有没有sql,看看tidb的cpu很麻烦吗?贴出来啊?自始至终不贴tidb的cpu ![]() 。
。
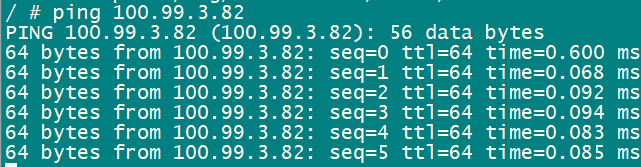
如果tidb的cpu不高,从tidb节点ping pd节点,看看延迟多少。
网络,可以看 blackbox_exporter 里对应节点对应时间段的 ping latency
顶下,继续关注
老哥啊,如果真要刨根问底解决,你得仔细看监控啊。看你也是pctp了。
时间戳慢这个怎么排查,裤衩兄已经给你贴了,你照着监控一步步的看呗。不是网络慢就是cpu高,或者goroutine多,挨个排除。不会莫名其妙的就高的。看监控对着时间点看,比如说日志是10:09:09写的慢,你监控也看这个时间点的。这有什么特别难的吗?如果按这个排查看,不在这个帖子描述的范围内,怀疑是bug,就把对应时间点的各个环节的截图贴这里,你认为你排查过的点没问题就截图证明没问题,然后大家伙有兴趣的话就继续跟踪下比如说是不是代码bug之类的。目前光来回聊天并不解决问题啊。
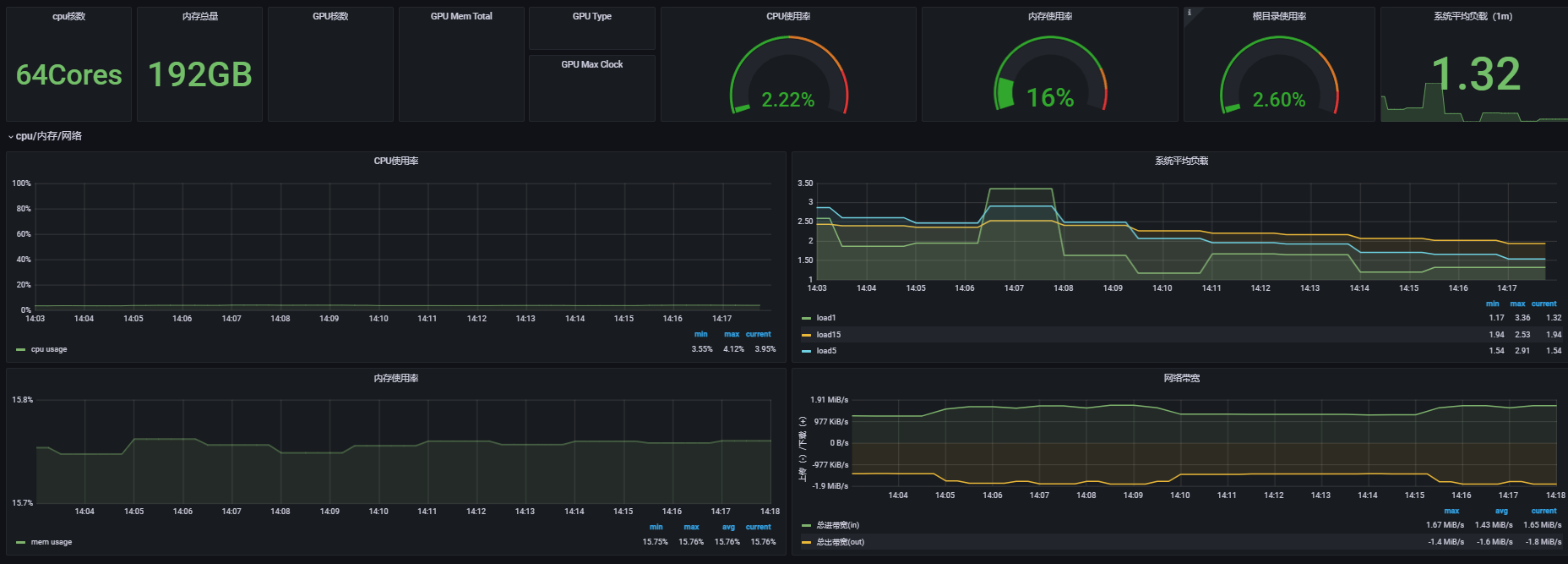
感谢关注大家,真想解决问题。借着问题进行学习。这是新环境,导入了1T数据,无业务在用。cpu io,资源负载非常低,独立服务器nvme 通过k8s部署。整体上看无负载,无负载tso慢就觉得比较奇怪。非某一时间点慢,无业务再跑。
TSO慢排查手册已看过,对应几个指标,排除异步wait,其余比较高的已贴出对应grafana 信息,并根据大家反馈的通用性可能,例如 cpu 负载高,网络ping 延迟以贴图反馈,没发现明显异常。
没有思路若有bug怀疑也算是定位原因,希望群策群力根据反馈信息一起帮进一步深入分析,缩小问题范围,需要什么可以这边可以再提供信息。
tidb比较复杂迭代也很快,需要更多实践和问题处理来技术沉淀,pctp认证算是刚入门吧。还是希望焦距问题,解决问题
1 个赞
PD也是部署在nvme上面吗
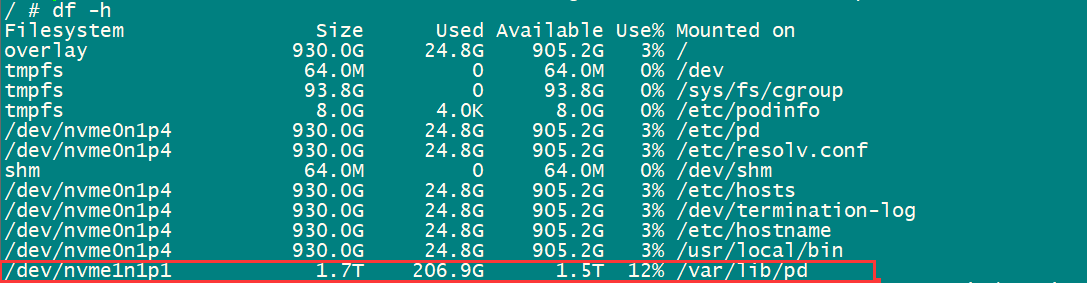
请问这个问题最终定位了么