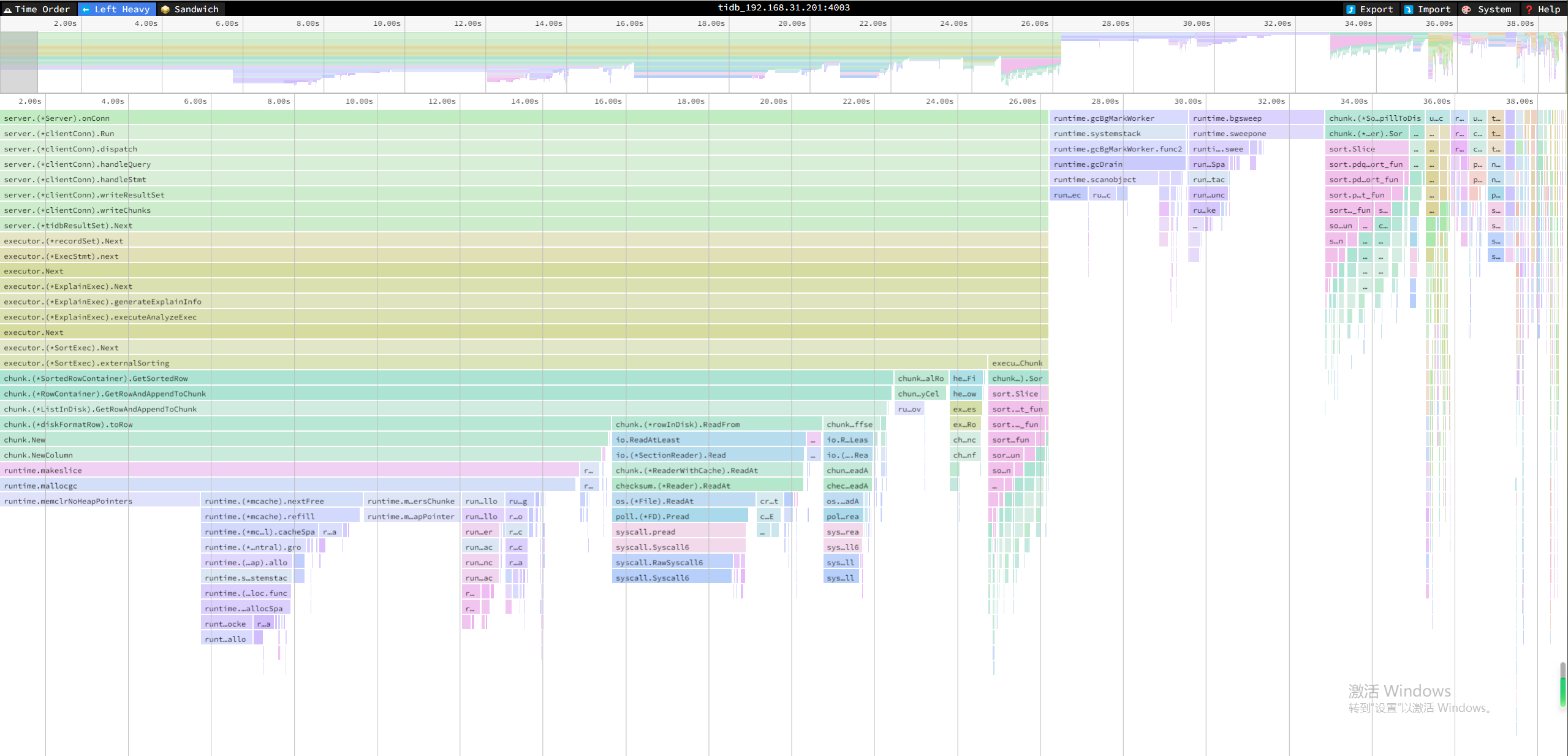
【需求涉及的问题场景】
在测试传统数据库与TiDB数据库性能过程中,关于排序方面,只要涉及到落盘,tidb性能都会有较大折扣。
这里找开源数据库postgresql(下称为:pg)作为测试案例只针对sort算子进行性能对比,对比方式为:
1、全部单线程内存排序,观察效率。
2、全部单线程溢出磁盘排序,观察效率。
3、pg多线程溢出磁盘排序,观察效率。(pg内存排序方式为quicksort不支持并行,溢出磁盘为外部排序支持并行)
其它情况说明:tidb不支持sort并行,因此只测试单线程。
表结构和数据量如下:
mysql> show create table customer \G
*************************** 1. row ***************************
Table: customer
Create Table: CREATE TABLE `customer` (
`C_CUSTKEY` bigint(20) NOT NULL,
`C_NAME` varchar(25) NOT NULL,
`C_ADDRESS` varchar(40) NOT NULL,
`C_NATIONKEY` bigint(20) NOT NULL,
`C_PHONE` char(15) NOT NULL,
`C_ACCTBAL` decimal(15,2) NOT NULL,
`C_MKTSEGMENT` char(10) NOT NULL,
`C_COMMENT` varchar(117) NOT NULL,
PRIMARY KEY (`C_CUSTKEY`) /*T![clustered_index] CLUSTERED */,
KEY `customer_idx1` (`C_PHONE`),
KEY `customer_idx2` (`C_NATIONKEY`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
1 row in set (0.00 sec)
mysql> select count(*) from customer;
+----------+
| count(*) |
+----------+
| 1500000 |
+----------+
1 row in set (0.56 sec)
1、全部单线程内存排序,观察效率。
tidb:
#设置语句内存大小为1GB,表扫描并行度为1;
set tidb_distsql_scan_concurrency=1;
set tidb_mem_quota_query=1073741824;
mysql> explain analyze select * from customer order by C_COMMENT desc, C_ACCTBAL asc;
+-------------------------+------------+---------+-----------+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+----------+---------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+-------------------------+------------+---------+-----------+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+----------+---------+
| Sort_4 | 1500000.00 | 1500000 | root | | time:7.26s, loops:1466 | tpch.customer.c_comment:desc, tpch.customer.c_acctbal | 351.5 MB | 0 Bytes |
| └─TableReader_8 | 1500000.00 | 1500000 | root | | time:1.86s, loops:1471, cop_task: {num: 8, max: 445.5ms, min: 67.7ms, avg: 231.2ms, p95: 445.5ms, max_proc_keys: 297022, p95_proc_keys: 297022, tot_proc: 1.32s, tot_wait: 2ms, rpc_num: 8, rpc_time: 1.85s, copr_cache: disabled, distsql_concurrency: 1} | data:TableFullScan_7 | 128.9 MB | N/A |
| └─TableFullScan_7 | 1500000.00 | 1500000 | cop[tikv] | table:customer | tikv_task:{proc max:173ms, min:34ms, avg: 110.3ms, p80:172ms, p95:173ms, iters:1502, tasks:8}, scan_detail: {total_process_keys: 1500000, total_process_keys_size: 305225771, total_keys: 1500008, get_snapshot_time: 6.43ms, rocksdb: {key_skipped_count: 1500000, block: {cache_hit_count: 5035}}} | keep order:false | N/A | N/A |
+-------------------------+------------+---------+-----------+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+----------+---------+
3 rows in set (7.27 sec)
可以看到copTask在tikv-client缓存大小为128MB,排序全部在内存中进行,使用了351MB,语句总内存使用大小约为500MB。
在pg中测试情况如下:
tpch=# explain analyze select * from customer order by C_COMMENT desc, C_ACCTBAL asc;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Sort (cost=206554.90..210304.40 rows=1499799 width=167) (actual time=12918.633..13180.047 rows=1500000 loops=1)
Sort Key: c_comment DESC, c_acctbal
Sort Method: quicksort Memory: 439757kB
-> Seq Scan on customer (cost=0.00..52702.99 rows=1499799 width=167) (actual time=0.005..111.692 rows=1500000 loops=1)
Planning Time: 0.065 ms
Execution Time: 13237.138 ms
(6 rows)
Time: 13237.643 ms (00:13.238)
可以看到在快排方面,tidb性能要明显好于pg。
(数据加载均只需1.x秒,这里暂时忽略数据读取耗时)
pg需要13秒,430MB内存。tidb只需要7.3秒350MB内存。
2、全部单线程溢出磁盘排序,观察效率。
根据上面测试可以看到copTask在tikv-client缓存大小为128MB,排序全部在内存中进行,使用了351MB,语句总内存使用大小约为500MB。让其进行落盘,内存修改为200MB:
set tidb_distsql_scan_concurrency=1;
set tidb_mem_quota_query=209715200;
mysql> explain analyze select * from customer order by C_COMMENT desc, C_ACCTBAL asc;
+-------------------------+------------+---------+-----------+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+----------+----------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+-------------------------+------------+---------+-----------+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+----------+----------+
| Sort_4 | 1500000.00 | 1500000 | root | | time:39.3s, loops:1466 | tpch.customer.c_comment:desc, tpch.customer.c_acctbal | 144.9 MB | 284.2 MB |
| └─TableReader_8 | 1500000.00 | 1500000 | root | | time:1.94s, loops:1471, cop_task: {num: 8, max: 470.8ms, min: 70.3ms, avg: 241.2ms, p95: 470.8ms, max_proc_keys: 297022, p95_proc_keys: 297022, tot_proc: 1.38s, tot_wait: 4ms, rpc_num: 8, rpc_time: 1.93s, copr_cache: disabled, distsql_concurrency: 1} | data:TableFullScan_7 | 128.9 MB | N/A |
| └─TableFullScan_7 | 1500000.00 | 1500000 | cop[tikv] | table:customer | tikv_task:{proc max:186ms, min:34ms, avg: 112.4ms, p80:174ms, p95:186ms, iters:1502, tasks:8}, scan_detail: {total_process_keys: 1500000, total_process_keys_size: 305225771, total_keys: 1500008, get_snapshot_time: 7.08ms, rocksdb: {key_skipped_count: 1500000, block: {cache_hit_count: 5035}}} | keep order:false | N/A | N/A |
+-------------------------+------------+---------+-----------+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+----------+----------+
3 rows in set (39.30 sec)
可以看到外部排序需要花费39.3秒。
在pg中测试情况如下:
关闭pg并行,设置排序区内存大小为50MB(小于tidb排序使用内存):
tpch=# set work_mem=51200;
tpch=# set max_parallel_workers_per_gather=1;
SET
Time: 0.397 ms
tpch=# explain analyze select * from customer order by C_COMMENT desc, C_ACCTBAL asc;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Gather Merge (cost=207024.61..308481.63 rows=882235 width=167) (actual time=4737.983..7385.264 rows=1500000 loops=1)
Workers Planned: 1
Workers Launched: 1
-> Sort (cost=206024.60..208230.19 rows=882235 width=167) (actual time=4507.940..5643.202 rows=750000 loops=2)
Sort Key: c_comment DESC, c_acctbal
Sort Method: external merge Disk: 143792kB
Worker 0: Sort Method: external merge Disk: 123336kB
-> Parallel Seq Scan on customer (cost=0.00..46527.35 rows=882235 width=167) (actual time=0.008..61.661 rows=750000 loops=2)
Planning Time: 0.066 ms
Execution Time: 7468.150 ms
(10 rows)
可以看到pg外部排序需要7.4秒,比全内存的快排要快接近1倍。
可以看到在溢出到磁盘的外部排序放,pg性能要明显好于tidb。
pg需要7.5秒,tidb需要39.3秒。
tidb主要耗时都是花在磁盘等待相关处理上:
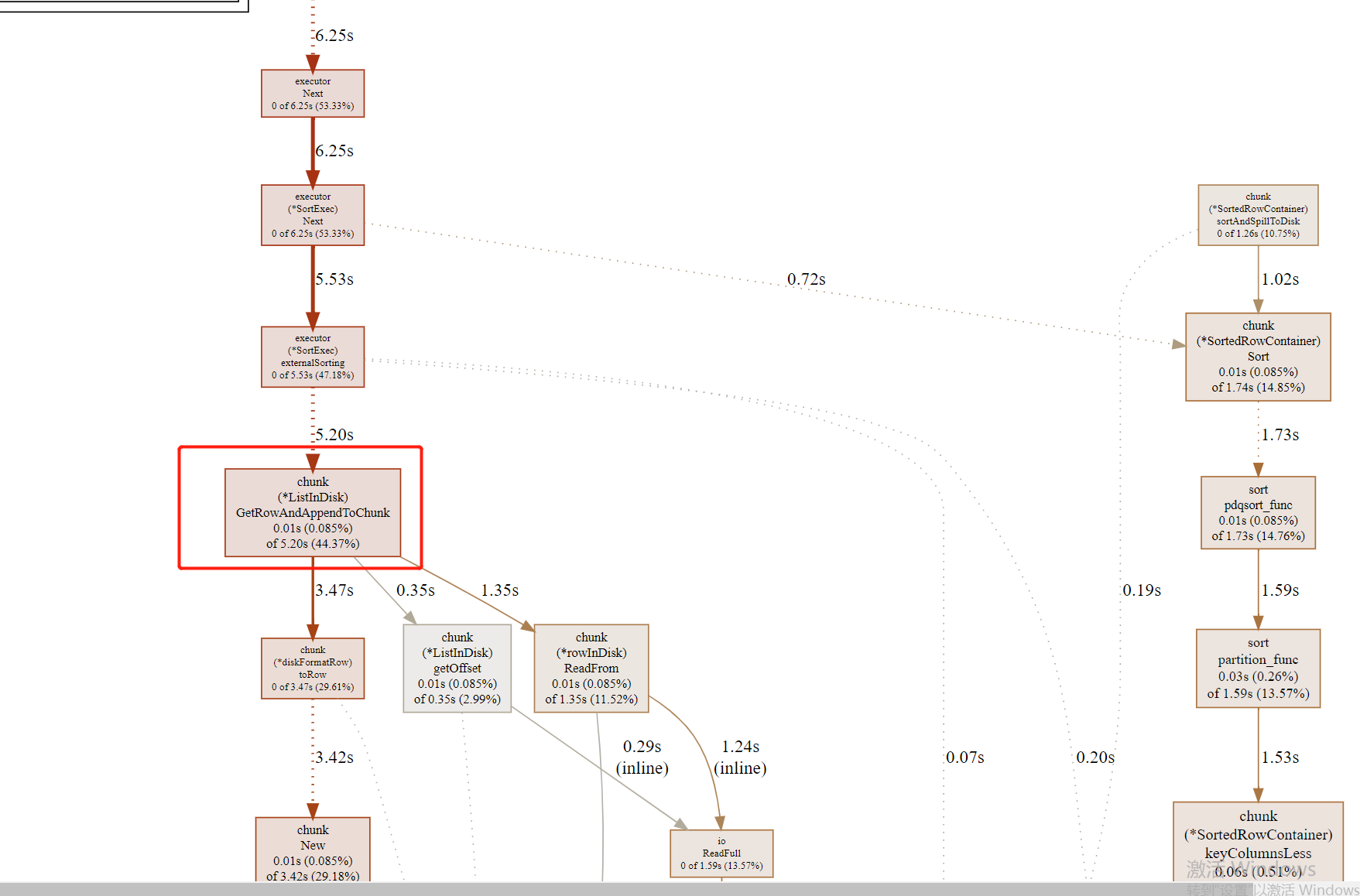
3、pg多线程溢出磁盘排序,观察效率
#开启并行:
set max_parallel_workers_per_gather=4;
#将sort工作区设置为50MB。(比tidb的sort算子可用内存小)
set work_mem=51200;
tpch=# explain analyze select * from customer order by C_COMMENT desc, C_ACCTBAL asc;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Gather Merge (cost=107926.06..287503.96 rows=1499799 width=167) (actual time=2829.578..6503.408 rows=1500000 loops=1)
Workers Planned: 4
Workers Launched: 4
-> Sort (cost=106926.00..107863.38 rows=374950 width=167) (actual time=2618.420..2836.848 rows=300000 loops=5)
Sort Key: c_comment DESC, c_acctbal
Sort Method: external merge Disk: 62128kB
Worker 0: Sort Method: external merge Disk: 79400kB
Worker 1: Sort Method: external merge Disk: 31752kB
Worker 2: Sort Method: external merge Disk: 62128kB
Worker 3: Sort Method: external merge Disk: 31744kB
-> Parallel Seq Scan on customer (cost=0.00..41454.50 rows=374950 width=167) (actual time=0.010..57.328 rows=300000 loops=5)
Planning Time: 0.148 ms
Execution Time: 6571.564 ms
(13 rows)
可以看到在并行方面pg的外部排序并没有太大性能提升(但是通过观察CPU多了几倍的消耗)。
总体结论:tidb的外部排序比pg要慢几倍。
因此希望tidb的外部排序可以进一步优化,比如将溢出磁盘的行为作为异步的方式,来减少非排序时间的消耗,进而增加整体排序效率。