summary: TiKV channel满,目前还没解决
【常见错误】
查询使用了hint,但是还是不走tiflash,查询很慢。
而主动设置SESSION为tiflash后查询,查询速度很快
【解决方法】
减少数据量,增加索引,查看热力图,如果不黄了。性能就好了
子查询也加上hint;
表的统计信息不准,可以手动 analyze table 收集统计信息,可能不加 hint 也能默认走到 tiflash
1 个赞
据说 评论一下就会有积分?
【常见错误】
1105 - other error for mpp stream: From MPPquery:438559064225480712:25,task: Code: 0, e.displayText() = DB::Exception: Packet is too large to send, size : 2730663704, e.what() = DB::Exception,
【解决方法】
set @@tidb_allow_mpp=0;
SET GLOBAL tidb_server_memory_limit = “28GB”;
set global tidb_mem_oom_action=‘LOG’;
SET tidb_mem_quota_query = 24 << 30;
1 个赞
CPU在某一时刻突然飙升
解决方案:
排查这一时刻慢查询,
如果使用了分区表,检查是否使用了分区键
【常见错误】
pd集群挂掉,重启无法恢复
【解决方法】
pd一键恢复脚本
#!/bin/bash
#
# desc: 一键恢复pd
# auth: wfxxh
PD_HOSTS=(node1 node2 node3)
ROOT_PASSWORD=*******
#关闭tidb,防止服务重启产生脏数据
source /home/tidb/.bash_profile
tiup cluster stop wf-tidb -y
#备份pd数据目录
for pd_host in ${PD_HOSTS[@]};do
cmd="mv /tidb/deploy/data.pd /tidb/deploy/data.pd_bak_`date +%Y%m%d%H%M%S`\n"
expect << EOF
set timeout -1
spawn ssh root@$pd_host
expect {
"yes/no" { send "yes\n";exp_continue}
"password" { send "$ROOT_PASSWORD\n"}
}
expect "]#" {
send "$cmd"
}
expect "]#" {
send "exit\n"
}
expect eof
EOF
done
#获取pd日志
for pd_host in ${PD_HOSTS[@]};do
scp_path="/tidb/deploy/log/pd.log /home/tidb/pd_$pd_host.log"
expect << EOF
set timeout -1
spawn scp root@$pd_host:$scp_path
expect {
"yes/no" { send "yes\n";exp_continue}
"password" { send "$ROOT_PASSWORD\n"}
}
expect eof
EOF
done
#获取idAllocator,重置pd
origid=`grep 'idAllocator allocates a new id' /home/tidb/pd_*.log | awk -F'=' '{print $2}' | awk -F']' '{print $1}' | sort -r -n | head -1`
let idAllocator=$origid+100
echo "====== origid = $origid ======"
echo "====== idAllocator = $idAllocator ======"
#开启 pd
tiup cluster start wf-tidb -R pd -y
/home/tidb/tidb-v5.4.3-linux-amd64/bin/pd-recover -endpoints http://node1:2379 -cluster-id 你的集群id,写死即可 -alloc-id $idAllocator
mv /home/tidb/pd_*.log /home/tidb/pd_log_bak
#重启tidb
tiup cluster restart wf-tidb -y
#重启ticdc
for cdc_host in ${PD_HOSTS[@]};do
expect << EOF
set timeout -1
spawn scp root@$cdc_host:/tidb/deploy/cdc-8300/log/cdc.log /home/tidb/cdc_$cdc_host.log
expect {
"yes/no" { send "yes\n";exp_continue}
"password" { send "$ROOT_PASSWORD\n"}
}
expect eof
EOF
done
startTS=`grep checkpointTs /home/tidb/cdc_*.log | awk '{print $12}' | awk -F'=' '{print $2}' | awk -F']' '{print $1}' | sort -r -n | head -9 | tail -1`
echo "====== startTS = $startTS ======"
tiup ctl cdc changefeed create --pd=http://node1:2379 --sink-uri="mysql://用户名:密码@ip端口/" --changefeed-id="bak-tidb" --start-ts=$star
tTS --sort-engine="unified" --config /home/tidb/cdc-conf/cdc.conf
mv /home/tidb/cdc_*.log /home/tidb/cdc_log_bak
【常见错误】
risk of OOM
【解决方法】
增加机器计算内存资源;升级TiDB最新稳定版本等
客户端报错 Tidb ERROR 2013 (HY000): Lost connection to MySQL server during query
解决办法:
– 设置 tidb-server 实例的最大内存用量
SET GLOBAL tidb_server_memory_limit = “30G”;
– 单条 SQL 语句的内存使用超出此设置,为某些算子启用临时磁盘
SET tidb_mem_quota_query = 24 << 30;
【常见错误】
- Error Number: 8005完整的报错信息为
ERROR 8005 (HY000) : Write Conflict, txnStartTS is stale。
【解决办法】
事务在 TiDB 中遇到了写入冲突。可以检查tidb_disable_txn_auto_retry是否为 on。如是,将其设置为 off;如已经是 off,将tidb_retry_limit调大到不再发生该错误。
【常见错误】
新扩容tiflash,因为某个表存在语法错误一直处于down状态启动不了
【解决方法】
把表删了重新建就可以。
本期要按照格式参与话题讨论才能有积分嗷~
哈哈,那就当个凑数的吧,增加一下活跃度 ![]()
![]()
1 个赞
[常见错误]
1.Number:9003:TiKV 操作繁忙,一般出现在数据库负载比较高时,检查 TiKV Server 状态/监控/日志。
2.Number: 9001:请求 PD 超时,检查 PD Server 状态/监控/日志以及 TiDB Server 与 PD Server 之间的网络。
【常见错误】
Flink TiDB CDC Connector 读取 TiDB 操作时间元数据的时取到的增量操作时间错误
【解决方法】
使用时间函数代替CDC 元数据时间戳。
【常见错误】
sql执行慢查看sql执行计划不对,收集统计信息后还是没有按照最优的执行计划
【解决方法】
绑定执行计划:
创建一个 global binding,指定其使用 sort merge join
create global binding for
select * from t1, t2 where t1.id = t2.id
using
select /*+ merge_join(t1, t2) */ * from t1, t2 where t1.id = t2.id;
【常见错误】
TiDB 负载均衡错误
TiDB 集群中某些节点负载过高
[“no available region for key”] [key=“xxxx”]
【解决方法】
检查 TiDB 集群中的 PD 的配置,将集群中的数据均匀分布到各个节点
常见错误:自己配置免密导致集群部署出问题
解决方案:让tiup自动创建免密,试用tiup直接部署就行了
可以更换下绑定的pv,或者删除原pv里的数据
【常见错误】offline-peer-region-count pending 无法正常下线节点
offline-peer-region-count pending
delete store 节点后offline-peer-region-count为 1,无法进入Tombstone Stores
【解决方法】修复有异常的region

获得 region id
使用命令 region check offline-peer 查看具体的 region id 不要和 peer id 混了
{
"count": 1,
"regions": [
{
"id": 79807321, // <<<<<< region id
"epoch": {
"conf_ver": 77888,
"version": 138300
},
"peers": [
{
"id": 88613118, // <<<<<< perr id
"store_id": 2225565
},
{
"id": 89481588,
"store_id": 1125255
},
{
"id": 89538163,
"store_id": 80069537
},
{
"id": 90020902,
"store_id": 972009,
"is_learner": true
}
],
"leader": {
"id": 89538163,
"store_id": 80069537
},
"down_peers": [
{
"peer": {
"id": 90020902,
"store_id": 972009,
"is_learner": true
},
"down_seconds": 1494305
}
],
"pending_peers": [
{
"id": 90020902,
"store_id": 972009,
"is_learner": true
}
]....
}
]
}
剔除 region peer
使用命令 operator add remove-peer 79807321 972009
移除
strore 972009上的region 79807321的副本
执行成功后,节点正常下线
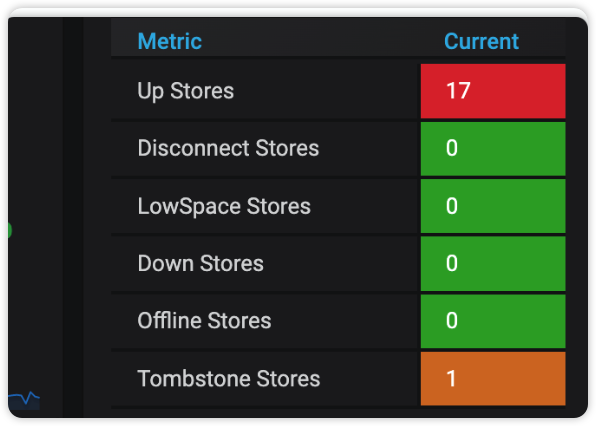
官方处理
无法正常下线
扩缩容
TiKV缩容一直处于Pending Offline状态
常见命令
Api 命令
# 强制将某个 sotre 设置为 Tombstone
curl -X POST http://192.168.111.101:2379/pd/api/v1/store/2499686/state?state=Tombstone
# 清理 pd 测的 region 信息
curl -X DELETE http://192.168.111.101:2379/pd/api/v1/admin/cache/region/5652996
# 调整权重
./resources/bin/pd-ctl -u "http://192.168.111.101:2379" -d store weight 122781445 1.2 1.2
1 个赞