【 TiDB 使用环境】
【概述】:tikv节点无法下线
【背景】:tidb 版本v4.0.6时下线1个tikv节点,leader_count和region_count已经为0但是一直是下线中Offline状态;期间在其他节点上做过"tikv-ctl --db /data1/tidb-deploy/data/tikv-20160/db/ unsafe-recover remove-fail-stores -s 89241 --all-regions" 但是依旧无法下线; 升级到v5.1.1依旧无法解决; 再次升级到v5.2.0,在线/离线修复,问题依旧。
【现象】:业务正常,但是访问information_schema较慢
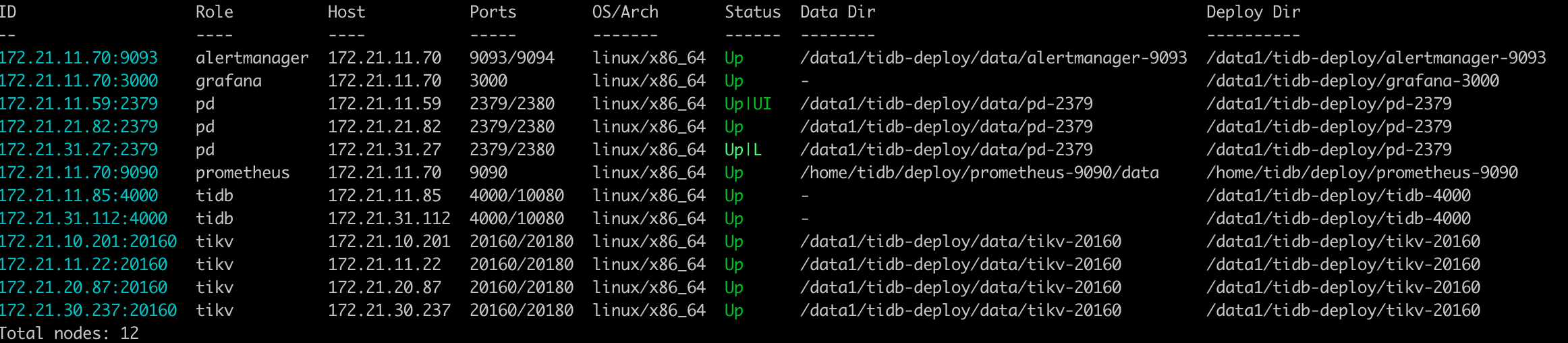
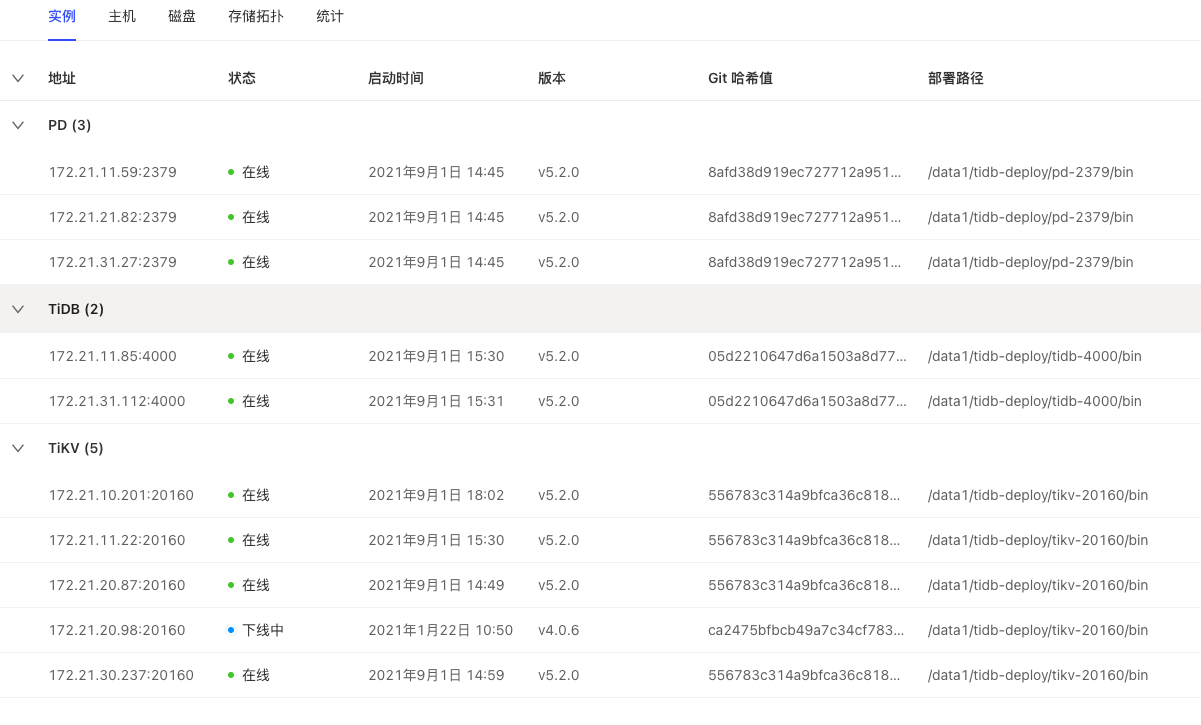
【问题】:tikv一个节点始终无法下线
【业务影响】:无影响
【TiDB 版本】:v5.2.0
【TiDB Operator 版本】:
【K8s 版本】:
【附件】:
- 相关日志、配置文件、Grafana 监控(https://metricstool.pingcap.com/)
附件1:
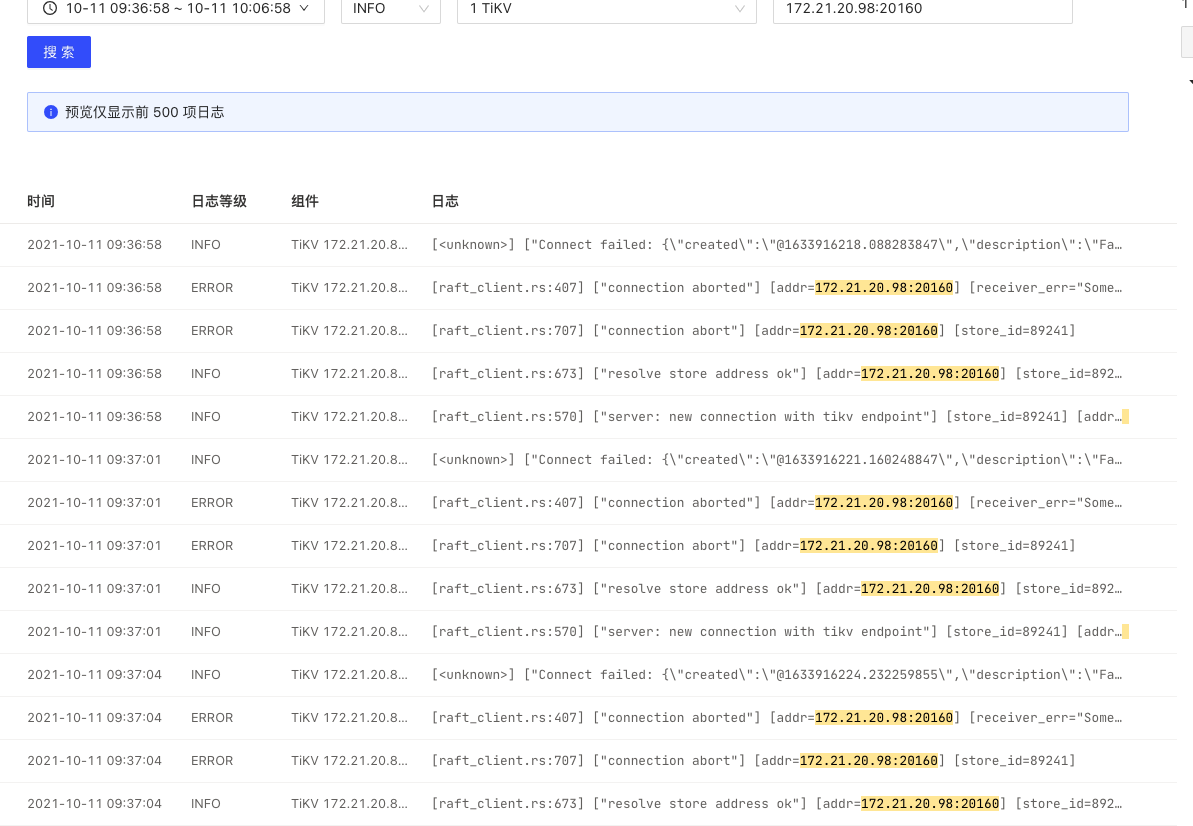
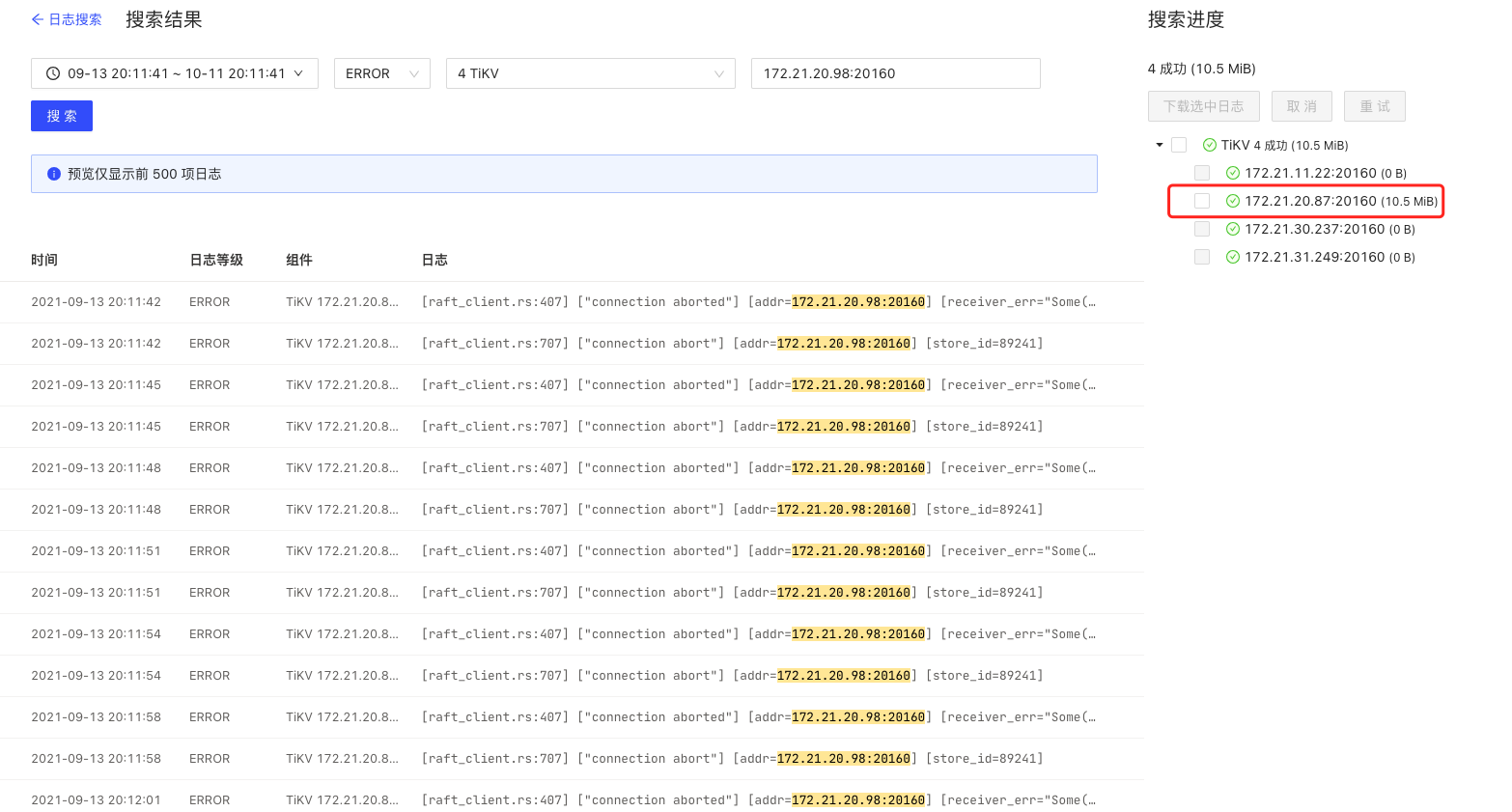
dashboard里看到的tikv错误日志:
2021-09-03 11:05:52 ERROR TiKV 172.21.20.87:20160
[raft_client.rs:407] [“connection aborted”] [addr=172.21.20.98:20160] [receiver_err=“Some(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: “failed to connect to all addresses”, details: [] }))”] [sink_error=“Some(RpcFinished(Some(RpcStatus { code: 14-UNAVAILABLE, message: “failed to connect to all addresses”, details: [] })))”] [store_id=89241]
2021-09-03 11:05:52 ERROR TiKV 172.21.20.87:20160 [raft_client.rs:707] [“connection abort”] [addr=172.21.20.98:20160] [store_id=89241]
升级到v5.2.0版本后,remove-fail-stores 报错:
./tikv-ctl --data-dir /data1/tidb-deploy/data/tikv-20160/db/ --config /data1/tidb-deploy/tikv-20160/conf/tikv.toml unsafe-recover remove-fail-stores -s 89241 --all-regions
[2021/09/03 03:33:06.791 +00:00] [INFO] [mod.rs:118] [“encryption: none of key dictionary and file dictionary are found.”]
[2021/09/03 03:33:06.792 +00:00] [INFO] [mod.rs:479] [“encryption is disabled.”]
[2021/09/03 03:33:06.796 +00:00] [WARN] [config.rs:587] [“compaction guard is disabled due to region info provider not available”]
[2021/09/03 03:33:06.796 +00:00] [WARN] thread ‘[main’ panicked at ‘config.rscalled Result::unwrap() on an Err value: Os { code: 2, kind: NotFound, message: “No such file or directory” }:’, 682cmd/tikv-ctl/src/main.rs]: [121":compaction guard is disabled due to region info provider not available57"
note: run with RUST_BACKTRACE=1 environment variable to display a backtrace
]
store信息:
Starting component ctl: /home/tidb/.tiup/components/ctl/v5.2.0/ctl pd -u 172.21.11.59:2379 store
{
“count”: 5,
“stores”: [
{
“store”: {
“id”: 89241,
“address”: “172.21.20.98:20160”,
“state”: 1,
“version”: “4.0.6”,
“status_address”: “172.21.20.98:20180”,
“git_hash”: “ca2475bfbcb49a7c34cf783596acb3edd05fc88f”,
“start_timestamp”: 1611283801,
“deploy_path”: “/data1/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1611382452859916876,
“state_name”: “Offline”
},
“status”: {
“capacity”: “0B”,
“available”: “0B”,
“used_size”: “0B”,
“leader_count”: 0,
“leader_weight”: 0,
“leader_score”: 0,
“leader_size”: 0,
“region_count”: 0,
“region_weight”: 0,
“region_score”: 0,
“region_size”: 0,
“slow_score”: 0,
“start_ts”: “2021-01-22T02:50:01Z”,
“last_heartbeat_ts”: “2021-01-23T06:14:12.859916876Z”,
“uptime”: “27h24m11.859916876s”
}
},
{
“store”: {
“id”: 103455,
“address”: “172.21.20.87:20160”,
“version”: “5.2.0”,
“status_address”: “172.21.20.87:20180”,
“git_hash”: “556783c314a9bfca36c818256182eeef364120d7”,
“start_timestamp”: 1630478941,
“deploy_path”: “/data1/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1630649848209204836,
“state_name”: “Up”
},
“status”: {
“capacity”: “3.401TiB”,
“available”: “1.107TiB”,
“used_size”: “1.889TiB”,
“leader_count”: 43497,
“leader_weight”: 1,
“leader_score”: 43497,
“leader_size”: 3628871,
“region_count”: 129897,
“region_weight”: 1,
“region_score”: 405987906.9967766,
“region_size”: 10827076,
“slow_score”: 1,
“start_ts”: “2021-09-01T06:49:01Z”,
“last_heartbeat_ts”: “2021-09-03T06:17:28.209204836Z”,
“uptime”: “47h28m27.209204836s”
}
},
{
“store”: {
“id”: 135592,
“address”: “172.21.10.201:20160”,
“version”: “5.2.0”,
“status_address”: “172.21.10.201:20180”,
“git_hash”: “556783c314a9bfca36c818256182eeef364120d7”,
“start_timestamp”: 1630490575,
“deploy_path”: “/data1/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1630649852080571655,
“state_name”: “Up”
},
“status”: {
“capacity”: “3.401TiB”,
“available”: “1.106TiB”,
“used_size”: “1.897TiB”,
“leader_count”: 43494,
“leader_weight”: 1,
“leader_score”: 43494,
“leader_size”: 3551219,
“region_count”: 135567,
“region_weight”: 1,
“region_score”: 407231097.17386436,
“region_size”: 11097255,
“slow_score”: 1,
“start_ts”: “2021-09-01T10:02:55Z”,
“last_heartbeat_ts”: “2021-09-03T06:17:32.080571655Z”,
“uptime”: “44h14m37.080571655s”
}
},
{
“store”: {
“id”: 151301,
“address”: “172.21.30.237:20160”,
“version”: “5.2.0”,
“status_address”: “172.21.30.237:20180”,
“git_hash”: “556783c314a9bfca36c818256182eeef364120d7”,
“start_timestamp”: 1630479587,
“deploy_path”: “/data1/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1630649848812707098,
“state_name”: “Up”
},
“status”: {
“capacity”: “3.401TiB”,
“available”: “1.109TiB”,
“used_size”: “1.898TiB”,
“leader_count”: 43497,
“leader_weight”: 1,
“leader_score”: 43497,
“leader_size”: 3622096,
“region_count”: 129571,
“region_weight”: 1,
“region_score”: 402675171.5219846,
“region_size”: 10767655,
“slow_score”: 1,
“start_ts”: “2021-09-01T06:59:47Z”,
“last_heartbeat_ts”: “2021-09-03T06:17:28.812707098Z”,
“uptime”: “47h17m41.812707098s”
}
},
{
“store”: {
“id”: 918785,
“address”: “172.21.11.22:20160”,
“version”: “5.2.0”,
“status_address”: “172.21.11.22:20180”,
“git_hash”: “556783c314a9bfca36c818256182eeef364120d7”,
“start_timestamp”: 1630481421,
“deploy_path”: “/data1/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1630649857317595538,
“state_name”: “Up”
},
“status”: {
“capacity”: “3.401TiB”,
“available”: “1.095TiB”,
“used_size”: “1.945TiB”,
“leader_count”: 43500,
“leader_weight”: 1,
“leader_score”: 43500,
“leader_size”: 3827843,
“region_count”: 126935,
“region_weight”: 1,
“region_score”: 424140721.9742522,
“region_size”: 11198308,
“slow_score”: 1,
“start_ts”: “2021-09-01T07:30:21Z”,
“last_heartbeat_ts”: “2021-09-03T06:17:37.317595538Z”,
“uptime”: “46h47m16.317595538s”
}
}
]
}