【 TiDB 使用环境】生产环境
【 TiDB 版本】6.1.0
【遇到的问题:问题现象及影响】
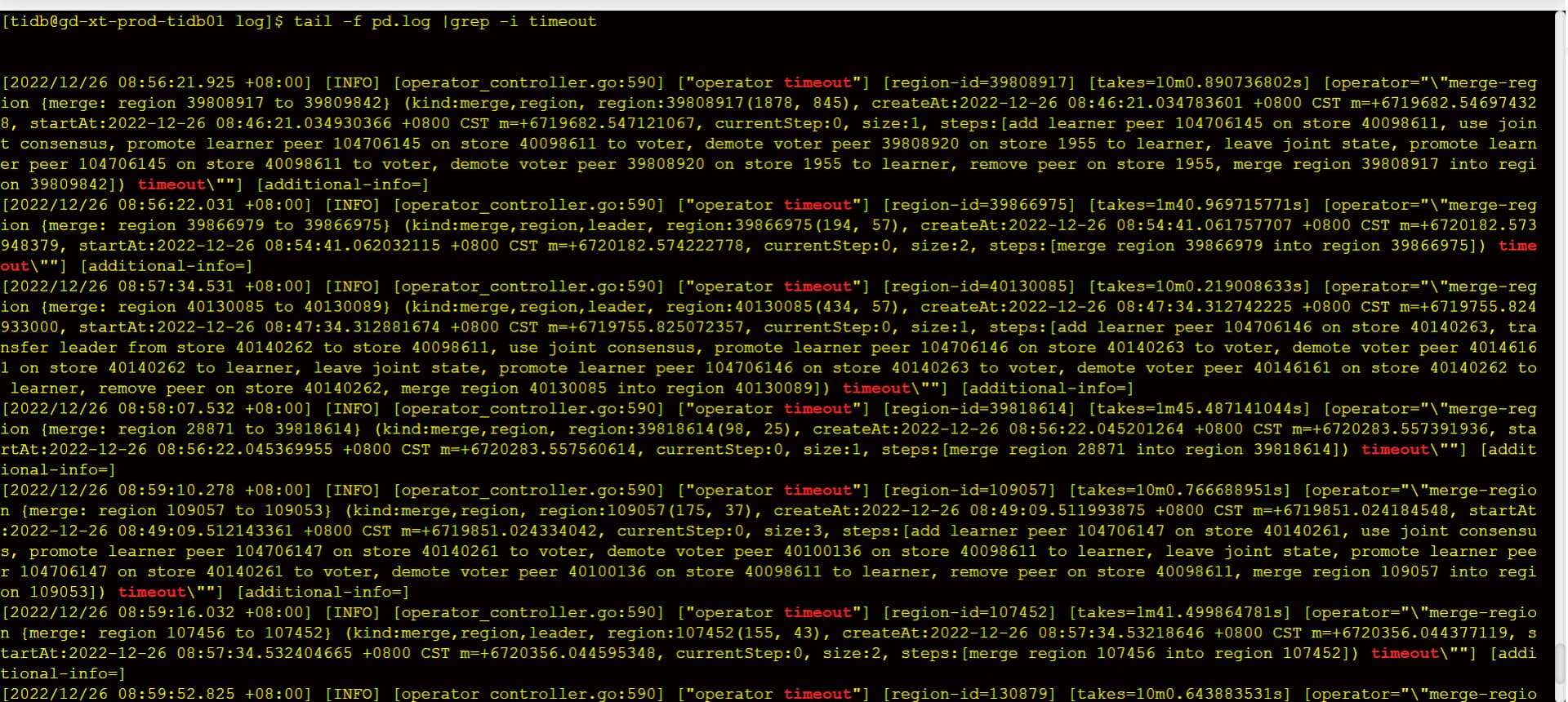
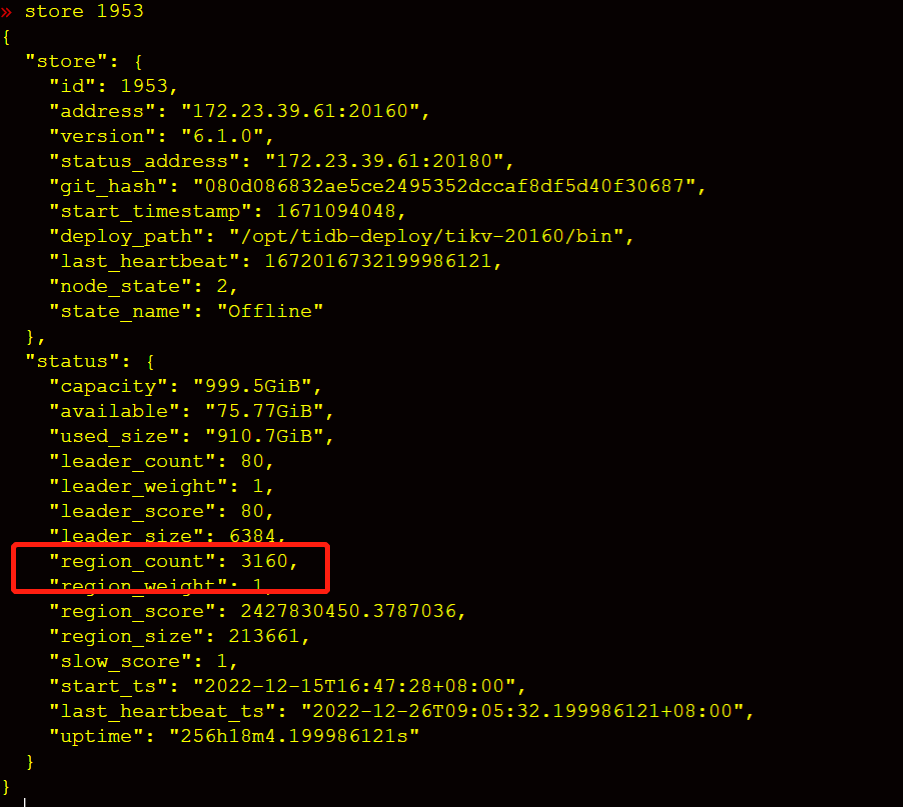
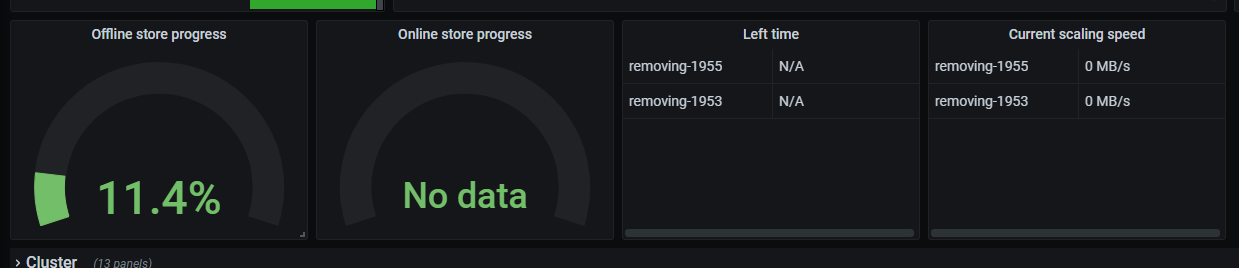
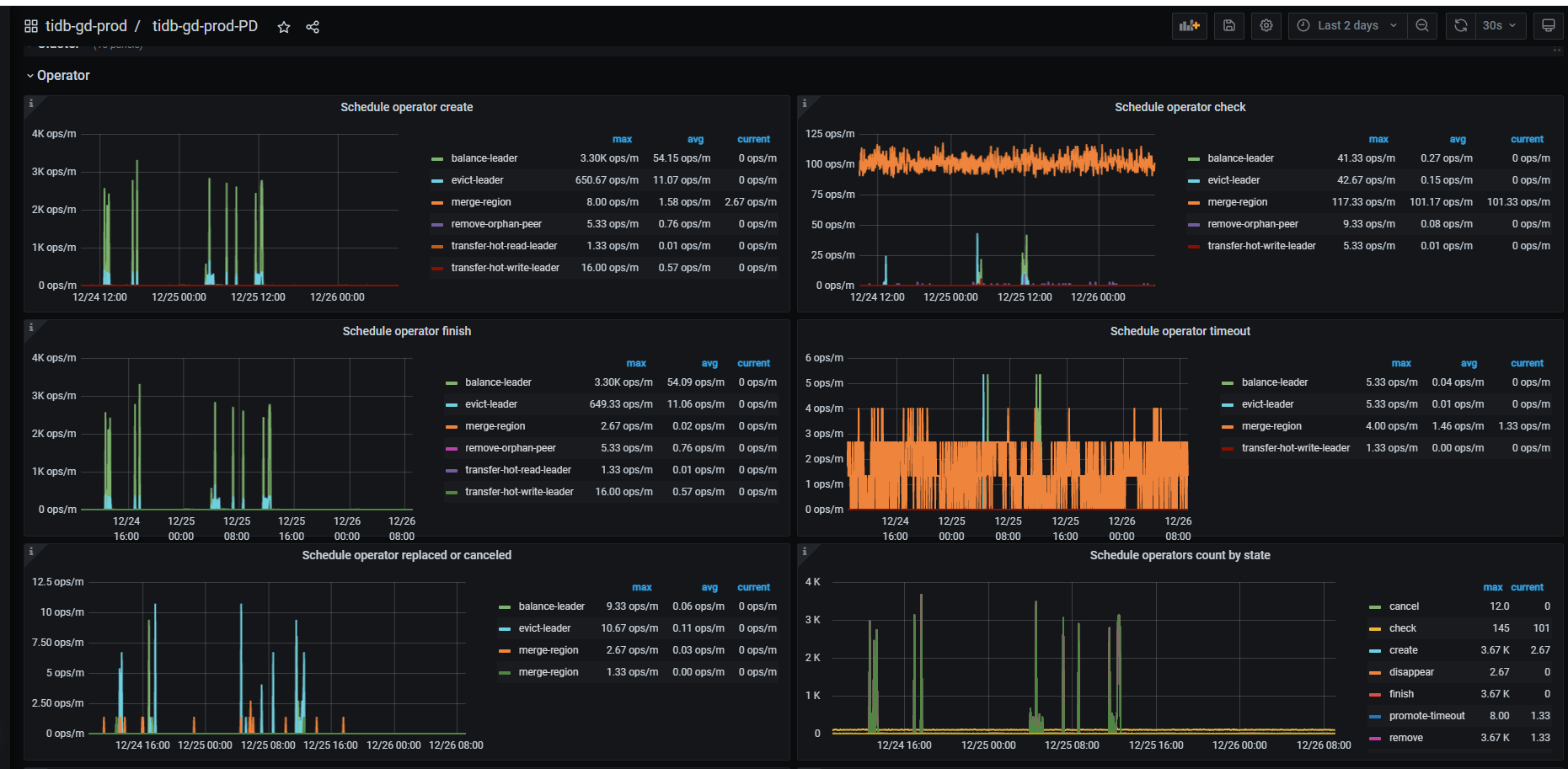
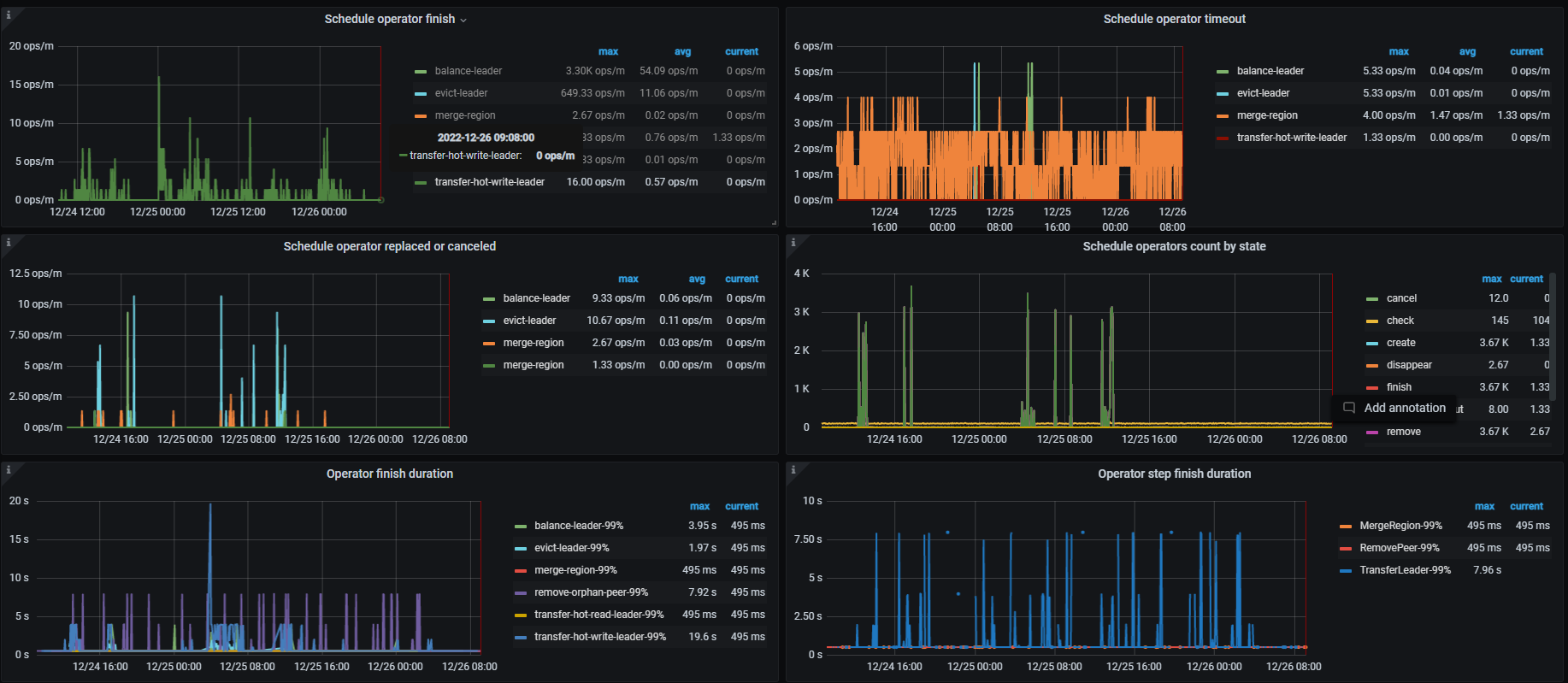
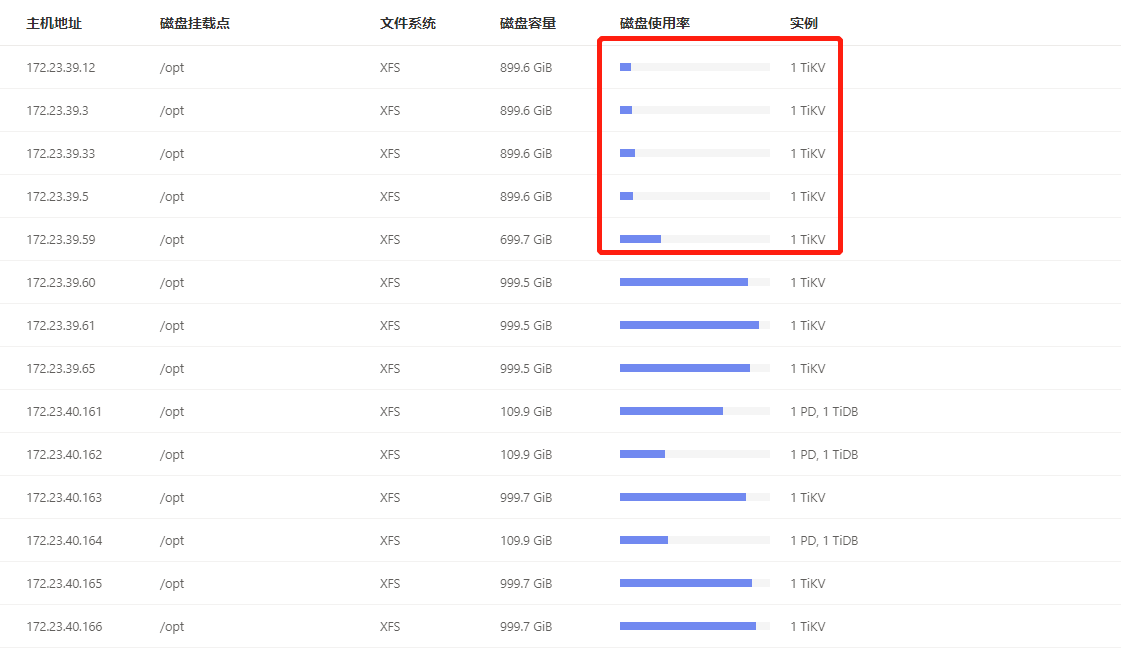
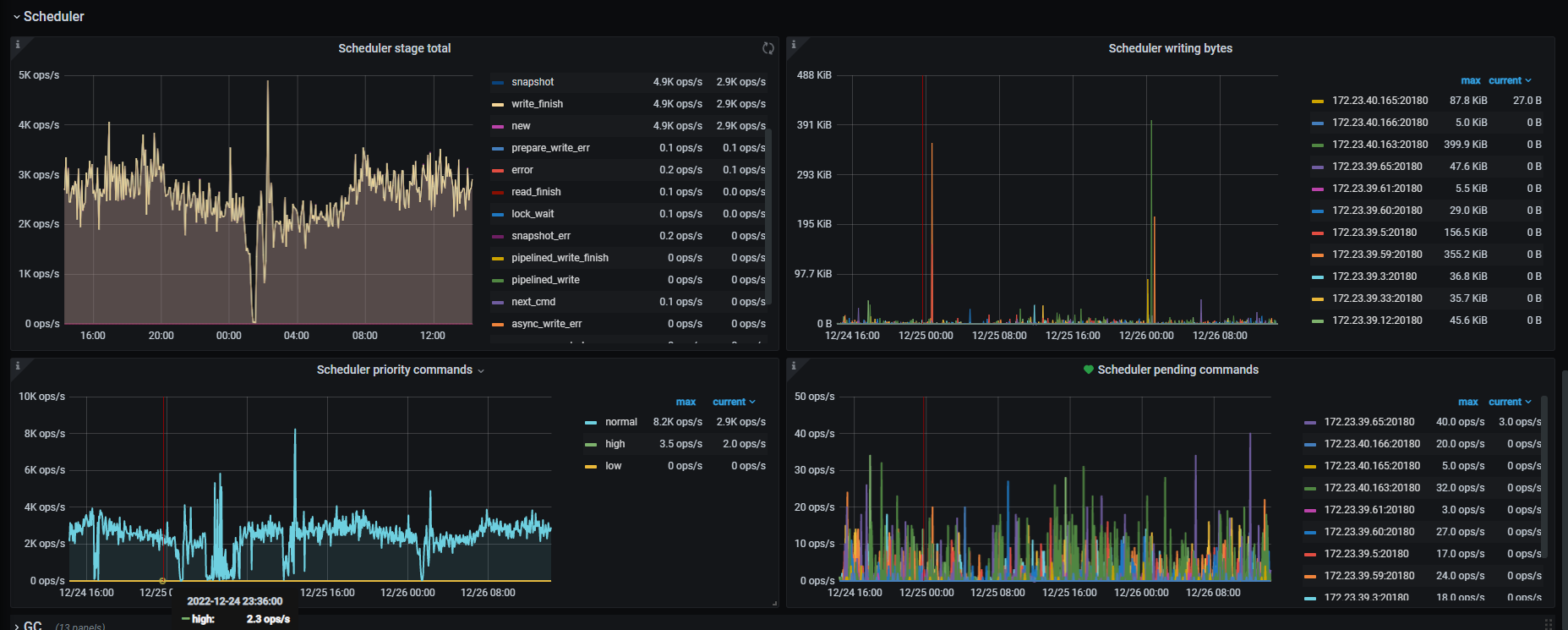
tikv集群磁盘快满了,新扩容了5个节点,然后准备把磁盘空间不足的节点下线清理后再扩容上去,现在发现下线2个tikv节点,耗时接近2个星期了,于是调整了replica-schedule-limit,max-pending-peer-count,set max-snapshot-count参数,但是region下线数据还是没提升,每个节点才减少100多个region,按这个进度感觉要等到下届世界杯了。
【资源配置】
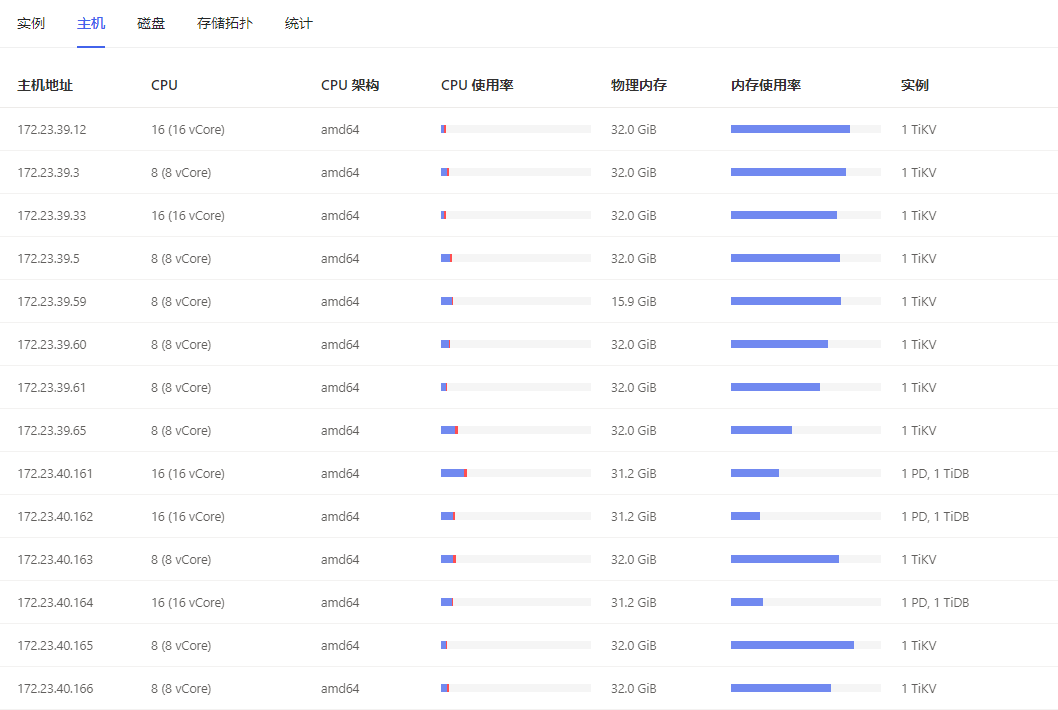
cpu,内存配置:
磁盘情况:

5
PD 超时是一直都有,还是最近出现的?
PD 的 leader 节点,混布 tidb 节点之后,资源上是否能撑得住?
建议手动驱逐你想下线的 tikv 节点,先将 region leader 进行转移…
转移完成之后,下线会简单很多…
PD超时一直都有。
下线前已经把待下线节点的leader驱逐了的。
2个下线store上的remove-peer我看已经很高了。
system
(system)
关闭
18
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。