
简介:
来自社区,回归社区。因为有了各位 TiDBer 们在 【TiDBer 唠嗑茶话会 65 】赢取 Ti 红露营五件套,分享常见 TiDB 错误 & 解决不费脑! 里面贡献的各种常见问题 & 解决方案,才有了今天的帖子汇总,帮助更多 TiDBer 们回顾问题 & 解决问题。
常见错误: tikv 内存疯长,不见消退
贡献者: @xfworld
【解决方案】:
- 查看 tikv 的版本是否是官方编译版本,否则请查阅 linux 的内存分配方案(方案选择错误,导致内存无法及时回收)
- 磁盘IO 不足,写入较慢,导致写入内存快于刷盘,开启流控,保证内存和刷盘能够稳定…
- slow Query 下推长期占用资源,无法及时的释放;开启资源定位,能够找到这些 slow query,进行优化,减少资源长期占用的情况
常见错误:执行SQL时,尤其是执行时间较久的SQL,有时会报 Information schema is changed 错误
贡献者: @Jellybean
- 原理:TiDB 在执行 SQL 语句时,会使用当时的 schema 来处理该 SQL 语句,而且 TiDB 支持在线异步变更 DDL。那么,在执行 DML 的时候可能有 DDL 语句也在执行,而你需要确保每个 SQL 语句在同一个 schema 上执行。所以当执行 DML 时,遇到正在执行中的 DDL 操作就可能会报 Information schema is changed 的错误
- 原因 1:正在执行的 DML 所涉及的表和集群中正在执行的 DDL 的表有相同的
- 原因 2:这个 DML 执行时间很久,期间集群执行了很多 DDL 语句或 TiDB 由于网络问题 长时间不能加载到
schema information,导致中间schema版本变更次数超过tidb_max_delta_schema_count的值
【解决方案】- SQL 在失败后重试,大部分情况都可以恢复
- 检查 集群之间的网络情况,排除网络问题
常见错误:查询使用了hint,但是还是不走tiflash,查询很慢。而主动设置SESSION为tiflash后查询,查询速度很快
贡献者:@TiDBer_pFFcXLgY
【解决方案】:
子查询也加上 hint;
表的统计信息不准,可以手动 analyze table 收集统计信息,可能不加 hint 也能默认走到 tiflash
常见错误 : 通过 TiDB operator 在创建各组件的 Pod 时常处于 Pending 状态,通常会卡在某个组件服务的创建上。
贡献者 @lqbyz
【解决方案】
通常都是资源不满足导致的,具体的可以通过kubectl describe po -n ${namespace} ${pod_name}进行查看具体的,大部分的原因都是由于PV卷没有正常绑定造成的,通过修改或删除进行相关的解决。
常见错误 : TiDB 各服务组件常出现 CrashLoopBackOff
贡献者 @lqbyz
【原因】
在想pv里写数据库的时候由于该pv有数据或没有权限造成的。
【解决方法】
1.通过kubectl describe pod/$pod -n$ns。发现初始化失败重启后失败又重启。
2.通过查看该pod的日志,发现相关的报错,大致就是初始化数据的时候有相关的文件造成初始化数据文件失败。新的pod在往里写数据的时候写不进去。
3.通过解绑pv和pvc,删除pv里的数据,然后重新绑定解决。或者直接删除绑定pv里的数据,kubelet过两分钟还会重启该容器,最近该pod的状态为running。
常见错误 : 访问 PD 报错:TiKV cluster is not bootstrapped
贡献者 @天蓝色的小九
【解决方案】:
PD 的大部分 API 需要在初始化 TiKV 集群以后才能使用,如果在部署新集群的时候只启动了 PD,还没有启动 TiKV,这时候访问 PD 就会报这个错误。遇到这个错误应该先把要部署的 TiKV 启动起来,TiKV 会自动完成初始化工作,然后就可以正常访问 PD
常见错误 : 缩容的常见错误,3节点的tikv集群,宕机一台后起不来缩容一直处于offline状态,无法正常下线。
贡献者 @啦啦啦啦啦
【原因】
要保证三副本,只剩下2个tikv节点会导致region 副本无法进行调度,因此无法正常下线
【解决方法】
要先扩容一个节点,让集群满足至少3节点的条件,region副本可以正常调度再进行缩容tikv
常见错误 : TiKV metric 过多导致 prometheus 存储量巨大和 prometheus 多次重启
贡献者 @DBRE
【原因】
tikv metric过多
【解决方法】
prometheus配置文件在job:tikv处增加如下行
metric_relabel_configs:
- source_labels: [name]
separator: ;
regex: tikv_thread_nonvoluntary_context_switches|tikv_thread_voluntary_context_switches|tikv_threads_io_bytes_total
action: drop- source_labels: [name,name]
separator: ;
regex: tikv_thread_cpu_seconds_total;(tokio|rocksdb).+
action: drop
常见错误 : drainer组件同步延迟: 该问题是业务量过大,drainer进程处理不过来导致
贡献者 @Soysauce520
【解决方法】
拆分drainer,扩容drainer利用参数syncer.replicate-do-db分别同步不同的database
config:
syncer.replicate-do-db
- database1, dataase2, database3
常见错误 : 执行SQL语句时出现报错:1105 - Out Of Memory Quota
贡献者 @ddhe9527
【解决方案】
可以在session级别设置tidb_mem_quota_query到足够大,例如:
set tidb_mem_quota_query=8589934592;
常见错误 : 使用 TiDB Lightning 导入数据,可能会出现以下几种情况导致导入失败:
贡献者 @tomxu
【解决方法】
1.数据源错误:TiDB Lightning 要求 MySQL 数据库 dump 文件的格式必须符合规范,否则可能会导致导入失败。可以通过使用 mydumper 工具生成规范的 dump 文件,或者使用其他工具进行数据预处理以满足要求。
2.配置错误:TiDB Lightning 的配置文件中需要指定正确的参数,如 MySQL 数据库地址、端口、用户名、密码等。如果配置有误,导入也会失败。
3.磁盘空间不足:在导入过程中,TiDB Lightning 会将导入的数据暂时存储到磁盘中,并在导入完成后删除。如果磁盘空间不足,导入也会失败。
4.TiDB 集群故障:在导入过程中,如果 TiDB 集群出现故障,如 PD 节点宕机、TiKV 节点宕机等,也会导致导入失败。
5.数据冲突:在导入过程中,如果原数据库中存在与待导入数据冲突的数据,如主键冲突,也会导致导入失败。
6.权限问题:TiDB Lightning 对下游数据库的账号权限也是要求的。如果没有给予足够权限,导入过程中也会出现权限不足的错误。
总之,TiDB Lightning 导入数据失败的原因有可能很多,需要根据具体情况进行排查。可以通过查看 TiDB Lightning 的报错信息,并结合实际情况分析,逐步解决问题。
常见错误 : TiDB 使用过程中最常见的几类问题及其解决方法:
贡献者 @tomxu
【解决方法】
1.TiDB 集群无法正常启动:
可能的情况包括 TiDB 组件配置错误、物理机器硬件故障、TiDB 版本不兼容等。解决方法需要根据具体错误日志来定位问题并进行逐一排查。
2.TiDB 集群性能较差:
可能的原因包括 TiDB 性能调优不足、写入热点导致的数据分布不均衡等。解决方法可以通过 TiUP Bench 工具对集群进行基准测试,然后进行相关优化。
3.TiDB 导入/导出数据失败:
主要问题包括磁盘空间不足、数据量太大导致内存不足、数据库连接不稳定等。解决方法可以添加更多磁盘或者从 TiDB 集群中增加节点来提高资源容量,或者尝试将数据切分成多个小批次进行导出。
4.TiDB 集群出现数据损坏:
可能的原因包括磁盘故障、节点崩溃、操作系统异常等。解决方法可以通过备份和恢复集群来解决问题。
5.TiDB SQL 优化不足:
可能的原因包括 SQL 写法不合理、表设计不合理等。解决方法可以通过使用 TiDB Query Profiling 工具来分析 SQL 查询性能,进行优化。
6.TiDB 安全风险:
可能的问题包括隐私数据泄露、身份验证不安全等。解决方法可以通过加强 TiDB 集群的安全机制,限制某些权限和操作,保护敏感数据安全。
常见错误 : information_schema.tables.data_length 记录的大小和 TiKV 监控面板上的 store size 不一致
贡献者 @裤衩儿飞上天
【原因】
因为两者计算的角度不一样。information_schema.tables.data_length 是通过统计信息(平均每行的大小)得到的估算值。TiKV 监控面板上的 store size 是单个 TiKV 实例的数据文件(RocksDB 的 SST 文件)的大小总和。由于多版本和 TiKV 会压缩数据,所以两者显示的大小不一样。
【解决方法】
根据自己的需要,两种方法同时参考,做大概的估算值。
常见错误 : com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure The last packet successfully received from the server was 9,303 milliseconds ago.The last packet sent successfully to the server was 9,303 milliseconds ago.
贡献者 @weixiaobing
【原因】
应用方的数据库连接有效期时间,大于数据库自己设置的有效期
【解决方案】
一、修改druid配置(如果使用druid的话)
spring.datasource.druid.validationQuery=select 1
spring.datasource.druid.testWhileIdle=true
spring.datasource.druid.testOnBorrow=true
spring.datasource.druid.testOnReturn=true
PS.此方案对性能会有一定影响
二、修改数据库连接配置
在数据库连接上,加“&autoReconnect=true&failOverReadOnly=false”配置
三、修改数据库连接有效时间
在数据库配置上设置,把数据库连接有效时间设置长一点,比如设置12小时或者24小时
常见错误 : TIKV server is busy
贡献者 @BraveChen
通常是由于tikv负载过高或网络负载打满导致的,可由监控确认后增大网络带宽或者扩容tikv节点解决
常见错误 : 业务不多但负载很高,某些时候看会造成某名奇妙的慢sql
贡献者 @db_user
【排查】:
1.查看analyze的配置
2.查看analyze的执行状态
3.查看涉及到的慢查询的表的健康度
【解决方案】:
如果是有频繁不成功的analyze则通过手动analyze执行
如果是频繁analyze导致的负载高,则调整analyze的时间
如果是有大表analyze执行缓慢,则通过脚本定时手动analyze
常见错误 :TiKV 节点日志庞大占用了硬盘百分之 80 的容量,修改了日志保留策略,删除了日志,一段时间后无写入报错硬盘无可用空间,结果 df -Th 查询 空闲很多
贡献者 @ffeenn
【原因】
df -Th 查询还有百分之50的空间可用,d f -i 查询发现inode 使用百分之100.,是因为上此删除日志的时候没有释放掉inode
【解决方案】
停止该节点重启后完全释放。
常见错误 : 某sql查询时出现 other error for mpp stream 报错时
贡献者 @LI-ldc
【解决方法】:
set @@session.tidb_allow_mpp=0;
常见错误 : dashboard报错:error.pd.client_request_failed: Request failed with status code 500 from PD API: “[PD:cluster:ErrNotBootstrapped]TiKV cluster not bootstrapped, please start TiKV first”
贡献者 @LI-ldc
【解决方法】:
切换dashboard地址,模拟重启dashboard
tiup cluster display tidb-app --dashboard #查看现使用的地址
tiup ctl:v5.1.1 pd -u http://192.168.10.51:2379 config set dashboard-address http://192.168.10.52:2379 #切换51到52
tiup ctl:v5.1.1 pd -u http://192.168.10.52:2379 config set dashboard-address http://192.168.10.51:2379 #切回
常见错误 : group by提示 only_full_gruou_by
贡献者 @LI-ldc
【解决方法】:
set global sql_mode=‘STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION’;
常见错误 : 多表连接时,发现 SQL 关联顺序和预期不一致,导致查询较慢
贡献者 @ealam_小羽
【原因】:
TiDB 表关联默认采用 Join Reorder 算法
【解决方案】:
可采用STRAIGHT_JOIN指定关联顺序
文章:专栏 - 一次多表关联顺序的慢查询——TiDB 关联特性 | TiDB 社区
文档:https://docs.pingcap.com/zh/tidb/stable/join-reorder#join-reorder-算法简介
常见错误 : 以前用的4.0的版本,执行 LOAD DATA 不报错,升级5.0+版本后,LOAD DATA 报错
ERROR 8004 (HY000) at line 1: Transaction is too large, size: 100000058
贡献者 @Hacker_hnSEntrA
【原因】:
在 TiDB 的早期版本中,LOAD DATA语句每 20000 行进行一次提交。新版本的 TiDB 默认在一个事务中提交所有行。从 TiDB 4.0 及以前版本升级后,可能出现ERROR 8004 (HY000) at line 1: Transaction is too large, size: 100000058错误。
【解决方法】:
要解决该问题,建议调大tidb.toml文件中的txn-total-size-limit值。如果无法增加此限制,还可以将tidb_dml_batch_size的值设置为20000来恢复升级前的行为。
常见错误 : tiup在线升级tidb部件失败,显示timeout
贡献者 @半瓶醋仙
【解决方法】
1数据库系统手动重启。
2网络拥塞,手动调整宽带,错峰升级。
3修改配置
常见错误 : transport: Got too many pings from the client, closing the connection.
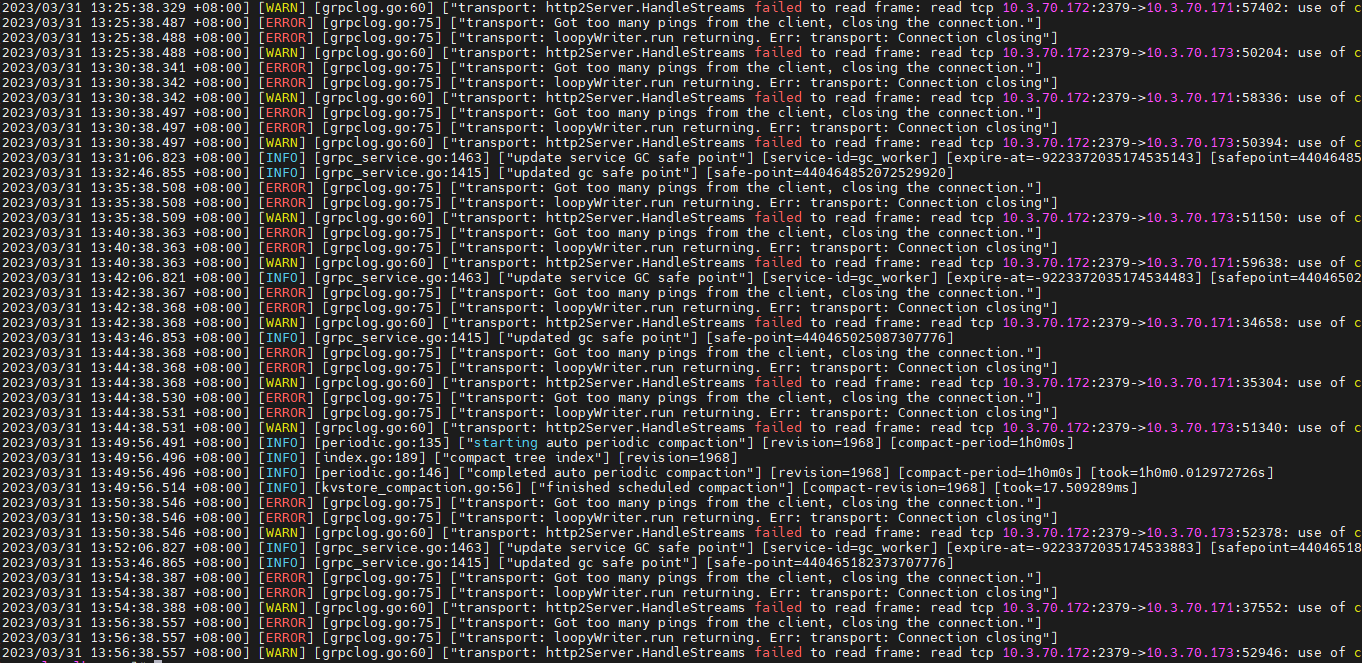
贡献者 @xingzhenxiang
【解决方法】
忽视,就当没看见
常见错误 : 加减节点时候报错
贡献者 @neolithic
【解决方法】
清理tombstone的节点
常见错误 : 利用可视化工具复制其他数据库的数据到tidb,报错事务太大同步失败
贡献者 @tidb菜鸟一只
【解决方法】
调大tidb的txn-total-size-limit参数,因为此参数默认1G,同步表稍大就会报错
常见错误 : k8s 部署 TiDB ,TiKV 经常 oom 导致重启
贡献者 [@tidb菜鸟一只]
【解决方法】
修改tikv的storage.block-cache.capacity参数,因此参数默认设置为内存的45%,但是k8s上默认的是物理机的45%,一台物理机上有太多的pod,很容易内存oom重启,顾可以设置为单pod的45%
常见错误 : 版本v6.1 .20亿大表增加索引,时间过长,无法接受,甚至因为GC 导致增加索引失败。
贡献者 @考试没答案
【解决方法】
升级成v6.5版本,在增加索引性能上快10倍不止。快速增加索引。从低版本需要注意参数控制
常见错误 : 热点问题
贡献者 @Jiawei
【解决方法】
在创建表设计表的初期,要考虑进去热点问题
常见错误 : 锁的问题
贡献者 @Jiawei
【解决方法】
尽量业务设计的时候避免频繁竞争锁,等待锁的相关问题。
常见错误 : oom 问题
贡献者 @Jiawei
【解决方法】
记得设置相关 sql 限制好内存使用,不然 oom 问题很头疼
常见错误 : dm数据同步提示:mydumper/dumpling runs with error, with output (may empty): “RawCause”: “invalid connection”
贡献者 @Hacker007
【原因】
集群压力过大,并非数据库连接问题
【解决方法】
分小批批执行
常见错误 : 查询使用了hint,但是还是不走tiflash,查询很慢。而主动设置SESSION为tiflash后查询,查询速度很快
贡献者 @tidb狂热爱好者
【解决方法】
减少数据量,增加索引,查看热力图,如果不黄了。性能就好了
子查询也加上hint;
表的统计信息不准,可以手动 analyze table 收集统计信息,可能不加 hint 也能默认走到 tiflash
常见错误 : 1105 - other error for mpp stream: From MPPquery:438559064225480712:25,task: Code: 0, e.displayText() = DB::Exception: Packet is too large to send, size : 2730663704, e.what() = DB::Exception,
贡献者 @wzf0072
【解决方法】
set @@tidb_allow_mpp=0;
SET GLOBAL tidb_server_memory_limit = “28GB”;
set global tidb_mem_oom_action=‘LOG’;
SET tidb_mem_quota_query = 24 << 30;
常见错误 : CPU在某一时刻突然飙升
贡献者 @waeng
【解决方案】:
排查这一时刻慢查询,
如果使用了分区表,检查是否使用了分区键
常见错误 : pd集群挂掉,重启无法恢复
贡献者 @wfxxh
【解决方法】
pd一键恢复脚本
#!/bin/bash
#
# desc: 一键恢复pd
# auth: wfxxh
PD_HOSTS=(node1 node2 node3)
ROOT_PASSWORD=*******
#关闭tidb,防止服务重启产生脏数据
source /home/tidb/.bash_profile
tiup cluster stop wf-tidb -y
#备份pd数据目录
for pd_host in ${PD_HOSTS[@]};do
cmd="mv /tidb/deploy/data.pd /tidb/deploy/data.pd_bak_`date +%Y%m%d%H%M%S`\n"
expect << EOF
set timeout -1
spawn ssh root@$pd_host
expect {
"yes/no" { send "yes\n";exp_continue}
"password" { send "$ROOT_PASSWORD\n"}
}
expect "]#" {
send "$cmd"
}
expect "]#" {
send "exit\n"
}
expect eof
EOF
done
#获取pd日志
for pd_host in ${PD_HOSTS[@]};do
scp_path="/tidb/deploy/log/pd.log /home/tidb/pd_$pd_host.log"
expect << EOF
set timeout -1
spawn scp root@$pd_host:$scp_path
expect {
"yes/no" { send "yes\n";exp_continue}
"password" { send "$ROOT_PASSWORD\n"}
}
expect eof
EOF
done
#获取idAllocator,重置pd
origid=`grep 'idAllocator allocates a new id' /home/tidb/pd_*.log | awk -F'=' '{print $2}' | awk -F']' '{print $1}' | sort -r -n | head -1`
let idAllocator=$origid+100
echo "====== origid = $origid ======"
echo "====== idAllocator = $idAllocator ======"
#开启 pd
tiup cluster start wf-tidb -R pd -y
/home/tidb/tidb-v5.4.3-linux-amd64/bin/pd-recover -endpoints http://node1:2379 -cluster-id 你的集群id,写死即可 -alloc-id $idAllocator
mv /home/tidb/pd_*.log /home/tidb/pd_log_bak
#重启tidb
tiup cluster restart wf-tidb -y
#重启ticdc
for cdc_host in ${PD_HOSTS[@]};do
expect << EOF
set timeout -1
spawn scp root@$cdc_host:/tidb/deploy/cdc-8300/log/cdc.log /home/tidb/cdc_$cdc_host.log
expect {
"yes/no" { send "yes\n";exp_continue}
"password" { send "$ROOT_PASSWORD\n"}
}
expect eof
EOF
done
startTS=`grep checkpointTs /home/tidb/cdc_*.log | awk '{print $12}' | awk -F'=' '{print $2}' | awk -F']' '{print $1}' | sort -r -n | head -9 | tail -1`
echo "====== startTS = $startTS ======"
tiup ctl cdc changefeed create --pd=http://node1:2379 --sink-uri="mysql://用户名:密码@ip端口/" --changefeed-id="bak-tidb" --start-ts=$star
tTS --sort-engine="unified" --config /home/tidb/cdc-conf/cdc.conf
mv /home/tidb/cdc_*.log /home/tidb/cdc_log_bak
常见错误 : risk of OOM
贡献者 @TiCQ
【解决方案】:
增加机器计算内存资源;升级TiDB最新稳定版本等
常见错误 : 客户端报错 Tidb ERROR 2013 (HY000): Lost connection to MySQL server during query
贡献者 @边城元元
【解决办法】:
– 设置 tidb-server 实例的最大内存用量
SET GLOBAL tidb_server_memory_limit = “30G”;
– 单条 SQL 语句的内存使用超出此设置,为某些算子启用临时磁盘
SET tidb_mem_quota_query = 24 << 30;
常见错误 : Error Number: 8005 完整的报错信息为 ERROR 8005 (HY000) : Write Conflict, txnStartTS is stale 。
贡献者 @众天-王先生
【解决办法】
事务在 TiDB 中遇到了写入冲突。可以检查tidb_disable_txn_auto_retry是否为 on。如是,将其设置为 off;如已经是 off,将tidb_retry_limit调大到不再发生该错误。
常见错误 : 新扩容 tiflash,因为某个表存在语法错误一直处于down状态启动不了
贡献者 @zhimadi
【解决办法】
把表删了重新建就可以。
常见错误 : Number:9003:TiKV 操作繁忙
贡献者 @gary
【解决办法】
一般出现在数据库负载比较高时,检查 TiKV Server 状态/监控/日志。
常见错误 : Number: 9001:请求 PD 超时
贡献者 @gary
【解决办法】
检查 PD Server 状态/监控/日志以及 TiDB Server 与 PD Server 之间的网络
常见错误 : Flink TiDB CDC Connector 读取 TiDB 操作时间元数据的时取到的增量操作时间错误
贡献者 @TiDBer_小小
【解决办法】
使用时间函数代替CDC 元数据时间戳。
常见错误 : sql执行慢查看sql执行计划不对,收集统计信息后还是没有按照最优的执行计划
贡献者 @forever
【解决办法】
绑定执行计划:
创建一个 global binding,指定其使用 sort merge join
create global binding for
select * from t1, t2 where t1.id = t2.id
using
select /*+ merge_join(t1, t2) */ * from t1, t2 where t1.id = t2.id;
常见错误 : TiDB 负载均衡错误, TiDB 集群中某些节点负载过高 [“no available region for key”] [key=“xxxx”]
贡献者 @wuxiangdong
【解决办法】
检查 TiDB 集群中的 PD 的配置,将集群中的数据均匀分布到各个节点
常见错误 : 自己配置免密导致集群部署出问题
贡献者 @caiyfc
【解决办法】让 tiup 自动创建免密,试用 tiup 直接部署就行了
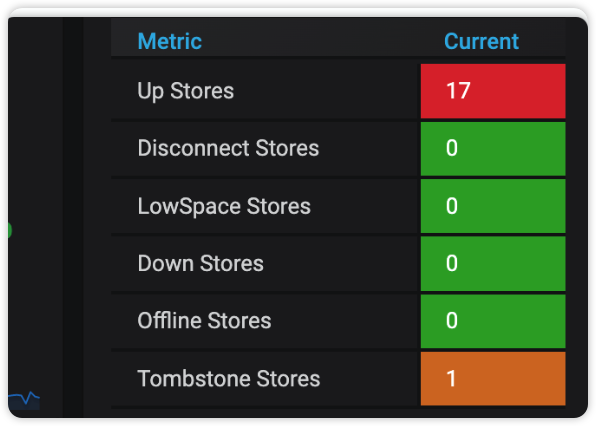
常见错误 : offline-peer-region-count pending 无法正常下线节点
offline-peer-region-count pending
delete store 节点后offline-peer-region-count为 1,无法进入Tombstone Stores
贡献者 @ddmasato
【解决办法】
- 修复有异常的region
- 获得 region id
使用命令region check offline-peer查看具体的region id不要和peer id混了

{
"count": 1,
"regions": [
{
"id": 79807321, // <<<<<< region id
"epoch": {
"conf_ver": 77888,
"version": 138300
},
"peers": [
{
"id": 88613118, // <<<<<< perr id
"store_id": 2225565
},
{
"id": 89481588,
"store_id": 1125255
},
{
"id": 89538163,
"store_id": 80069537
},
{
"id": 90020902,
"store_id": 972009,
"is_learner": true
}
],
"leader": {
"id": 89538163,
"store_id": 80069537
},
"down_peers": [
{
"peer": {
"id": 90020902,
"store_id": 972009,
"is_learner": true
},
"down_seconds": 1494305
}
],
"pending_peers": [
{
"id": 90020902,
"store_id": 972009,
"is_learner": true
}
]....
}
]
}
- 剔除 region peer
使用命令operator add remove-peer 79807321 972009
移除strore 972009上的region 79807321的副本
执行成功后,节点正常下线
官方处理
无法正常下线
扩缩容
TiKV缩容一直处于Pending Offline状态
- 常见命令
- Api 命令
# 强制将某个 sotre 设置为 Tombstone
curl -X POST http://192.168.111.101:2379/pd/api/v1/store/2499686/state?state=Tombstone
# 清理 pd 测的 region 信息
curl -X DELETE http://192.168.111.101:2379/pd/api/v1/admin/cache/region/5652996
# 调整权重
./resources/bin/pd-ctl -u "http://192.168.111.101:2379" -d store weight 122781445 1.2 1.2