我们的磁盘是阿里云的ESSD云盘(50000 IOPS),不是普通盘呀
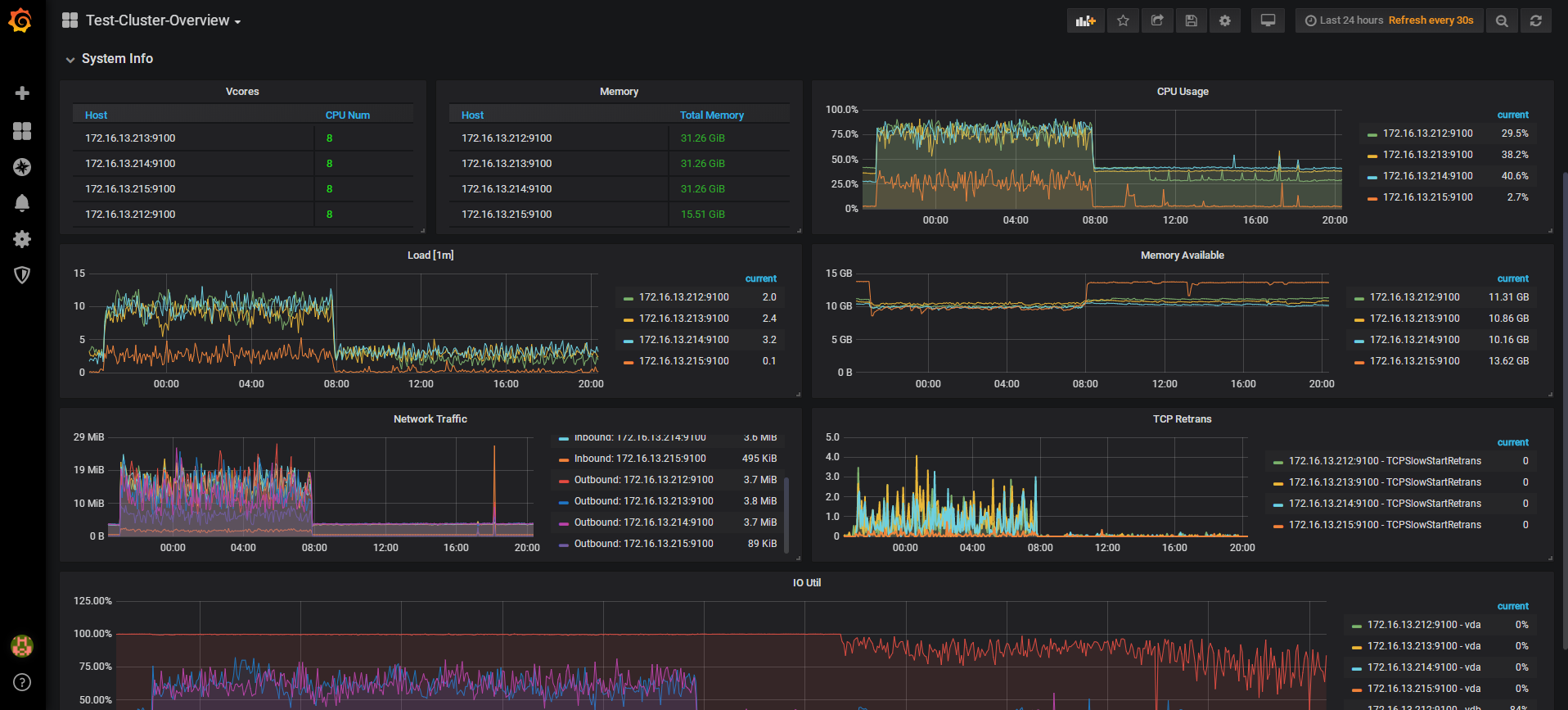
但是看这个磁盘的 io 延迟很高 你看看 overview 的面板 systeminfo 在导入期间的 io memory cpu 的使用情况
fio
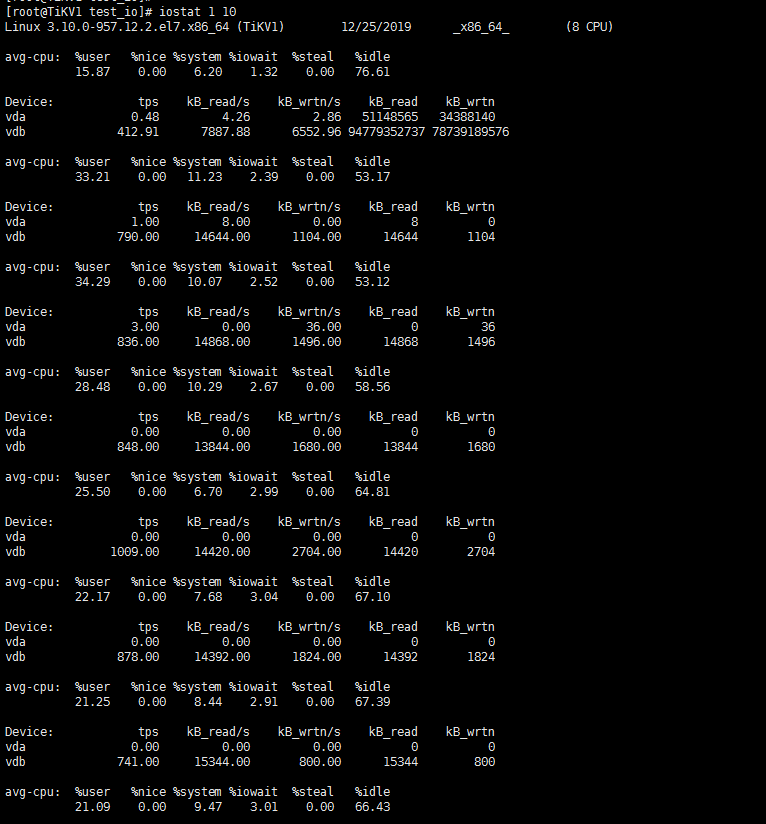
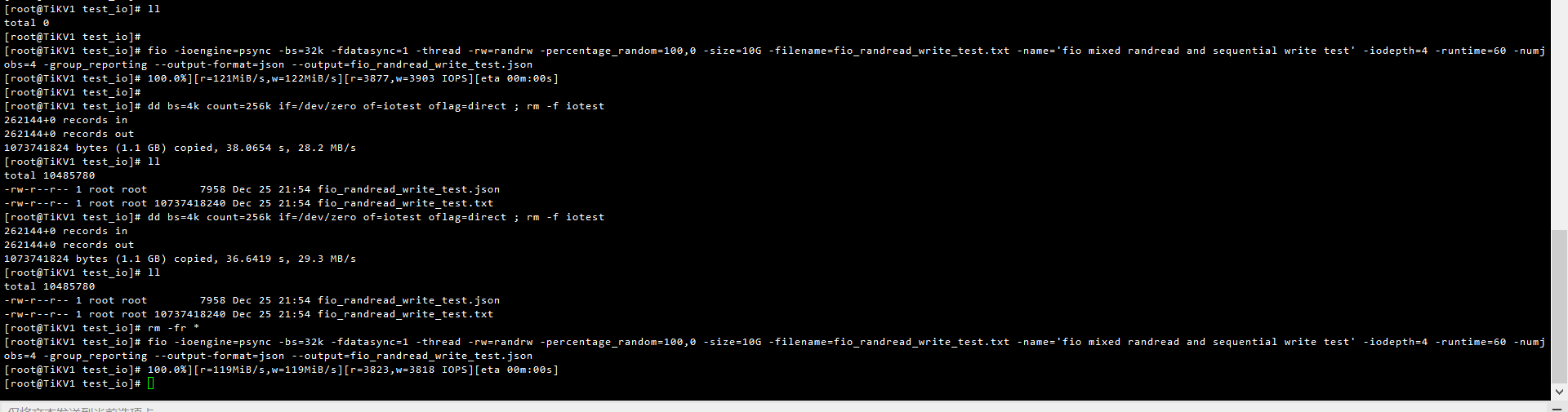
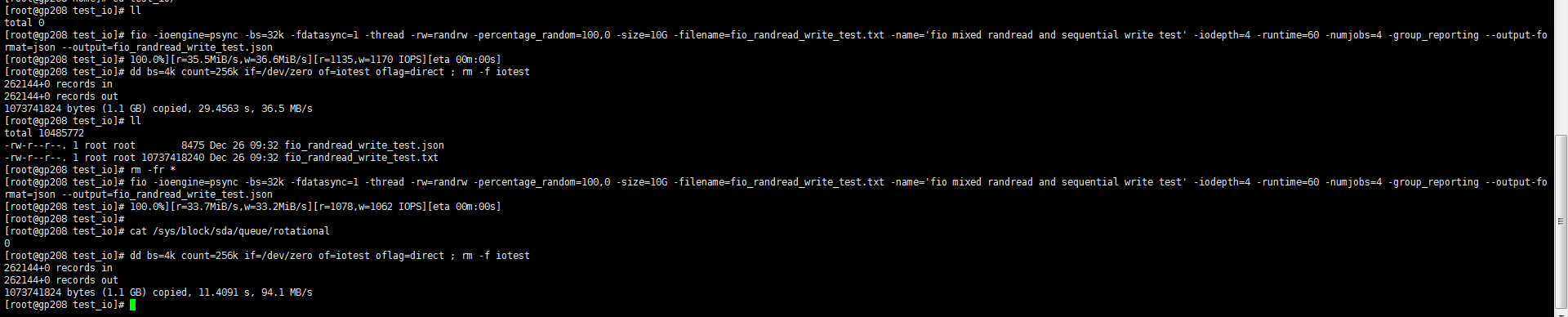
./fio -ioengine=psync -bs=32k -fdatasync=1 -thread -rw=randrw -percentage_random=100,0 -size=10G -filename=fio_randread_write_test.txt -name=‘fio mixed randread and sequential write test’ -iodepth=4 -runtime=60 -numjobs=4 -group_reporting --output-format=json --output=fio_randread_write_test.json
dd
dd bs=4k count=256k if=/dev/zero of=iotest oflag=direct ; rm -f iotest
方便的话,在空的云盘上测试一下这两个测试,看下SSD盘的性能


tidb-ansble 目录下的 log 信息 ansible.log.tar.gz (142.3 KB)
嗯目前看到的 SSD 测试性能比较低,等看下 TiDB 使用的磁盘性能吧,如果觉得性能不足,可以考虑扩容 tikv 分散 io 或者使用性能好的本地 SSD
PS:提供的 tidb-ansible 的日志貌似不是当时部署时候的日志,没有看到 bootstrap 阶段压测磁盘的日志
TIDB磁盘IO性能测试结果,重复测试了两次,测试的时候,系统磁盘IO WAIT 基本上为0!
我的服务器上面,只有一个tidb-ansible的日志呢,用find搜索了,并没有其他的路径有这个日志文件。

这是我本地两个SSD磁盘的测试结果,fio压测结果远小于阿里云的ESSD磁盘测试结果呢
本地A

本地B
另外,有没有计算指标,目前磁盘支持的最大读写情况呢。
我们晚上业务比较少,但是导入数据的时候,IO wait、CPU占用情况和白天的时候一样的。
由于我们的生产不能停机,所以不能使用lightning方式导入。 现在迁移数据200G,晚上8个小时,只能迁移90G左右。
我们的组网结构是
PD\TIDB公用一台服务器,8C16G, 阿里云ESSD磁盘200G
TIKV单独三台,8C32G,阿里云ESSD磁盘2T。
上面的配置,如果都只能闲时迁移90G数据,就真不太科学了
压测的fio_randread_write_test.jsonESSD_fio_randread_write_test.json (7.8 KB) 本地B_SSD_fio_randread_write_test.json (8.3 KB) 本地A_SSD_fio_randread_write_test.json (8.3 KB)
什么时候导入的? 从监控看212的IO从22点到10点一直是100%,这个时间在导入吗? 其他两个盘压力也很多高,在80%多. 另外早上10点以后结束导入了吗? 看212还是在80%左右的使用率,查一下是否有热点写入,能否打散一下. 另外,导入时候3个节点使用率都很高,可以考虑扩容tikv吗?
不知道您是从哪张图上面看到是从22点持续到10点的。我导入时间是从21点到8点的时间段,到了8点,手动kill终止导入了,然后到晚上21点再接着导入的。
从磁盘存储空间使用情况来看,我们的系统写入很少的,下图中的磁盘使用增加,都是loader导入数据,除了这个载入数据,磁盘使用量基本上没有增加,所以应该是没有热点数据写入的
主要是现在tikv的性能和想象中的差异太大,相同的数据,估计一台tikv配置的mysql就能够完全跑起来了,没有比较合适的理由找老板申请资金了:joy:
如果没有写,那也可能是大量的读, 不然磁盘IO为什么这么高. 这样,先查一下212的iostat,pidstat -d 1信息,看下当前的使用情况, 再查一下select * from INFORMATION_SCHEMA.TIDB_HOT_REGIONS;看一下有没有热点region
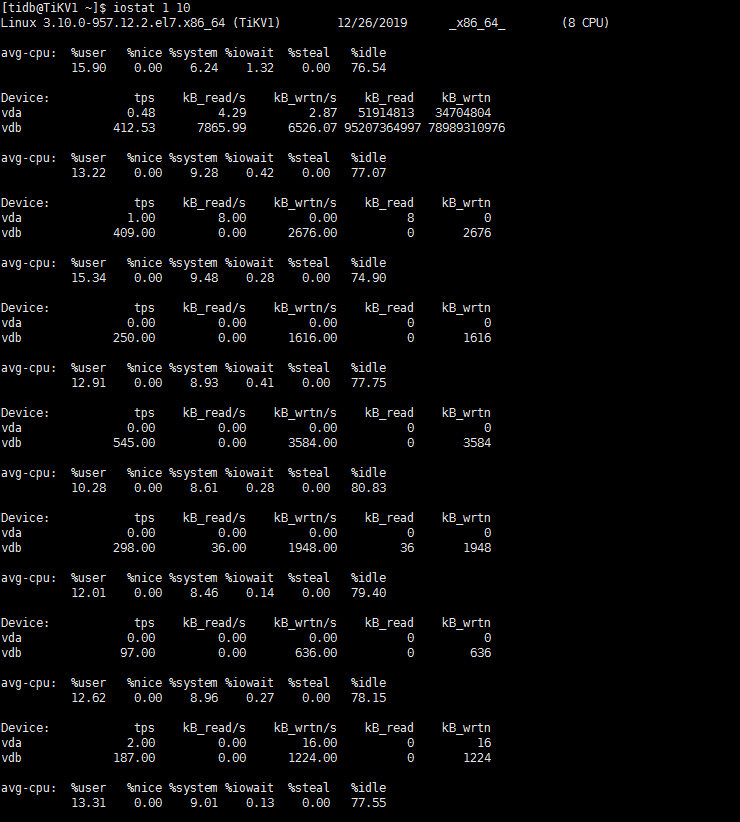
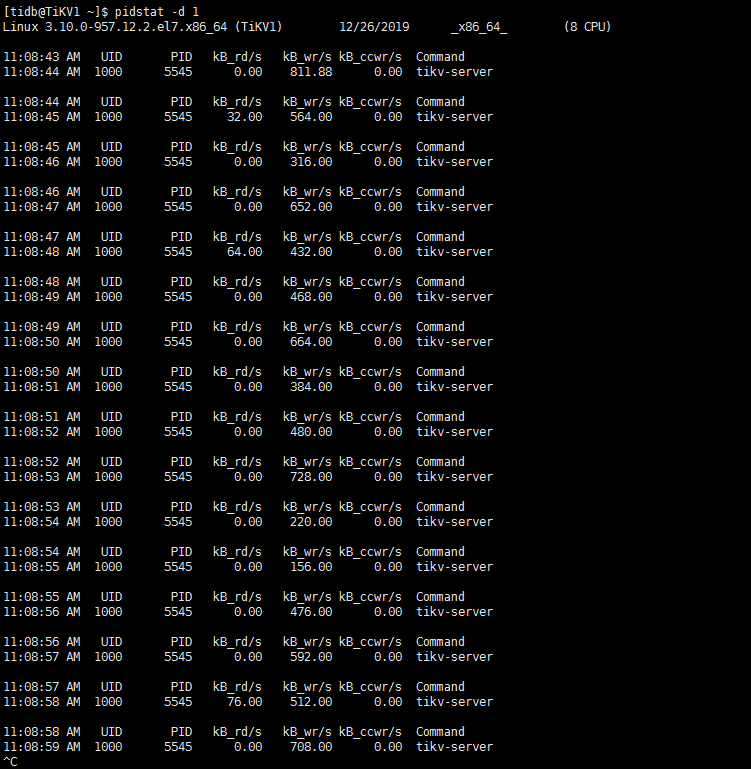
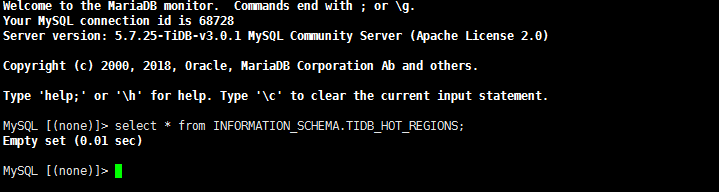
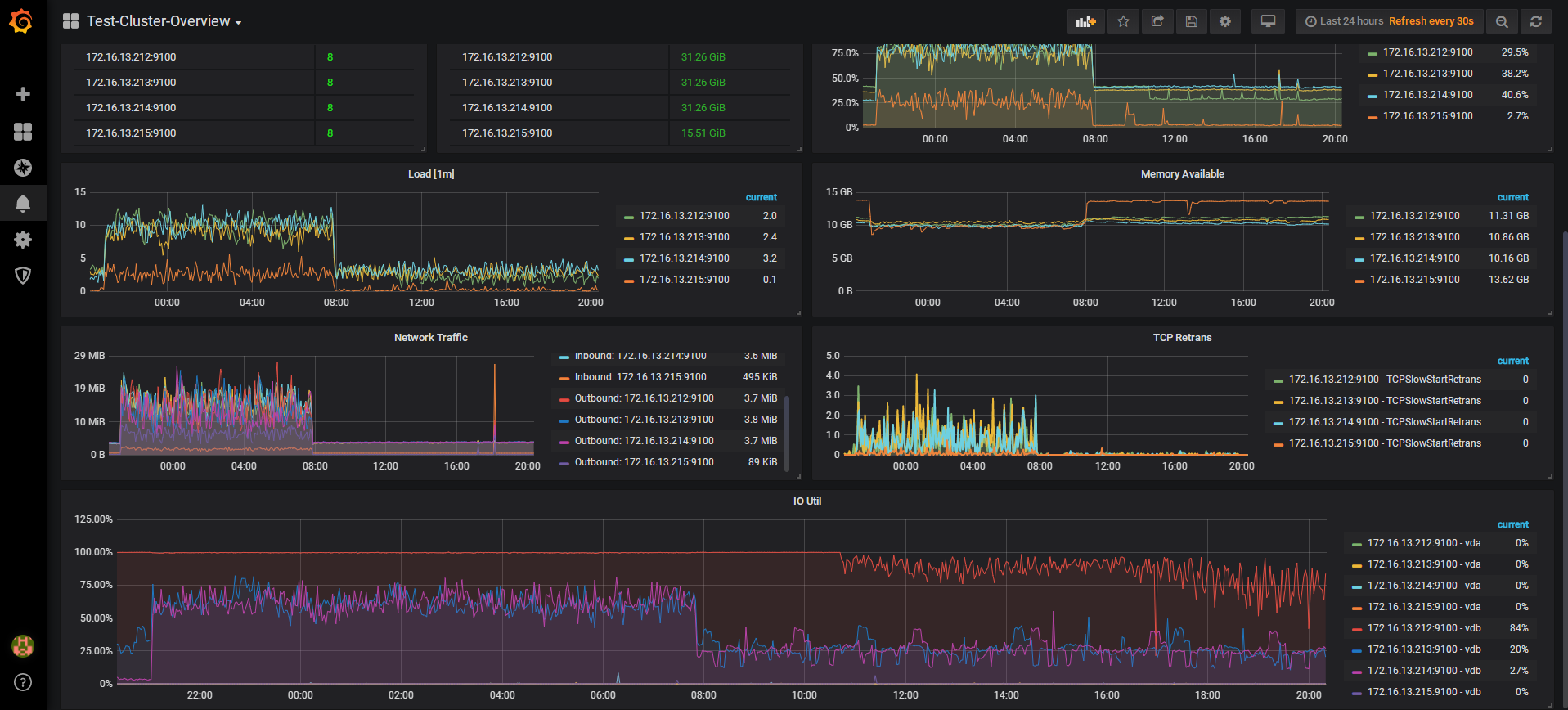
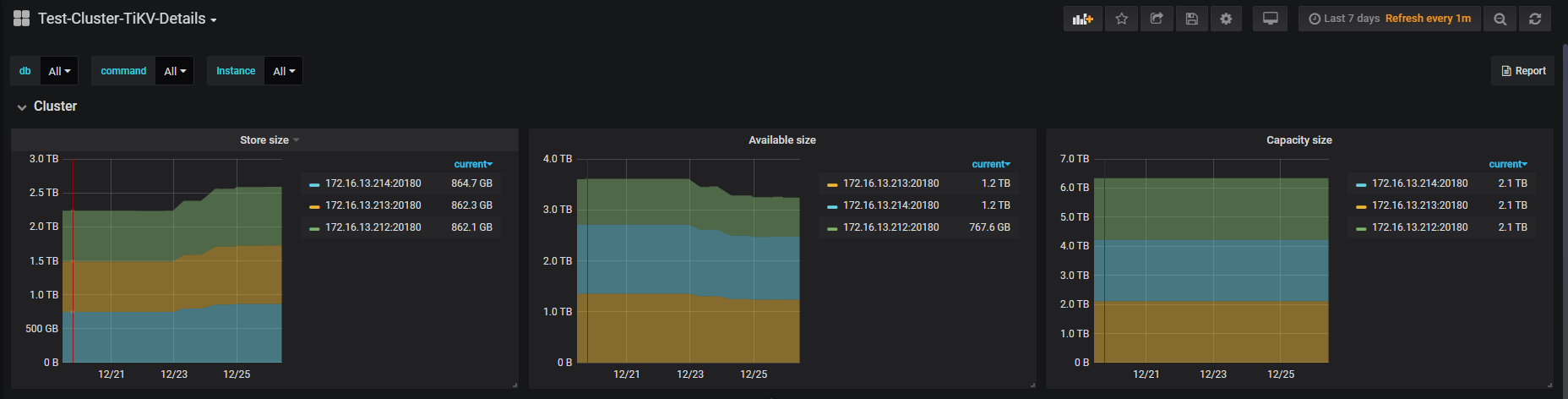
麻烦看一下这里的磁盘使用率,从这里看当时212很高,现在是没有业务了,所以很低吗?
昨晚导入了吗? 如果昨晚导入了,找昨晚导入的时间,从grafana上选择导入的时间,然后使用长图工具,把over-view,tidb,tikv-detail,pd,disk-performance的信息都反馈下
212的磁盘使用情况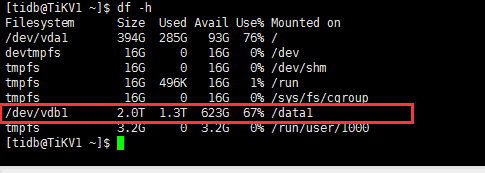
白天系统中一直是有业务的,可能这个时候刚好是低峰,但是这个时候的业务量肯定比晚上21点后要大。
昨天晚上22点,开始导了一小部分数据到tidb中,mydumper的备份文件只有895M,导入整个集群,用了10多分钟,长截图比较大,我放微信群了
截图如下
kv_detail_1.rar (2.4 MB) kv_detail_2.rar (3.5 MB) overview.rar (1.4 MB) pd.rar (1.8 MB) tidb.rar (2.0 MB) disk.rar (393.1 KB)
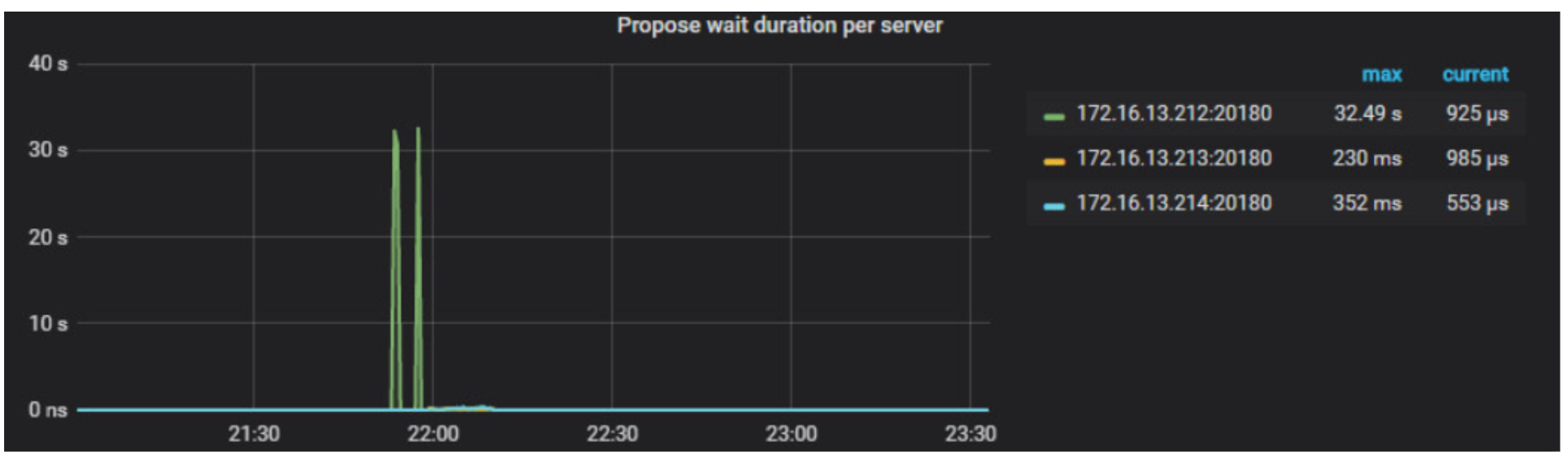
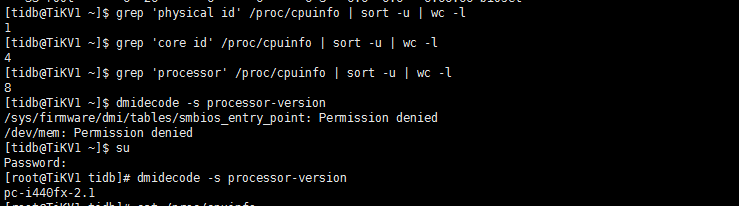
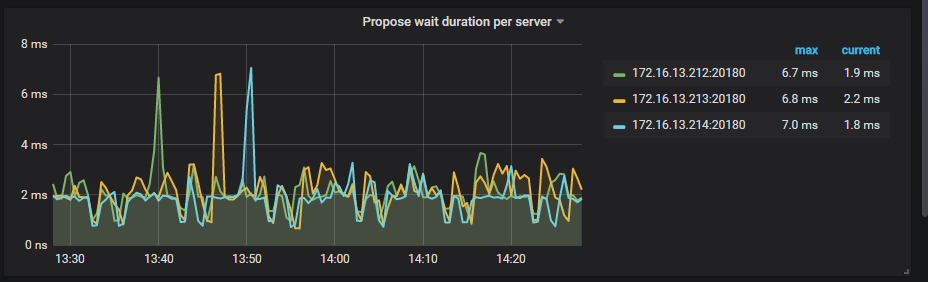
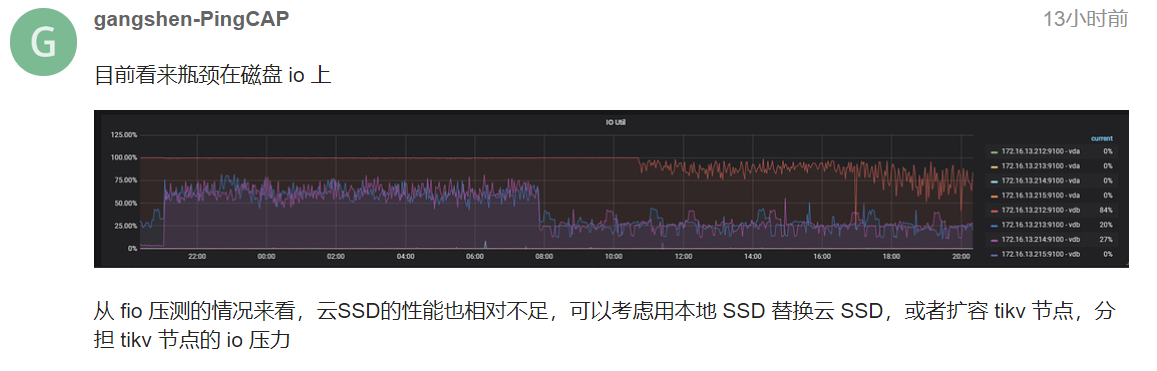
根据监控,查看propose wait duration 212很高30多s, 你的212 tikv配置里raftstore下的store-pool-size是几? 你的机器cpu核数是多少? 另外可以看到监控截图这段时间212的IO 使用率一直100%,可以看一下当前grafana监控的使用率吗?