【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.2
【遇到的问题:问题现象及影响】pd集群全部挂掉,重启无法解决,后通过pd-recover重置pd集群,集群恢复正常。但导致这个问题的原因需要进一步探究。
【资源配置】40核,128G
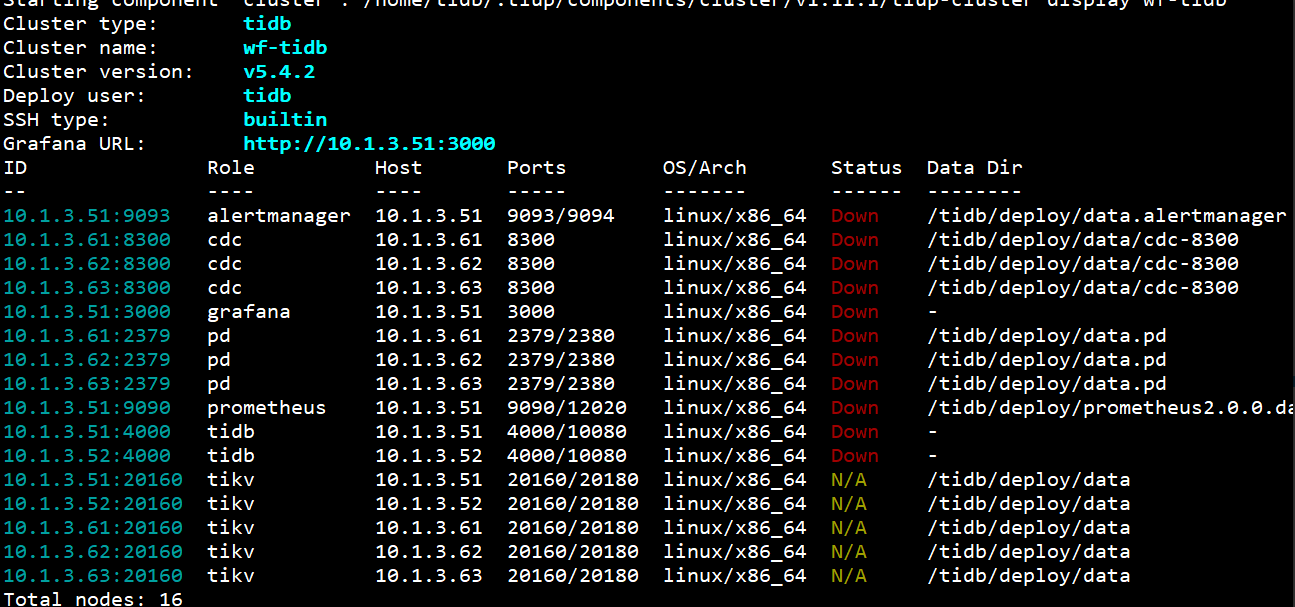



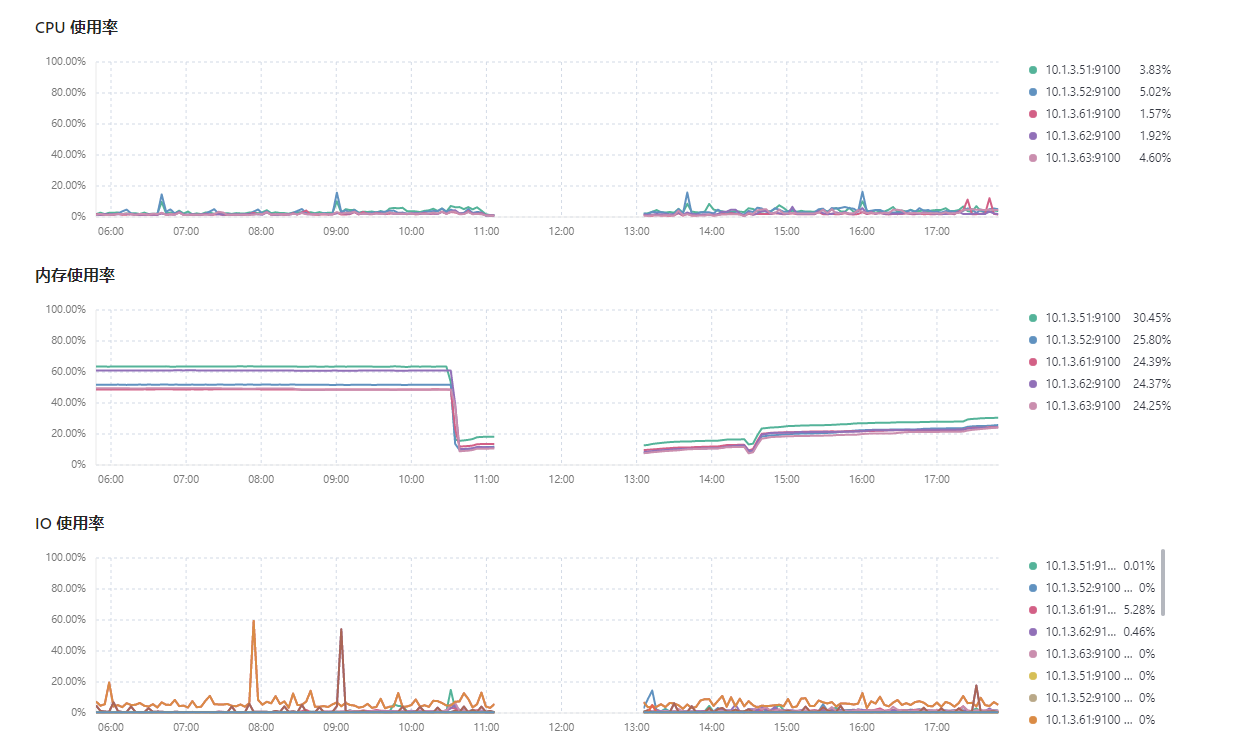
我们没那么大的访问量,资源是足够的。
网络确定是OK的!
退一万步讲,即使网络某一时刻出了故障,网络恢复后集群也能启动吧!但是我连接到服务器,重启服务也失败。这才是需要关注的点,而不是去往资源不足,网络等外部因素上找原因。
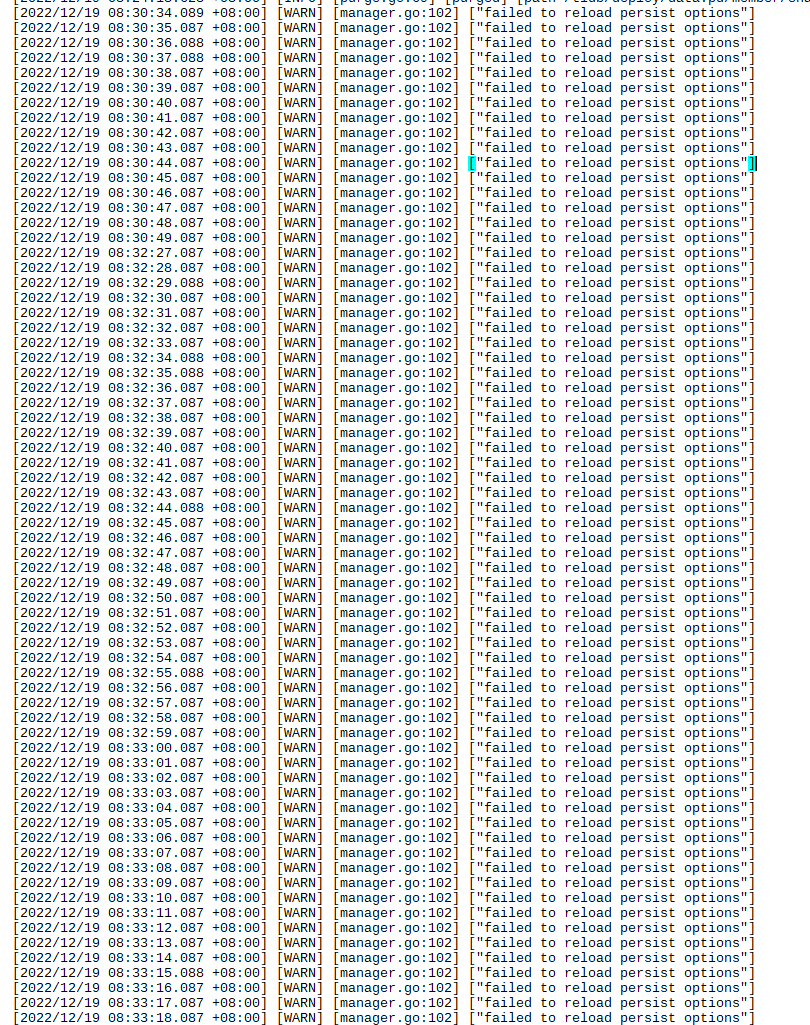
确定磁盘也有空间?
PD 短时间内重启了 N 次,每次都 panic…
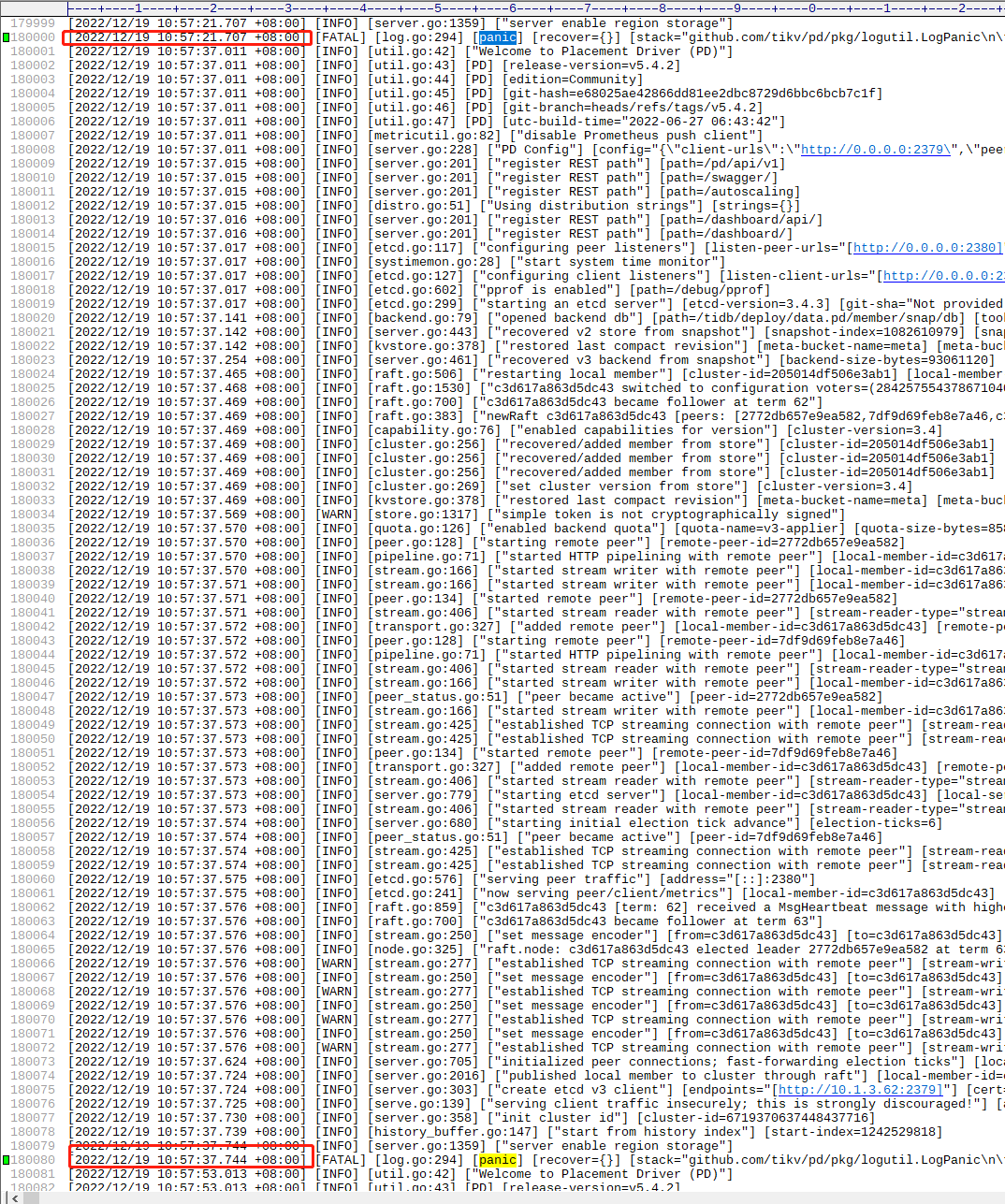
tidb panic 比较常见,PD不常见,【大脑都挂了… ![]()
![]()
![]() 】 最好检查下环境吧(什么叫外部? 资源不足,你让软件怎么运行呢?)
】 最好检查下环境吧(什么叫外部? 资源不足,你让软件怎么运行呢?)
何况环境对于你来说是可见的,我能看到的,只是你提供的一些信息,所有的均是猜想而已
信息不足只能通过经验来判断了… 希望你能明白
兄台,我贴图了,你看看哪里是资源不足。我们硬盘目前只用了21%空间肯定是够的。
具体情况是:
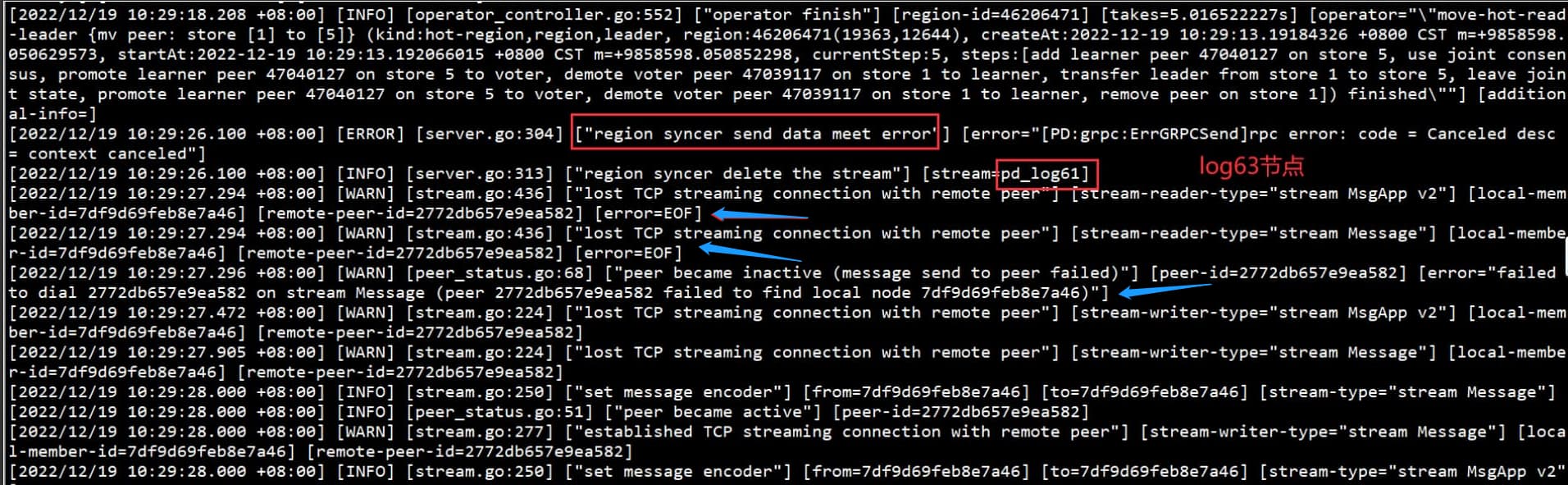
先是突然出现了这个问题,接着一段时间之后pd挂了。
我想不能无缘无故的pd dashboard就获取不到集群配置了吧?
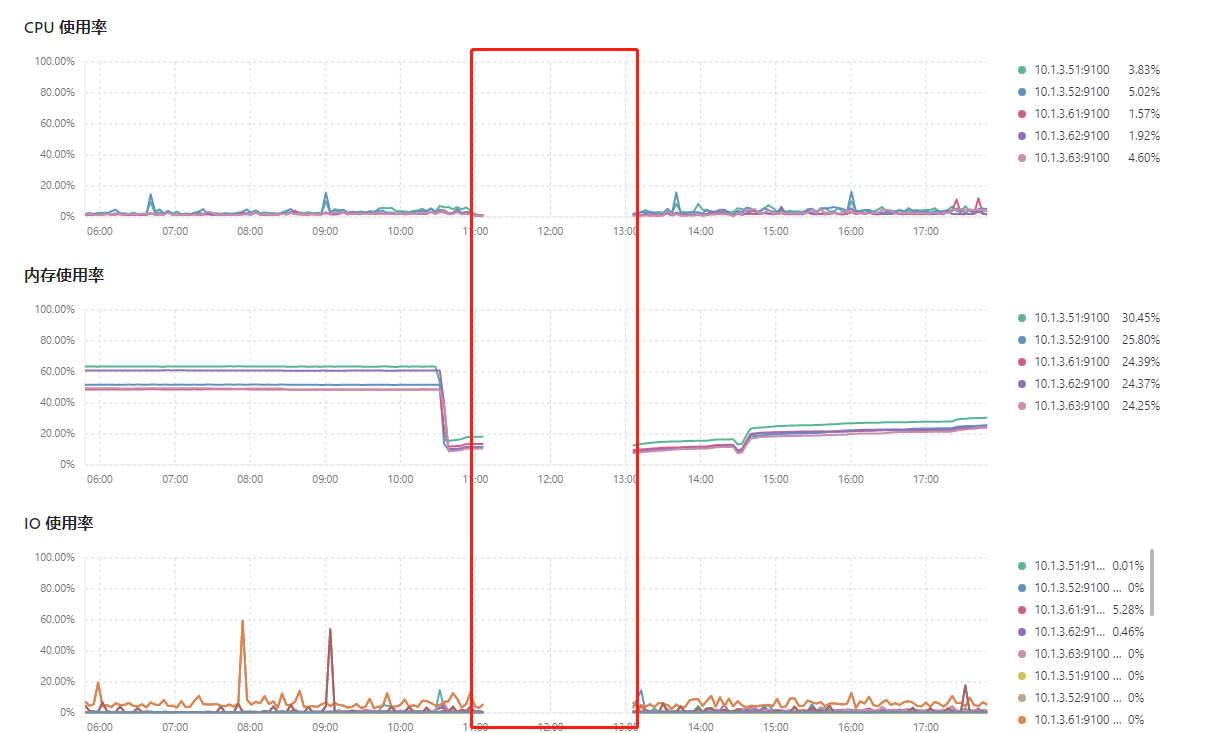
嗯,中断这里是pd挂掉进而导致整个集群挂掉。
猜测是资源竞争导致的,监控只能拿到持续的记录,短期的峰值是获取不到的
建议你将CDC 缩容掉,继续跑跑看
我觉得不能是资源。我们真没那么大的访问量,数据也不多,只1.6T。去掉cdc是不可能的,这辈子不可能 ![]()
之前的确因为cdc导致pd挂掉过:pd三个节点同时挂掉,大量报错:invalid timestamp
但是也不是因为资源,是因为cdc请求pd太频繁。
怎么说我们服务器,装这点数据肯定还是能承载的。
这个我明白
- PD 目前状态是否正常?
- PD 的 leader 是否能自由切换?
- 如果以上都ok,我建议你切换 dashboard 的服务节点,观察下是否还存在问题
你是说获取不到prometheus哪个吗?我无法复现这个现象了