时过境迁,随着客户量的增加和代码的更新换代,TSO 的一些细节和监控都发生了些许变化,所以在此重新归纳整理,推出 TSO 慢排查手册 v2.0 版本。
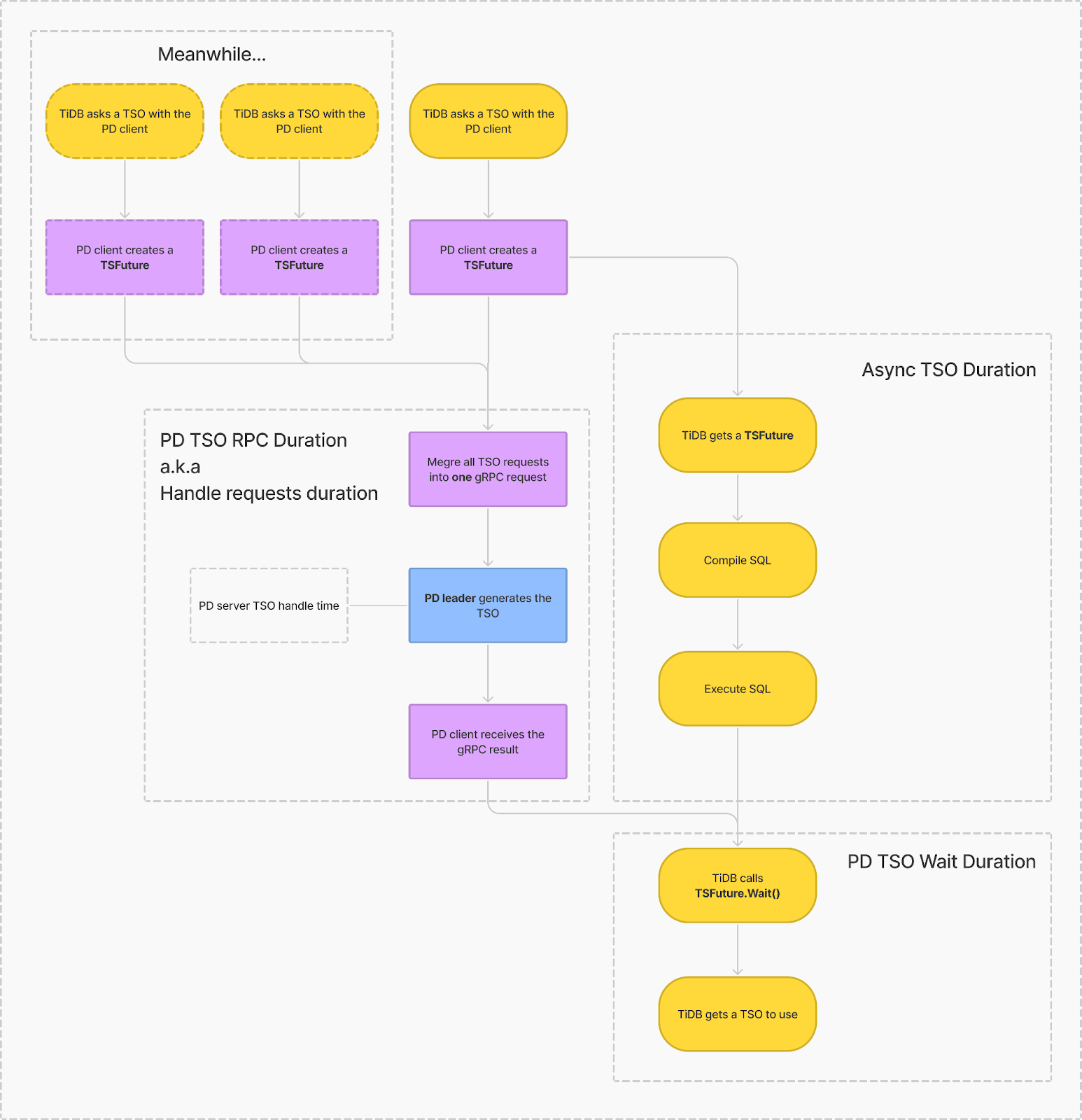
监控项详解
TiDB 侧监控
PD TSO OPS
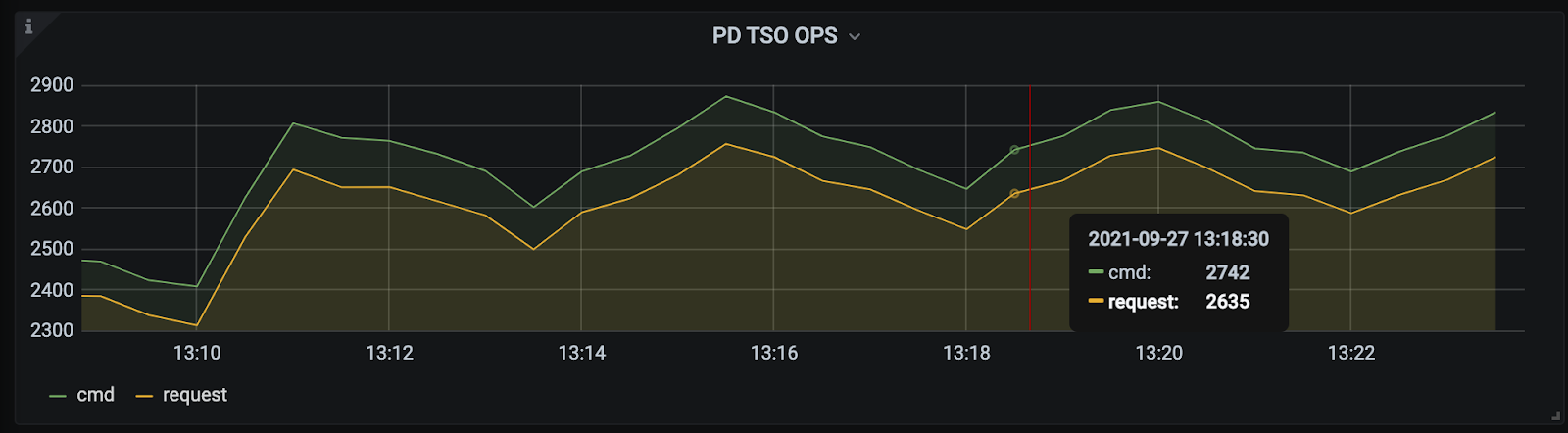
位置:TiDB - PD Client
每秒的 TSO 请求个数和实际发送到 PD 的 gRPC 请求数量。
- cmd 代表 TiDB 侧 Wait TSO 个数的数量
- request 代表 TiDB 侧实际发送给 PD 的 TSO gRPC 请求数量
由于 TiDB 使用的 PD Client 有 batch 攒批策略,所以会一次汇聚多个 TSO 请求,转换成一个实际的 gRPC 请求发送给 PD Leader 期以减轻后者处理压力。反映在监控上应当表现为 request 数量恒小于等于 cmd 数量,cmd/request 即为每秒的平均 batch size。
PD TSO Wait Duration(非 Overview 面板)
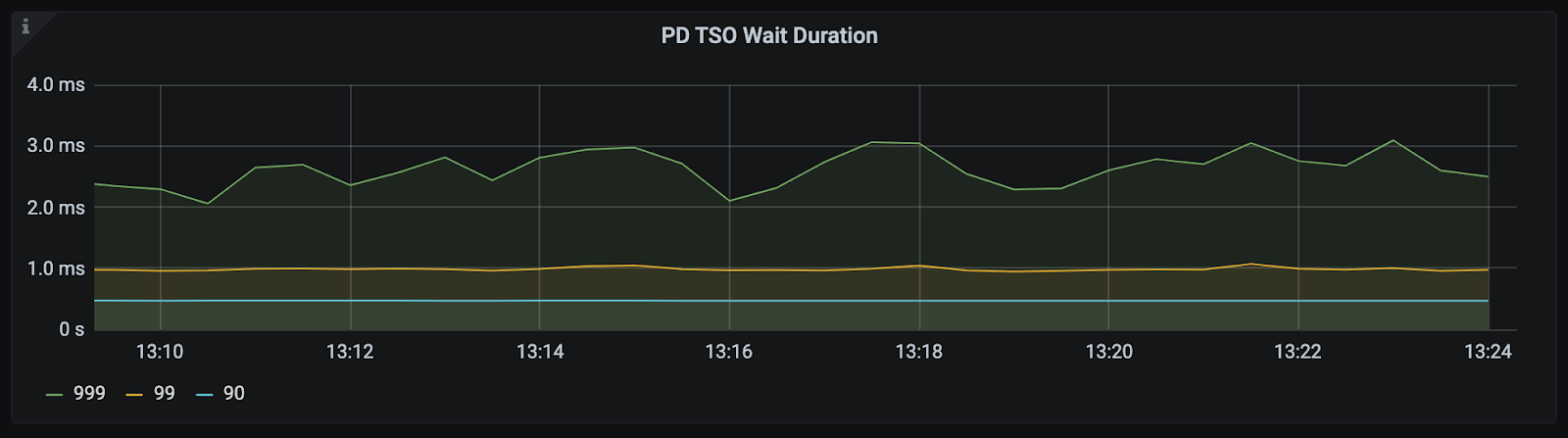
位置:TiDB - PD Client
TiDB 侧拿到一个 TS 后(TSFuture),调用其 Wait 方法获取 TSO 的等待时长,即“调用 tsFuture.Wait() 到获取到 TSO 结果的时长“。
当 TiDB 请求生成 TSO 时,PD Client 不会 block 调用者,而是直接返回一个 TSFuture,并在后台异步处理 TSO 请求的收发,一旦完成立即返回给 TSFuture,TSFuture 的持有者则需要调用 Wait 来获得最终的 TSO 结果。此时分为两个情况:
- 如果 TSO 请求已经完成,Wait 会立刻返回一个可用的 TSO 或 error
- 如果 TSO 请求还未完成,Wait 会 block 住等待一个可用的 TSO 或 error(说明 gRPC 请求在途,网络延迟较高)
而 PD TSO Wait Duration 就代表了从调用 Wait 方法到获得 TSO 的总等待时长(不包括 error 的情况),其可能包括了以下耗时(注意这个“可能”,具体会因调用 Wait 的时机不同而变化):
- TiDB 侧 Go Runtime 调度耗时(大多数情况)
- 部分 gRPC 网络时延
- 部分 PD 侧 TSO 生成处理耗时
- 部分 PD 侧 Go Runtime 调度耗时
对应统计代码:pd/client/client.go at 02848d2660ee105a7bef9e02f485a588132abc4f · tikv/pd · GitHub
PD TSO RPC Duration
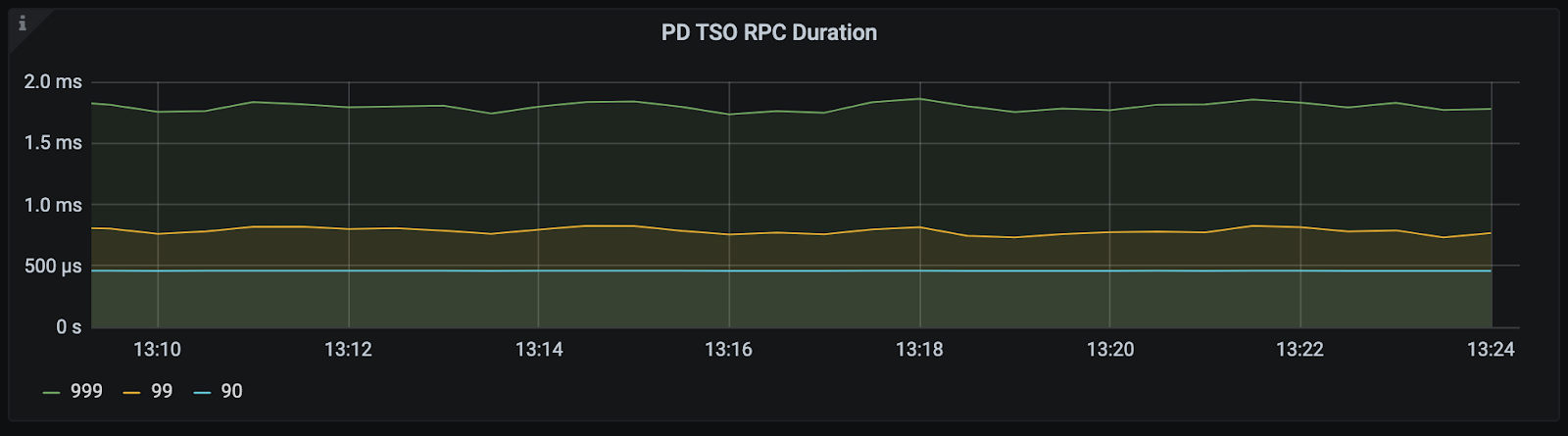
位置:TiDB - PD Client
与 PD 侧的 Handle requests duration 中 tso 项监控相同,只不过在 TiDB 面板上单独拉出来写了一个。代表了 PD Client 将 Tso gRPC 请求发送给 PD Server,并从 PD Server 获得 TSO gRPC 返回的时延。所以它包括了:
- PD 侧 Go Runtime 调度耗时
- PD 侧 TSO 生成处理耗时
- gRPC 的网络延迟
根据 TiDB 的流程逻辑,Wait 的调用时机比较后置,所以大多数情况下 PD TSO Wait Duration 都会小于 PD TSO RPC Duration。你可以理解为 TiDB 在调用 Wait 等待 TSO 请求的时候,TSO 的实际处理流程可能处在以下任意一个阶段:
- RPC 请求还在去往 PD Server 的路上
- RPC 请求还在回到 PD client 的路上
- RPC 请求还处在 PD Server 侧的处理过程(TSO 生成中)
对应统计代码:pd/client/client.go at 02848d2660ee105a7bef9e02f485a588132abc4f · tikv/pd · GitHub
Async TSO Duration(>= v5.4.0)
位置:TiDB - PD Client
TiDB 侧拿到一个 TS 后(TSFuture),到调用其 Wait 方法之间经过的时长,即“从获得 tsFuture 开始到调用 tsFuture.Wait() 的时长“。
如前所言,TiDB 拿到 tsFuture 后不会立马进行 Wait 调用来获取 TSO,而是先去进行 Optimize 等一系列操作,等实际需要 TSO 时才取调用 Wait 来获取 TSO 结果。所以 Async TSO Duration 反应了这段时间 TiDB 处理其他工作的耗时情况,一般当 TiDB 压力增加时,该指标会上升。
PD 侧监控
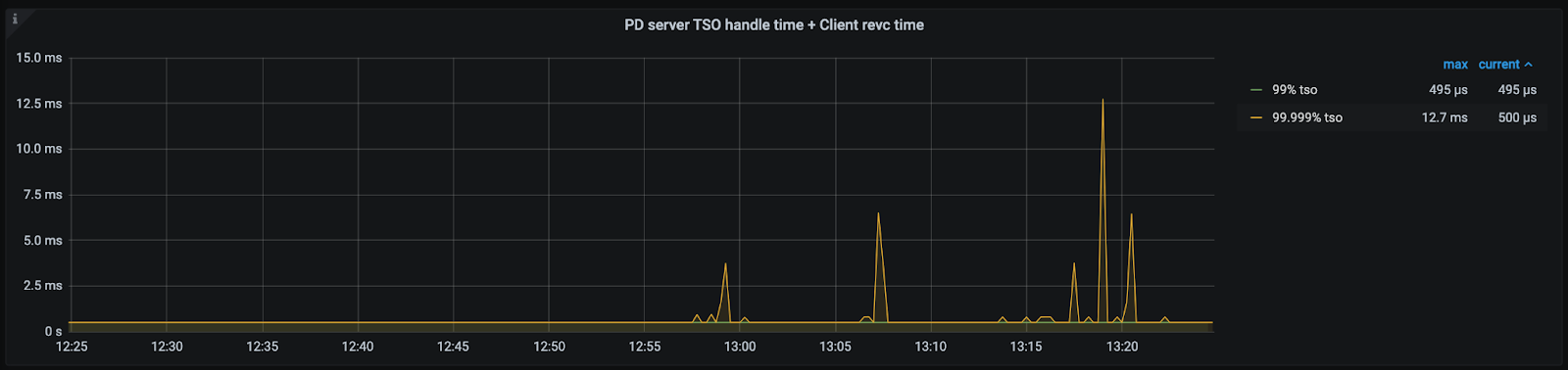
PD server TSO handle time + Client revc time(< v4.0.13)
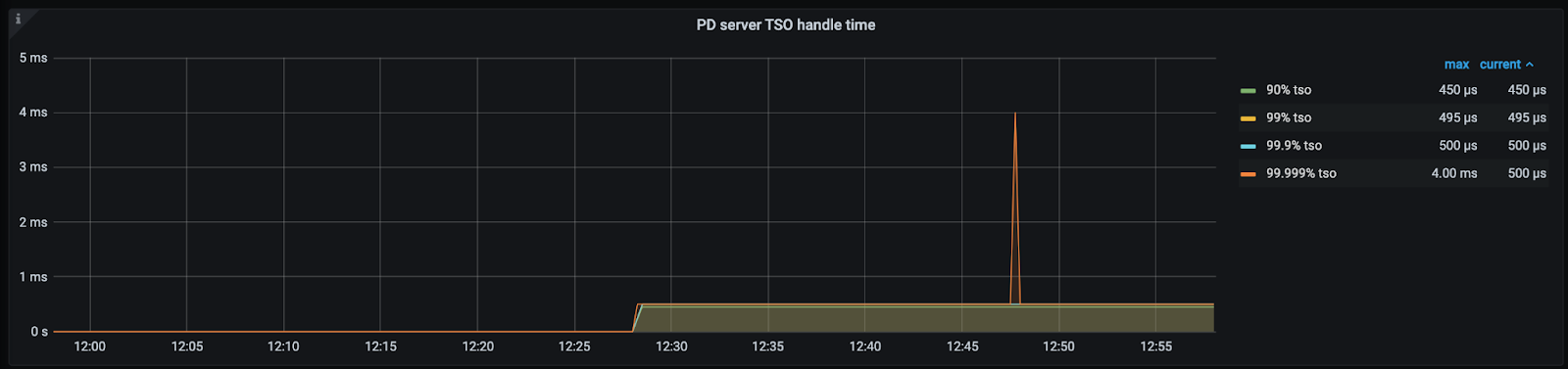
PD server TSO handle time(>= v4.0.13)
位置:PD - TiDB
事实上,这个监控的名字从 v4.0.13 版本起就是错误的,其只包含了 PD Server 端收到请求之后处理 TSO 所花费的时间,并不包括 Client 接收 TSO 的耗时。所以在不同的版本,这个监控的意义有所区分:
- v4.0.13 版本之前(不包括),代表了 PD Server 端的 TSO 处理时延和发送给 Client 的小部分网络时延(因为 gRPC Stream 的发送是非 block 的,所以这里不包括完整的从 server 发送到 client 接受的网络延迟,故而说是“小部分”,具体原理需要阅读 gRPC Stream 相关代码后进一步解释,现在只需要认为在同等条件环境下 v4.0.13 之前的监控会比之后的版本大一点)
- v4.0.13 版本之后(包括),代表了 PD Server 端的 TSO 处理时延
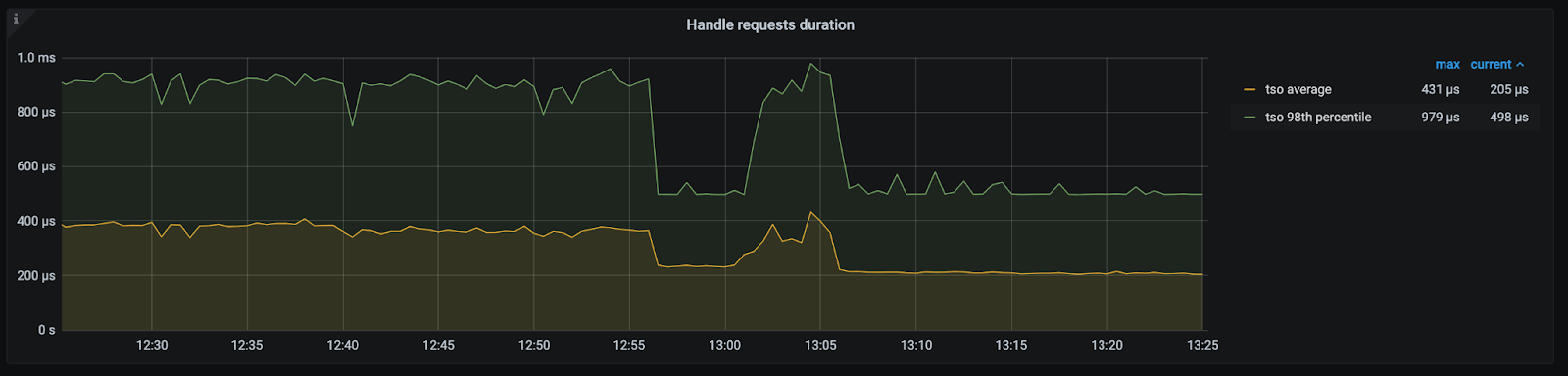
Handle requests duration
位置:PD - TiDB
代表了 PD Client 将 Tso gRPC 请求发送给 PD Server,并从 PD Server 获得 TSO gPRC 返回的时延。所以它包括了:
- PD 侧 Go Runtime 调度耗时
- PD 侧 TSO 生成处理耗时
- gRPC 的网络延迟
对应统计代码:pd/client/client.go at 02848d2660ee105a7bef9e02f485a588132abc4f · tikv/pd · GitHub
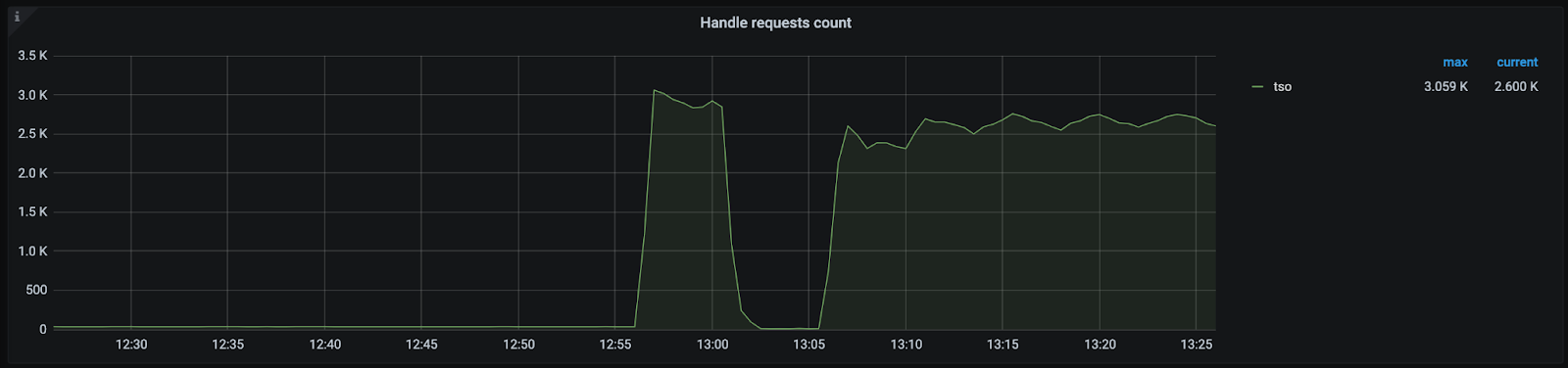
Handle requests count
位置:PD - TiDB
同 PD TSO OPS 中的 request,代表发送给 PD 的实际 Tso gRPC 数量。
TSO 慢的排查手段
一般而言,当我们发现慢的时候,”慢”的这个现象往往会出现在 SQL 的执行耗时增加上,秉持着“先问是不是,再问为什么的原则”,我们首先需要判断 SQL 慢是否真的是因为 TSO 慢了——例如 auto-commit 下的点查 SQL,是不需要获取 TSO 的,它慢不应该在 TSO 监控里找原因。
在排除其他嫌疑,真的下决定要查一查 TSO 慢的问题时,由于对 TiDB 来说,实际感受到“慢”的体感只会来自于 Wait 的调用耗时大,即 PD TSO Wait Duration 的监控表现出整体时延升高或尾延升高。这个时候回顾 PD TSO Wait Duration 的监控意义,我们知道它可能包括:
- TiDB 侧 Go Runtime 调度耗时
- 部分 PD 侧 Go Runtime 调度耗时
- 部分 PD 侧 TSO 生成处理耗时
- 部分 gRPC 网络时延
去除一些偏底层的细节,我们可以将其简单粗暴地归纳为:
- 网络慢了
- PD 卡了
- TiDB 卡了
所以从这三个方向出发,依次排除。
网络慢了
首先立马查看 PD TSO RPC Duration,其正常数值范围 80% 差不多在 1ms 以内,99% 在 4ms 内,如果数值比较高,则说明网络和 PD 的处理时间长(包括 Go Runtime 调度和实际 TSO 处理逻辑),此时继续看 PD server TSO handle time + Client revc time 是否慢,如果不慢则说明 PD TSO 处理(和发送)不慢,大概率是网络问题,需要往网络问题方向排查。
PD 卡了
如果 PD server TSO handle time + Client revc time 慢:
- 如果是 v4.0.13 版本及以后,由于这个监控其实只包括了 PD leader 处理 TSO 时间,所以它慢说明 PD TSO 处理的慢,此时应该考察 PD Leader 的 CPU 占用情况是否较高?以及是否存在混布(混合部署)的情况,即同一台机器上有其他的进程或操作扰乱了 PD 的计算,影响了 TSO 的处理速度。
- 如果是 v4.0.13 版本之前(不包括),那么说明 PD leader 处理 TSO 时间慢或回传给客户端的发送时间慢或两者都比较慢,需要同时考虑上述 PD CPU 问题以及 PD 到 TiDB 之间的网络问题。
还有一个情况也会影响到 PD 的 TSO 分配——PD 出现了 leader 切换,不过一般出现 leader 切换,直接会导致 TSO 不可用,并不能是让 TSO 变慢的原因,只在此一提,仅供参考。
TiDB 卡了
如果顺利排除了网络问题和 PD 问题,那么疑点又回到了 TiDB 这边。由于 TSO 的后台处理流程和 TiDB 的 Parser 以及 Complie 生成 Plan 是同时进行的,遇到高强度的 Workload 和一些较为复杂的查询时,可能会消耗大量的资源,影响到 Wait 操作(里面使用了 select 语句以及 channel,涉及到 Go 的调度),此时可以来到 TiDB 的 Execution 监控面板,看看 Parse,Complie 和 Execute 的耗时。
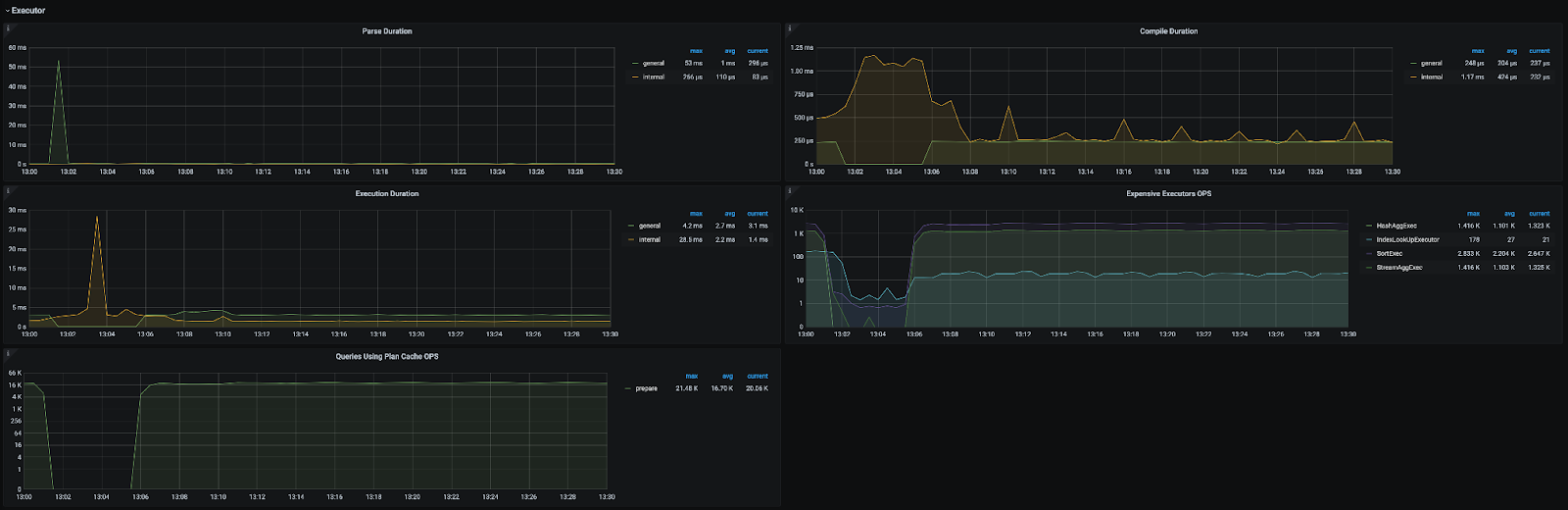
还可以观察一下 TiDB 的 Server 面板,看看 CPU 负载如何。条件允许的情况,可以再 profile 以下,排查一下 goroutine 的数量和运行耗时,看看瓶颈出现在何处。