zhenda
(Zhenda)
1
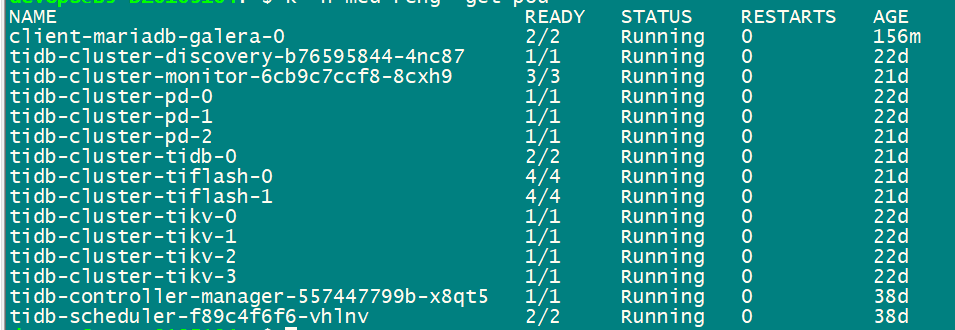
【 TiDB 使用环境】生产环境 硬件独立服务器、nvme存储,通过K8S方式部署的新环境,导入了1T初始数据,tikv+tiflash架构,无业务在用。
【 TiDB 版本】6.1.0
【复现路径】初始数据已导入,未对外提供服务,资源空闲
集群状态正常,能正常访问
【遇到的问题】:tidb client 报错Get Timestamp too slow
tidb server 日志如下:
pd log 日志截图
dashboard截图
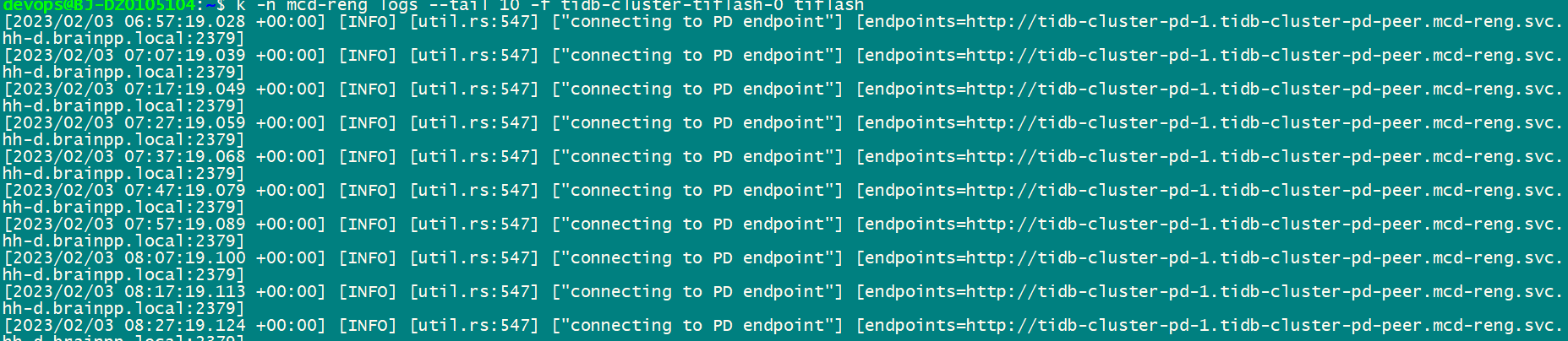
tiflash日志截图
请问:clock offset有何影响?Get Timestamp too slow,通过dashboard具体如何定位问题点 tidb grafana cluster-node为空,无监控信息。
有需要补充的其它信息可发帖稍后补充。
cluster-tidb-2023-02-03-17_34_28.pdf (6.6 MB)
问题应该在pd侧,看看pd的网络、cpu,pd端是否有混布?
zhenda
(Zhenda)
3
无混合部署,独立服务器,新环境,clock offset"] [jet-lag=具体是什么意思
个人理解
tso是pd批量生成的,不是每次生成一个,这个clock offset是指在一个段时间内生成一批tso,这个时间默认是50ms,就是clock offset
zhenda
(Zhenda)
5
jet-lag=208.152004ms 时间是指什么,正常情况下,没有看到频繁刷这个信息。
pd服务器系统资源都空闲,能在具体深入一下么,看下哪里问题
检查检查tidb的cpu,是不是很高了。如果tidb的cpu很高,也会导致tso慢。因为pd返回来后,tidb的goroutine也没被调度起来获取tso的结果。
1 个赞
zhenda
(Zhenda)
10
需要什么信息可以提,一起看下问题,cluster-tidb dashboard已贴出来,关键tso指标已贴
cluster-tidb-2023-02-03-17_34_28.pdf (6.6 MB)
现在表现出来的问题是啥,除了这个日志,导致了啥问题吗
zhenda
(Zhenda)
12
新环境,这些问题可能会导致其它问题,提前解决,tiflash也报了一些pd日志,具体前面已贴图
zhenda
(Zhenda)
16
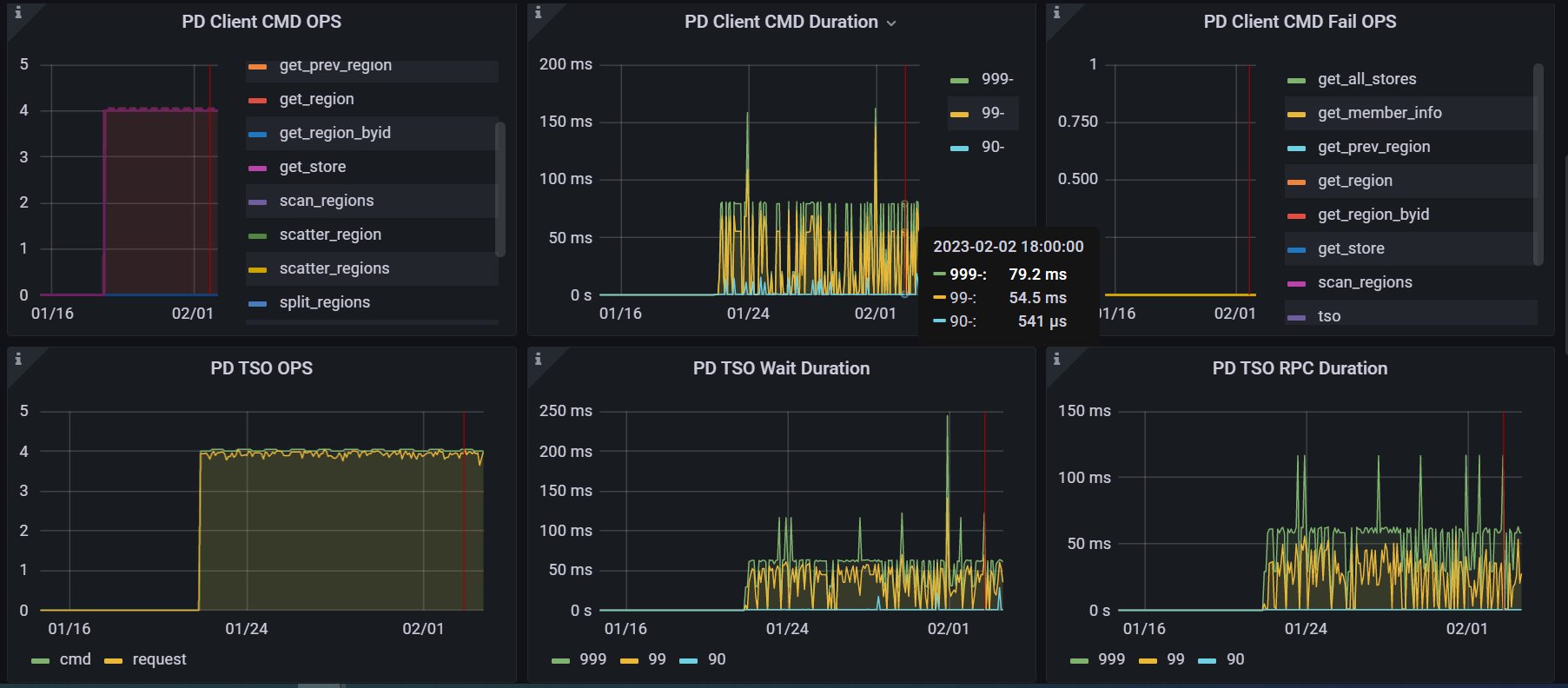
PD Client CMD Duration
发现 PD Client CMD Duration 时间较长,基本等于延迟时间,CMD ops很少,主要还是scan_regions,再怎么深入排查呢?
我是咖啡哥
17
看看tidb server节点到pd节点网络延迟是不是有点大?
看看这两个:
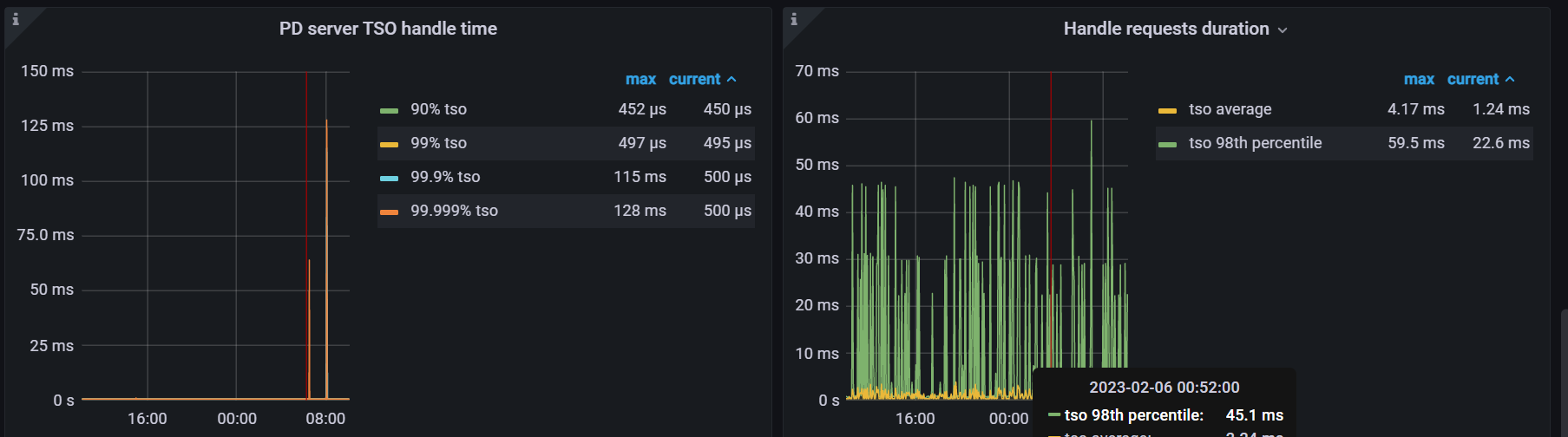
PD----TIDB---- PD server TSO handle time
PD----TIDB---- Handle requests duration
下面这个图,tidb侧的 tso wait duration 和 跟pd和网络间的时间差不多,说明大部分时间消耗在pd和网络侧
zhenda
(Zhenda)
19
CMD druation 较大说明PD侧的PD Client处理时间较长,如下图image|603x404
PC serverTSO handle正常,
通过上面分析是否可以排查网络呢,再如何深入分析呢。
PD client 是在tidb server上,不是在PD server
Pd server tso handle time 是pd server tso处理的时间,你看同一时间段的监控,先把时间对上,如果Pd server tso handle time时间很短,说明问题在网络。
PD tso rpc duration = 网络时间 + pd tsc处理时间




{kind=link}