为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0-rc
- 【问题描述】:
这4台是tikv 节点,少部分时间是70%左右,一般情况下都是100%

而且这几个节点的mem使用率都是挺高的:

以上情况,是升级前(v3.0.9) 也有的。
之所以纠结这个问题,是在线上集群v2.1.15 没有tikv节点 IO 过高, tikv 节点mem使用过高的情况。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
这4台是tikv 节点,少部分时间是70%左右,一般情况下都是100%
而且这几个节点的mem使用率都是挺高的:
以上情况,是升级前(v3.0.9) 也有的。
之所以纠结这个问题,是在线上集群v2.1.15 没有tikv节点 IO 过高, tikv 节点mem使用过高的情况。
补充: 在tikv节点上执行iostat 命令 iostat -d -x -k 1 10
Linux 3.10.0-957.21.3.el7.x86_64 (xx-tikv3-xx) 04/27/2020 _x86_64_ (16 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.20 0.21 0.43 4.37 2.78 22.17 0.06 1.18 2.71 0.43 95.25 6.14
vdb 1.58 1445.51 72.13 718.50 1811.84 13072.44 37.65 0.69 0.17 1.47 0.05 0.87 68.95
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 368.00 0.00 653.00 0.00 4492.00 13.76 0.87 0.22 0.00 0.22 1.31 85.60
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 1208.00 197.00 563.00 12536.00 16088.00 75.33 3.01 2.84 8.66 0.81 1.29 97.80
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 348.00 39.00 559.00 2372.00 4996.00 24.64 1.14 0.49 3.64 0.27 1.59 95.20
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 231.00 0.00 390.00 0.00 2632.00 13.50 0.90 0.20 0.00 0.20 2.29 89.50
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 146.00 0.00 276.00 0.00 1724.00 12.49 0.81 0.19 0.00 0.19 2.94 81.10
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 381.00 0.00 615.00 0.00 4168.00 13.55 0.89 0.20 0.00 0.20 1.42 87.40
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 474.00 2.00 699.00 76.00 5208.00 15.08 0.99 0.20 0.50 0.20 1.40 97.90
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 274.00 0.00 441.00 0.00 2964.00 13.44 0.96 0.20 0.00 0.20 2.19 96.40
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 329.00 1.00 571.00 16.00 3680.00 12.92 0.97 0.17 1.00 0.17 1.69 96.40
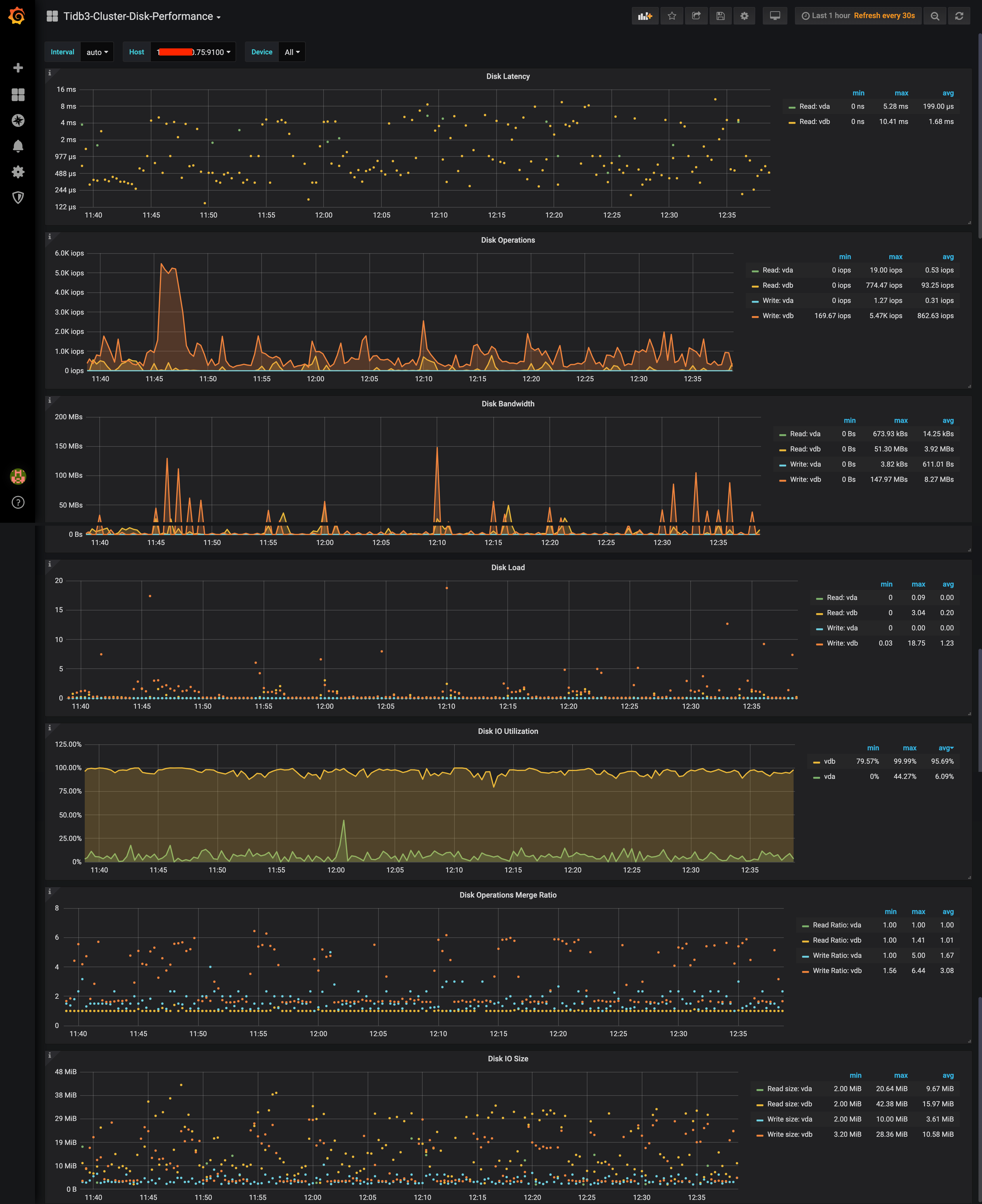
麻烦上传 over-view , disk-performance,node_exporter监控,多谢
(1)、chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
(2)、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3)、使用这个 full-page-screen-capture 插件进行截屏保存
node_exporter监控
screencapture-localhost-3000-d-000000001-tidb3-cluster-node-exporter-2020-04-27-12_34_15.png.zip (2.6 MB)
overview
screencapture-localhost-3000-d-eDbRZpnWk-tidb3-cluster-overview-2020-04-27-12_46_02.png.zip (3.9 MB)
您好,希望可以把这个io降下来,目前看,应该是不太正常的,要如何做呢
4.0的集群是空置状态,准备把服务流量向新集群倾斜。
不知道这个版本的改动 是否 有bug? 因为 新老集群的配置/节点 全是一样的,唯独IO 这里。
4.0 集群 默认开了什么参数嘛?
不是虚机。
iotop -oP 结果,新老集群都是 bin/tikv-server
老集群的iotop 发现:读:1~10 mb/s , 写: 1- 10mb/s 新集群的iotop 发现:读:10+ mb/s, 写:20 mb/s
两边都是DM 服务在用,同步的源头都一样。 老集群,还有很多其他服务在用
补充一下:
上午iotop在tikv节点上:
Total DISK READ : 19.33 K/s | Total DISK WRITE : 47.22 M/s
Actual DISK READ: 19.33 K/s | Actual DISK WRITE: 51.00 M/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
32131 be/3 root 0.00 B/s 27.06 K/s 0.00 % 17.02 % [jbd2/vdb1-8]
30437 be/4 tidb 0.00 B/s 692.02 K/s 0.00 % 2.50 % bin/tikv-server --addr 0.0.0.0:20160 ~loy/tidb/log/tikv.log [raftstore-1-1]
30436 be/4 tidb 0.00 B/s 688.16 K/s 0.00 % 2.49 % bin/tikv-server --addr 0.0.0.0:20160 ~loy/tidb/log/tikv.log [raftstore-1-0]
30370 be/4 tidb 0.00 B/s 45.61 M/s 0.00 % 1.81 % bin/tikv-server --addr 0.0.0.0:20160 ~ploy/tidb/log/tikv.log [rocksdb:low1]
1917 be/4 tidb 19.33 K/s 0.00 B/s 0.00 % 0.05 % bin/tikv-server --addr 0.0.0.0:20160 ~y/tidb/log/tikv.log [sched-worker-po]
30439 be/4 tidb 0.00 B/s 154.64 K/s 0.00 % 0.02 % bin/tikv-server --addr 0.0.0.0:20160 ~a1/deploy/tidb/log/tikv.log [apply-0]
30440 be/4 tidb 0.00 B/s 92.79 K/s 0.00 % 0.01 % bin/tikv-server --addr 0.0.0.0:20160 ~a1/deploy/tidb/log/tikv.log [apply-1]
1841 be/4 tidb 0.00 B/s 0.00 B/s 0.00 % 0.00 % bin/blackbox_exporter --web.listen-ad~=info --config.file=conf/blackbox.yml
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd --switched-root --system --deserialize 22
jbd2总是占的挺高,观察了一段时间,发现在15 - 20%左右。
我怀疑是这个jbd2的bug,但是还没有到100%。见:https://www.cnblogs.com/z-books/p/6612685.html
另外,观察到tikv节点的free内存一直很少,系统内存32G
free -m
total used free shared buff/cache available
Mem: 30985 16119 2302 0 12562 14430
Swap: 0 0
总是从2G - > 0 ,再回到2G。
猜测: TiKV 可用内存太小,内存中能缓存/缓冲的数据不多,所以需要更多的I/O。
TiKV 可以改啥机制,能少用点内存?
好的,再补充一下现象。同事的观察:
持续观察了下,每次 tikv-server 的 io 涨上去后,jbd2/vdb1-8 的 io 也会涨上去,
尤其是 tikv-server io 在 20% 左右时,jbd2/vdb1-8 io 就会到 80% 左右。
附图:
正在分析请稍等
补充下发生这种现象的原因:
当大量数据写入时, tikv-server 的 io 会上涨,但是此时 jbd2/vdb1-8 涨的更加厉害,导致系统io util 到100%
这应该是你们4.0-rc的bug ?
1、jbd2/disk-name 是操作系统的的进程,不是 tidb 自身派生出来的,jbd2/disk-name 进程是文件系统 ext4 的写日志进程
2、io util 高表示当前环境下存在密集的写入操作,并且看到磁盘 vdb 的带宽最高有达到 140+M ,还是比较大的。
3、上面有提到在使用 DM 进行同步 , DM 同步的 worker-count 是如何配置的?
DM目前同步了2个MySQL从库,一共设置了7个task。
都是用的默认worker-count 参数,其中一个task 设置了 syncer-thread: 48
其余6个task 都是用的默认值。
我觉得tidb v4.0-rc 在大量写入的情况下,tikv节点的io暴涨100%,这个你们应该可以复现出来。。对比v2.1.x,相同的机器配置,则不会暴涨至100%