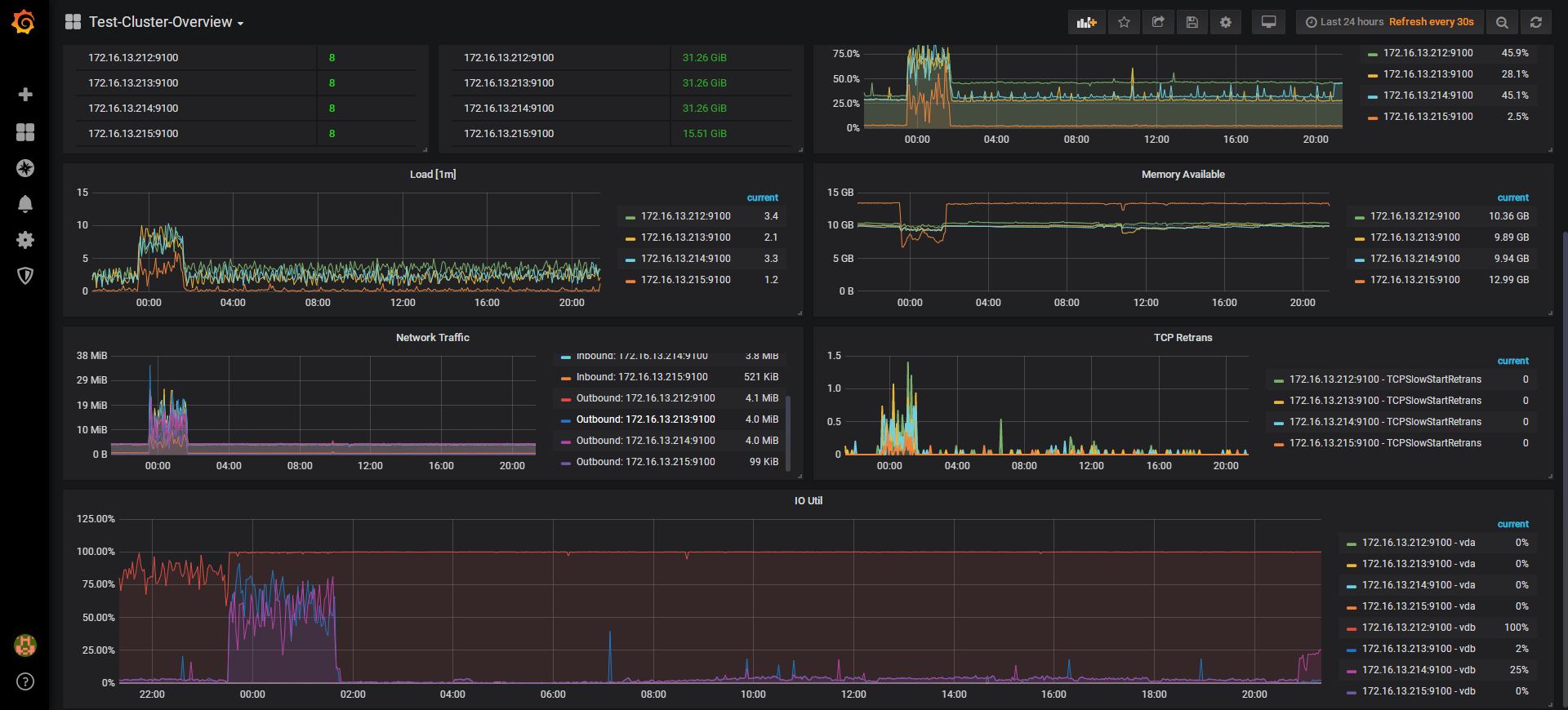

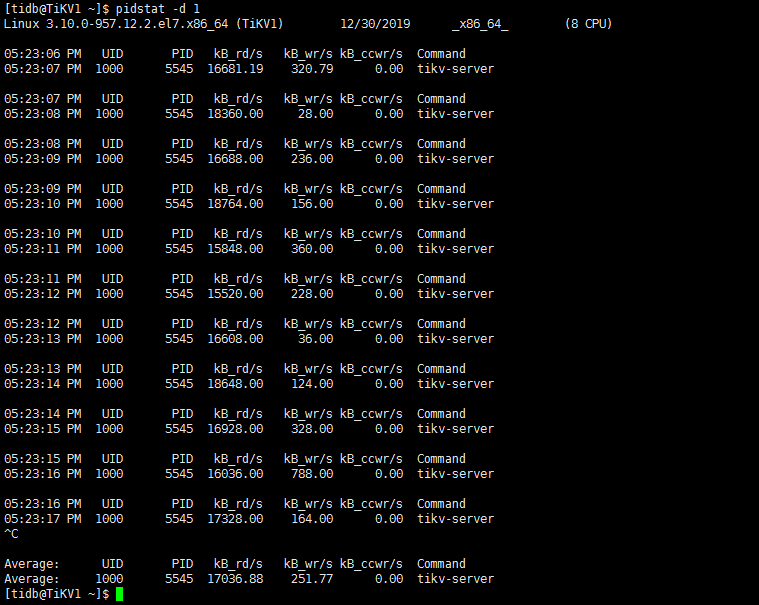
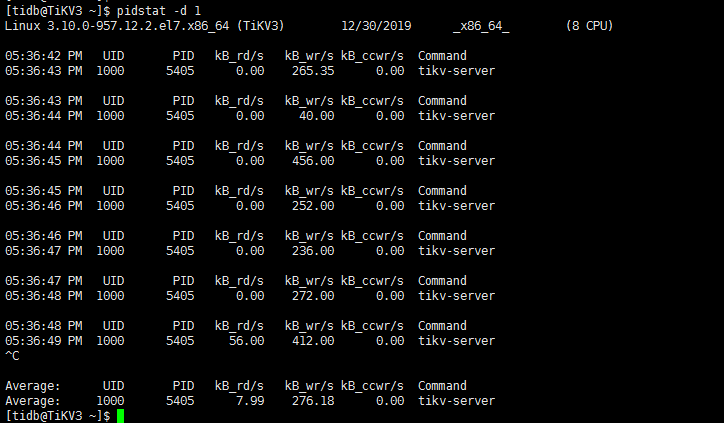
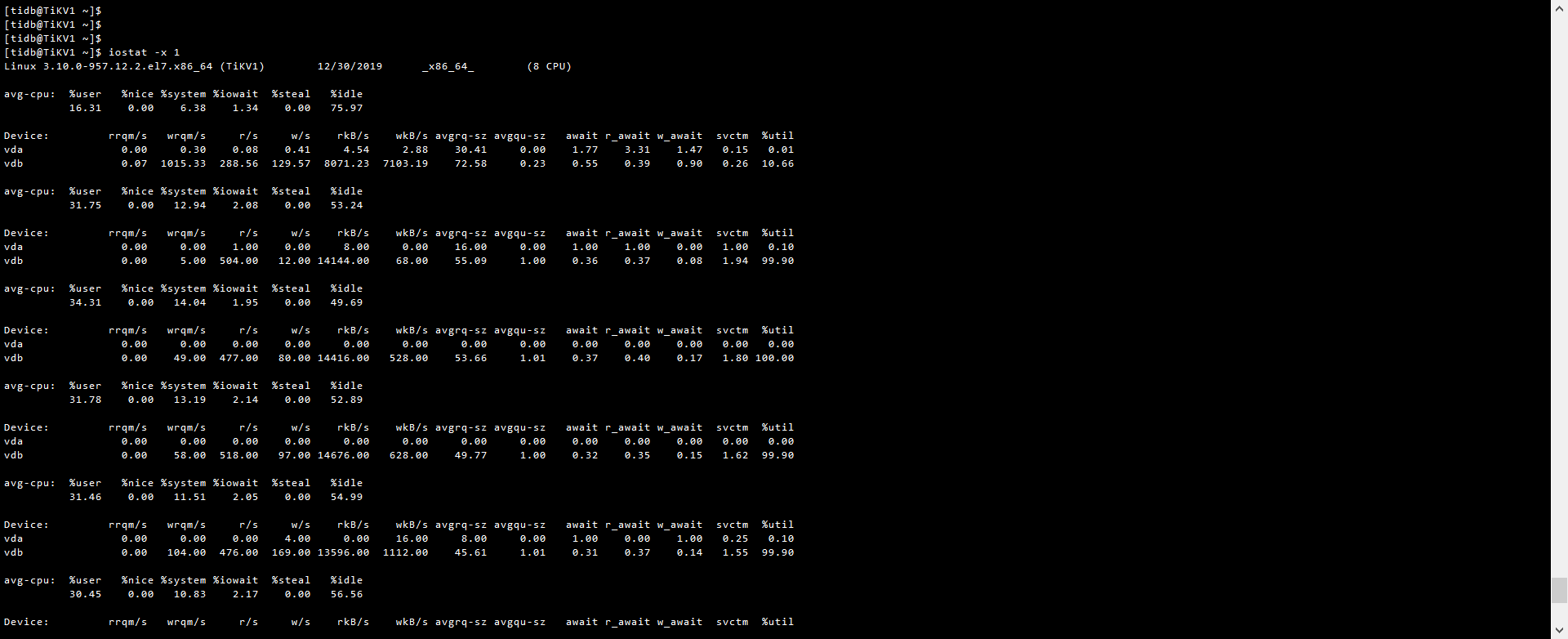
从 iotop 截图看读写流量并不高,在 172.16.13.212 上通过 iostat -x 1 命令确认下 util 是否接近 100%,确认与监控表现一致,再执行下 iotop -o 看下结果;
mariadb 导出报错可以尝试用开源版本的 mydumper 导出,如仍有报错或超时可能跟 mariadb 相关参数设置有关,比如设置
net_read_timeout = 3600
net_write_timeout = 3600
-
vdb 看起来像普通的云盘,建议换用本地 SSD 盘来提升读写性能;
-
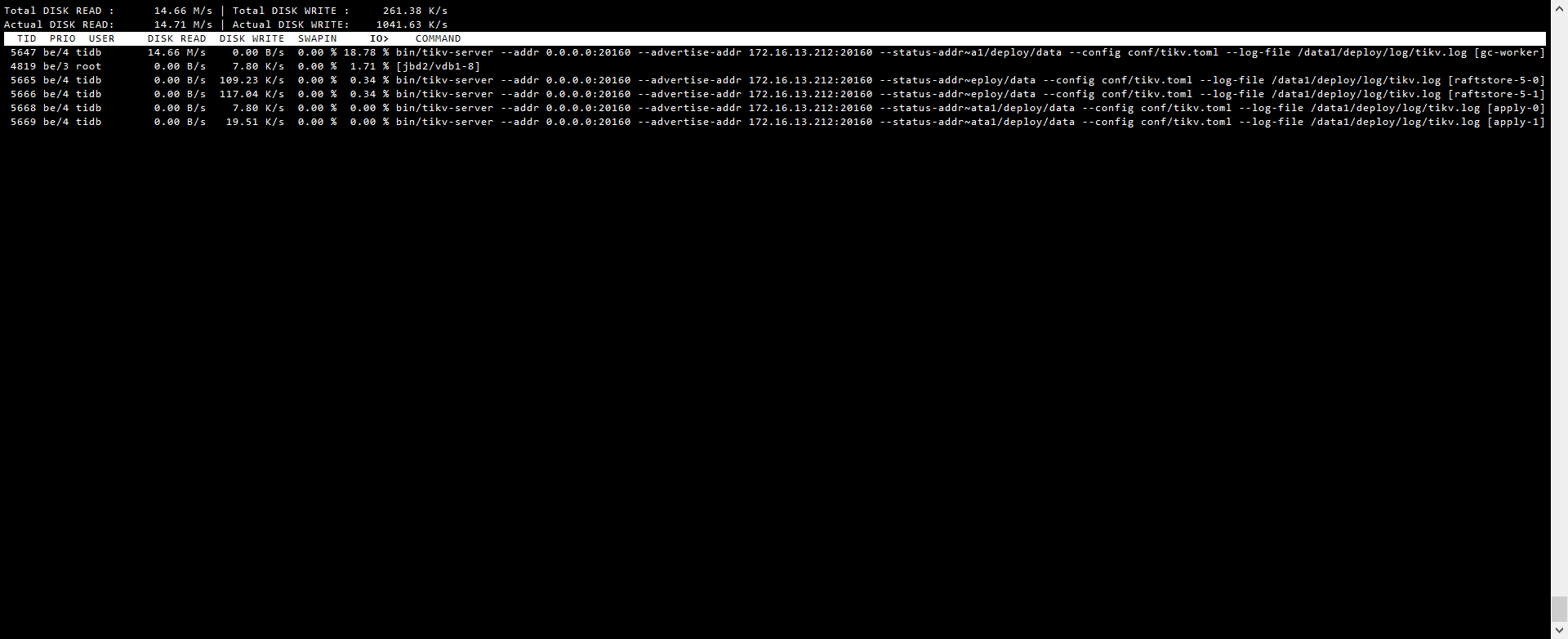
iotop 看主要是 gc worker 读流量相对较高,tikv 监控 thread cpu 面板下的 gc worker cpu 如果繁忙说明有一定的 gc 压力,建议后面升级至 v3.0.6 ,可以对 gc 配置限流。
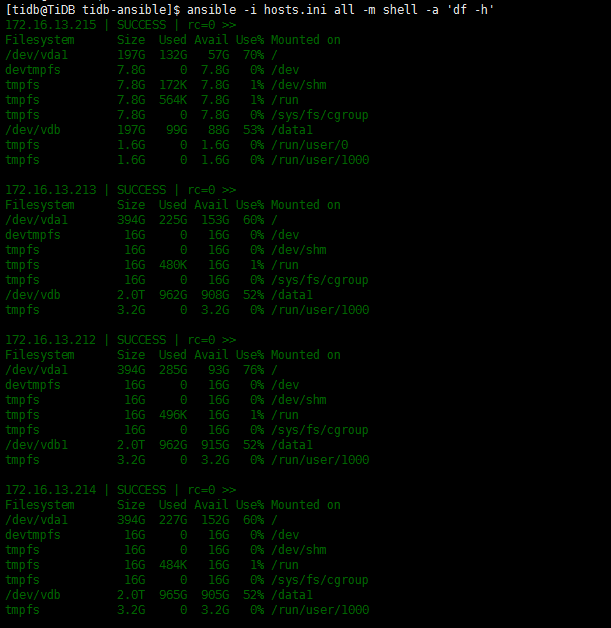
1 三个节点,使用的都是云盘,规格都是一样的,阿里云的ESSD
2 GC信息gc.rar (431.9 KB)
3 从监控数据观察到的,感觉gc worker只在212节点上面读,没有在另外两个tikv节点上面读,负载不均衡
gc 负载不均衡可能是 gc 的表 region 分布不均或 gc 的数据连续性较好
1.确认哪些表有比较多的清理数据操作,通过 table-regions.py 脚本分析下这些表的 region 分布
2.确认是什么类型的操作,比如 delete 按某段连续的主键区间删除数据,可能分布在某一个 region 上面
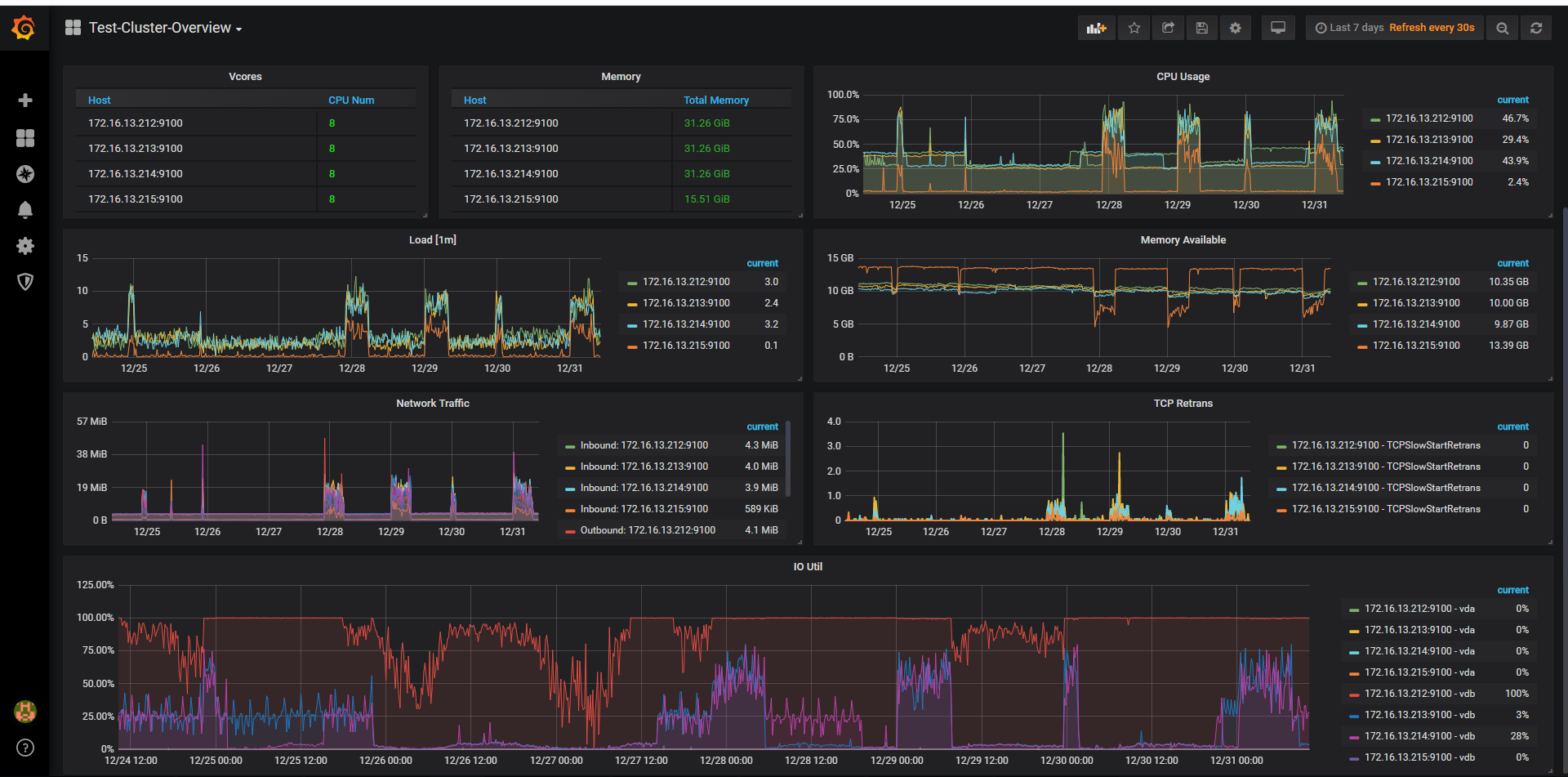

辛苦用 tidb-ansible/roles/machine_benchmark/tasks 下面的 fio 命令单独测一下三个 TiKV 节点盘的 iops,贴下结果。
测试命令方便发一下吗,tikv节点上,是没有tidb-ansible文件的哦。
另外目前212节点上面io util 100%,对测试结果有没有影响呢
在部署的中控机 tidb-ansible/roles/machine_benchmark/tasks 下面有两个文件:fio_randread_write.yml fio_randread.yml ,把里面的 shell 命令拿出来根据部署的路径执行下就可以。