为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
tidb v5.2.1
【概述】场景+问题概述
通过tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 5000 -T 2000 run建立压测数据
【背景】做过哪些操作
【现象】业务和数据库现象
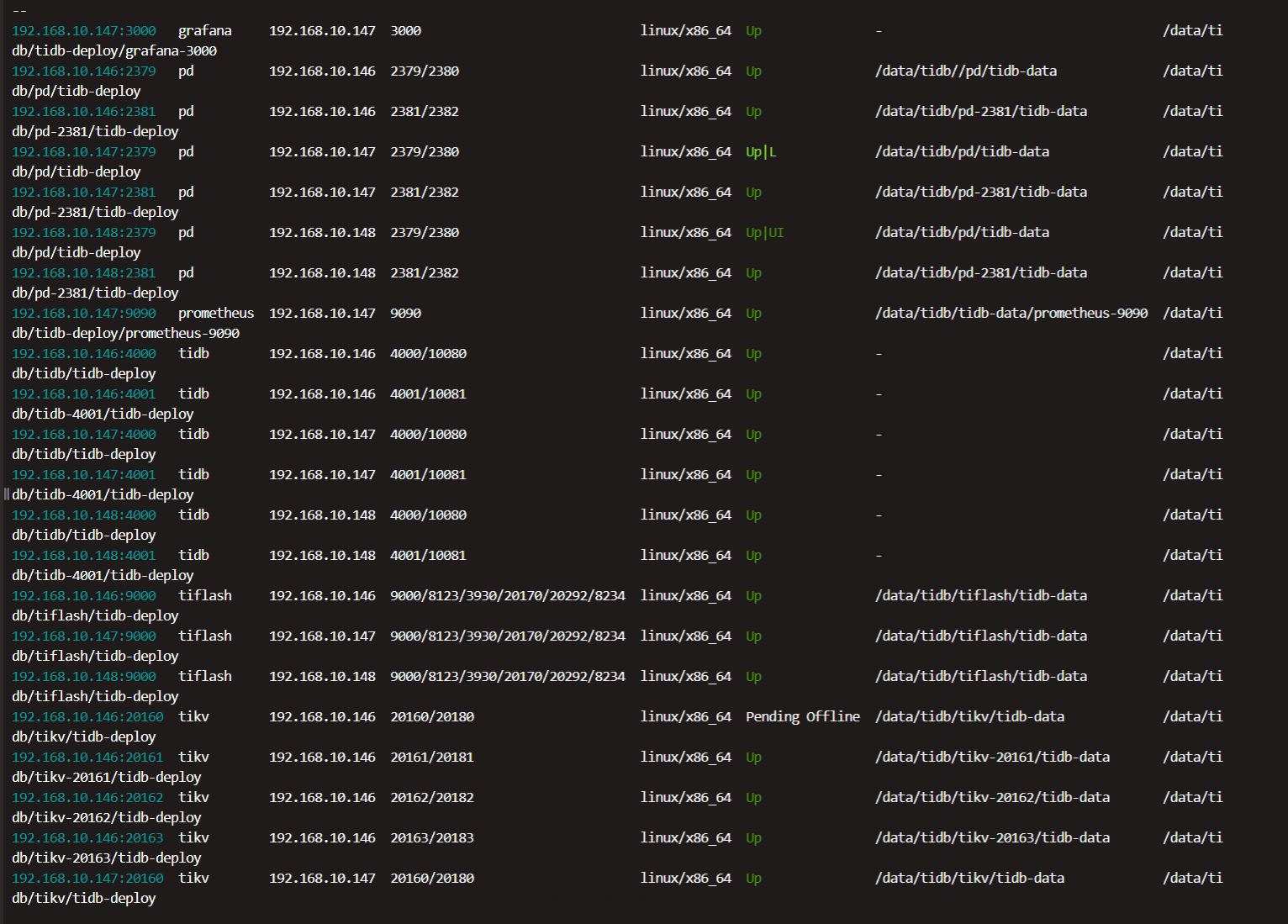
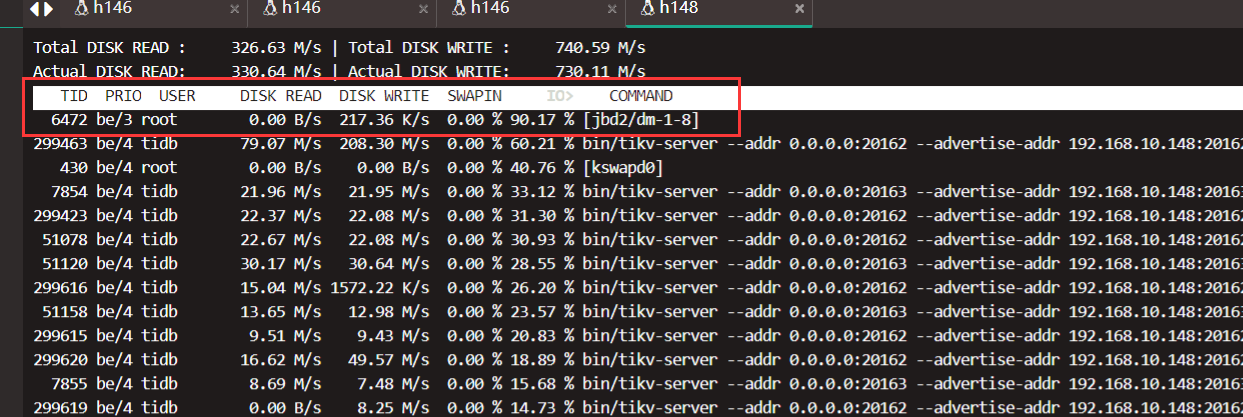
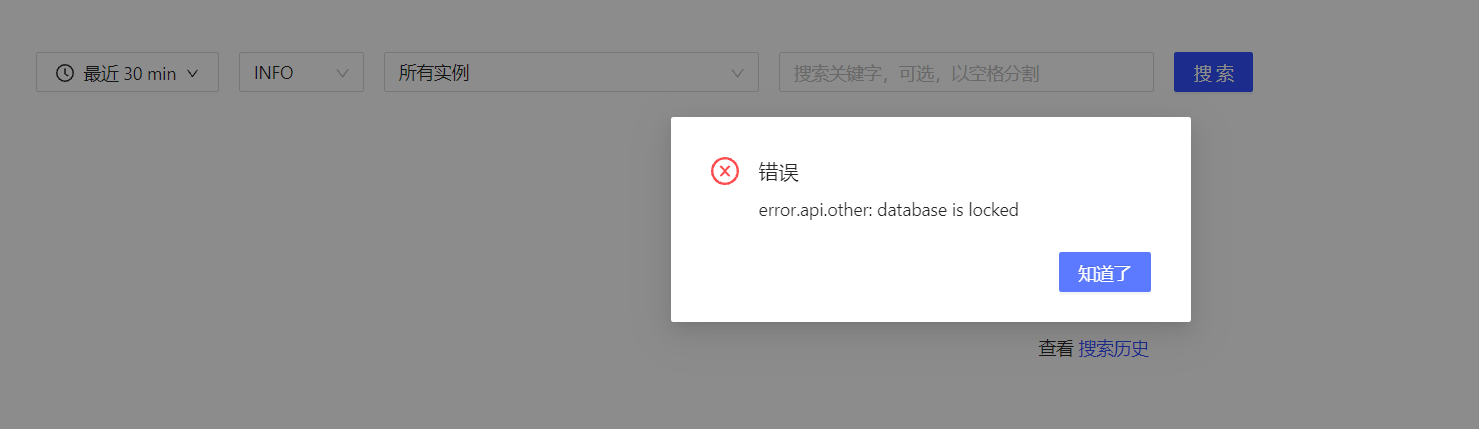
tikv离线1台且报错无法重连,tidb监控后台无法查看日志
【业务影响】
【TiDB 版本】
【附件】
[2021/10/25 16:31:35.783 +08:00] [INFO] [] [“New connected subchannel at 0x7f814442e3c0 for subchannel 0x7f80ac36a200”]
[2021/10/25 16:31:35.783 +08:00] [INFO] [util.rs:544] [“connecting to PD endpoint”] [endpoints=http://192.168.10.147:2379]
[2021/10/25 16:31:35.784 +08:00] [INFO] [util.rs:668] [“connected to PD member”] [endpoints=http://192.168.10.147:2379]
[2021/10/25 16:31:35.784 +08:00] [INFO] [util.rs:202] [“heartbeat sender and receiver are stale, refreshing …”]
[2021/10/25 16:31:35.784 +08:00] [INFO] [tso.rs:148] [“TSO worker terminated”] [receiver_cause=None] [sender_cause=None]
[2021/10/25 16:31:35.784 +08:00] [INFO] [client.rs:136] [“TSO stream is closed, reconnect to PD”]
[2021/10/25 16:31:35.785 +08:00] [INFO] [util.rs:230] [“update pd client”] [via=] [leader=http://192.168.10.147:2379] [prev_via=] [prev_leader=http://192.168.10.147:2379]
[2021/10/25 16:31:35.785 +08:00] [INFO] [util.rs:357] [“trying to update PD client done”] [spend=2.570008ms]
[2021/10/25 16:31:35.785 +08:00] [WARN] [client.rs:138] [“failed to update PD client”] [error=“Other("[components/pd_client/src/util.rs:306]: cancel reconnection due to too small interval")”]
[2021/10/25 16:31:35.785 +08:00] [WARN] [mod.rs:521] [“failed to register addr to pd”] [body=Body(Streaming)] [“status code”=400]
[2021/10/25 16:31:35.785 +08:00] [WARN] [mod.rs:528] [“failed to reconnect pd client”] [err=“Other("[components/pd_client/src/util.rs:306]: cancel reconnection due to too small interval")”]
[2021/10/25 16:31:36.086 +08:00] [INFO] [util.rs:544] [“connecting to PD endpoint”] [endpoints=http://192.168.10.146:2381]
[2021/10/25 16:31:36.086 +08:00] [INFO] [] [“New connected subchannel at 0x7f814382e210 for subchannel 0x7f814305c000”]
[2021/10/25 16:31:36.087 +08:00] [INFO] [util.rs:544] [“connecting to PD endpoint”] [endpoints=http://192.168.10.147:2379]
[2021/10/25 16:31:36.088 +08:00] [INFO] [util.rs:668] [“connected to PD member”] [endpoints=http://192.168.10.147:2379]
[2021/10/25 16:31:36.088 +08:00] [INFO] [util.rs:202] [“heartbeat sender and receiver are stale, refreshing …”]
[2021/10/25 16:31:36.088 +08:00] [INFO] [tso.rs:148] [“TSO worker terminated”] [receiver_cause=None] [sender_cause=None]
[2021/10/25 16:31:36.088 +08:00] [INFO] [util.rs:230] [“update pd client”] [via=] [leader=http://192.168.10.147:2379] [prev_via=] [prev_leader=http://192.168.10.147:2379]
[2021/10/25 16:31:36.088 +08:00] [INFO] [util.rs:357] [“trying to update PD client done”] [spend=2.259162ms]
[2021/10/25 16:31:36.174 +08:00] [FATAL] [lib.rs:465] [“[region 80460] 80462 applying snapshot failed”] [backtrace="stack backtrace:
0: tikv_util::set_panic_hook::{{closure}}
at components/tikv_util/src/lib.rs:464
1: std::panicking::rust_panic_with_hook
at library/std/src/panicking.rs:626
2: std::panicking::begin_panic_handler::{{closure}}
at library/std/src/panicking.rs:519
3: std::sys_common::backtrace::__rust_end_short_backtrace
at library/std/src/sys_common/backtrace.rs:141
4: rust_begin_unwind
at library/std/src/panicking.rs:515
5: std::panicking::begin_panic_fmt
at library/std/src/panicking.rs:457
6: raftstore::store::peer_storage::PeerStorage<EK,ER>::check_applying_snap
at /home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/raftstore/src/store/peer_storage.rs:1388
7: raftstore::store::peer::Peer<EK,ER>::handle_raft_ready_append
at /home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/raftstore/src/store/peer.rs:1580
8: raftstore::store::fsm::peer::PeerFsmDelegate<EK,ER,T>::collect_ready
at /home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/raftstore/src/store/fsm/peer.rs:1058
<raftstore::store::fsm::store::RaftPoller<EK,ER,T> as batch_system::batch::PollHandler<raftstore::store::fsm::peer::PeerFsm<EK,ER>,raftstore::store::fsm::store::StoreFsm>>::handle_normal
at /home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/raftstore/src/store/fsm/store.rs:926
9: batch_system::batch::Poller<N,C,Handler>::poll
at /home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/batch-system/src/batch.rs:414
10: batch_system::batch::BatchSystem<N,C>::start_poller::{{closure}}
at /home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/batch-system/src/batch.rs:541
std::sys_common::backtrace::__rust_begin_short_backtrace
at /rustc/2faabf579323f5252329264cc53ba9ff803429a3/library/std/src/sys_common/backtrace.rs:125
11: std:![]() :Builder::spawn_unchecked::{{closure}}::{{closure}}
:Builder::spawn_unchecked::{{closure}}::{{closure}}
at /rustc/2faabf579323f5252329264cc53ba9ff803429a3/library/std/src/thread/mod.rs:476
<std::panic::AssertUnwindSafe as core::ops::function::FnOnce<()>>::call_once
at /rustc/2faabf579323f5252329264cc53ba9ff803429a3/library/std/src/panic.rs:347
std::panicking::try::do_call
at /rustc/2faabf579323f5252329264cc53ba9ff803429a3/library/std/src/panicking.rs:401
std::panicking::try
at /rustc/2faabf579323f5252329264cc53ba9ff803429a3/library/std/src/panicking.rs:365
std::panic::catch_unwind
at /rustc/2faabf579323f5252329264cc53ba9ff803429a3/library/std/src/panic.rs:434
std:![]() :Builder::spawn_unchecked::{{closure}}
:Builder::spawn_unchecked::{{closure}}
at /rustc/2faabf579323f5252329264cc53ba9ff803429a3/library/std/src/thread/mod.rs:475
core::ops::function::FnOnce::call_once{{vtable.shim}}
at /rustc/2faabf579323f5252329264cc53ba9ff803429a3/library/core/src/ops/function.rs:227
12: <alloc::boxed::Box<F,A> as core::ops::function::FnOnce>::call_once
at /rustc/2faabf579323f5252329264cc53ba9ff803429a3/library/alloc/src/boxed.rs:1572
<alloc::boxed::Box<F,A> as core::ops::function::FnOnce>::call_once
at /rustc/2faabf579323f5252329264cc53ba9ff803429a3/library/alloc/src/boxed.rs:1572
std::sys::unix:![]()
![]()
![]() :thread_start
:thread_start
at library/std/src/sys/unix/thread.rs:91
13: start_thread
14: __clone
"] [location=/home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/raftstore/src/store/peer_storage.rs:1388] [thread_name=raftstore-1-0]
-
TiUP Cluster Display 信息
-
TiUP Cluster Edit Config 信息
-
TiDB- Overview 监控
- 对应模块日志(包含问题前后1小时日志)