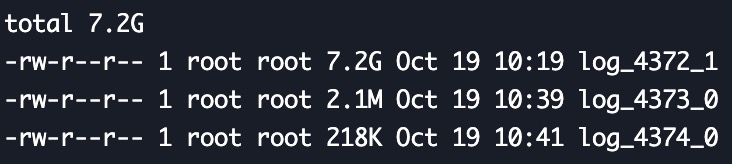
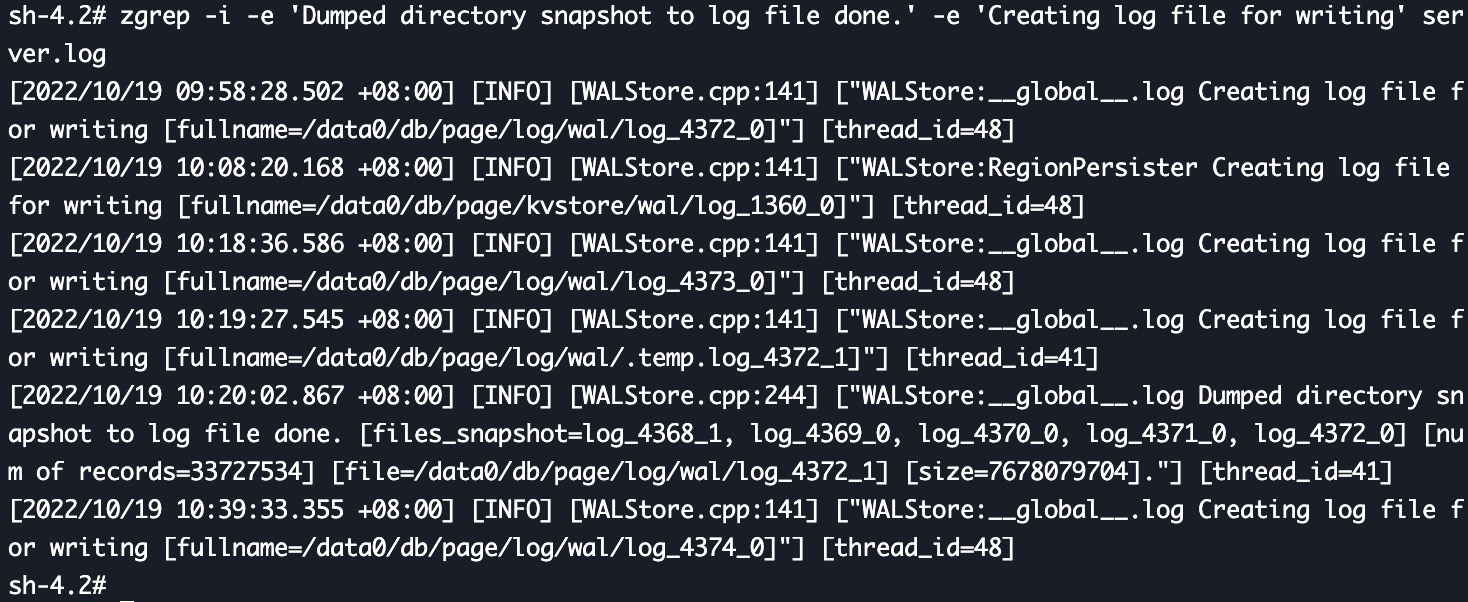

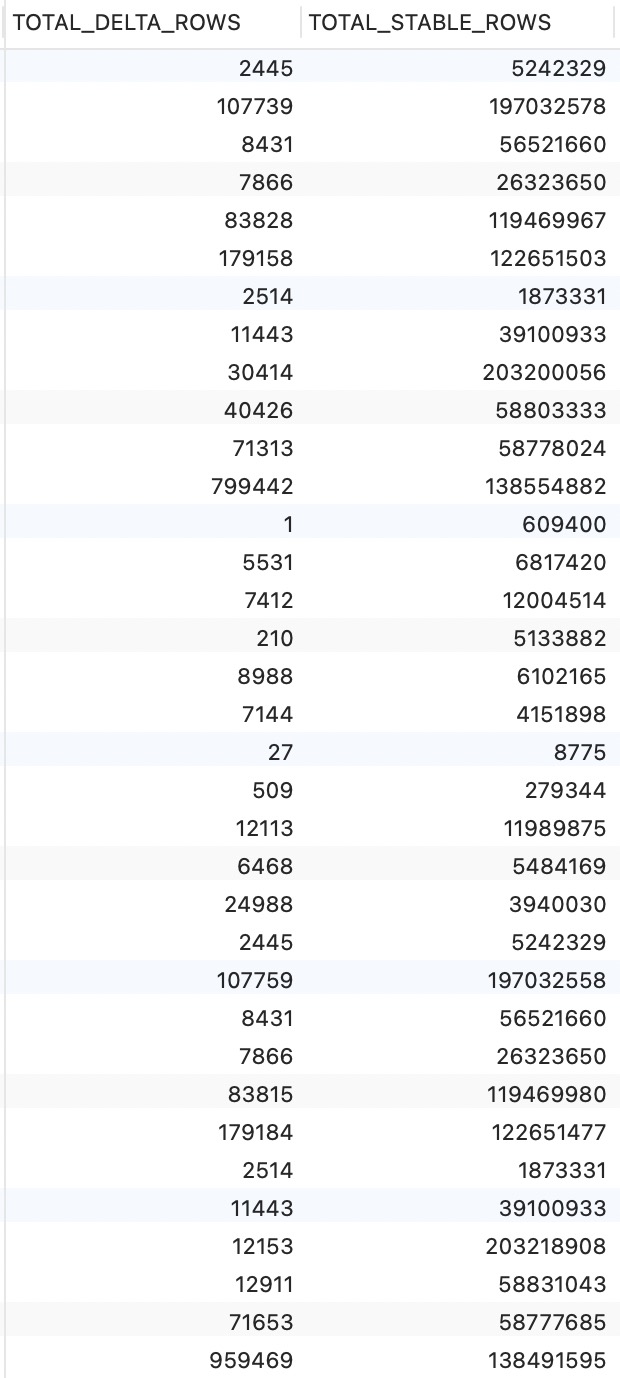
今天观测了一下数据,还是有内存短暂激增情况,wal目录下log_xxxx_1文件持续在增长中,执行手动整理命令可以减少total_delta_rows数值,但并不能减少log_xxxx_1和page的大小,日常使用的内存也在持续增加中,经过一个昼夜的时间,已经由昨天的6GB增长至12GB左右。
慢查sql都是select,目前的状况是会触发持续的OOM
嗯,我们继续看这个问题
目前确认一共有两个问题:
- 上面 Jayson 说的 delta 层碎片文件没有整理,导致碎片文件太多。这个可以通过定期手动 compact tiflash replica 来缓解。 https://github.com/pingcap/tiflash/issues/6159 根本原因还在调查中,预计 v6.4 修复。
- Page 被删除后,GC 不能正确回收空间,导致每次 GC 需要处理的数据越来越大,最后 OOM。 https://github.com/pingcap/tiflash/issues/6163 。原因已经确认,预计 v6.4 修复,修复后升级即可解决。不过目前版本还没有缓解手段,我们迟点会提供一个工具,需要停机处理一下数据。
好的,这边TiDB是运行在K8S中,停机处理怕是有难度
你得解决慢sql才能防止oom
你好,请问 server.log 目录下有没有类似 error.log 文件?另外这个集群上会有比较频繁的 ddl 操作吗?@ TiDBer_qqabzOs3
hmmm,我们可以出一个 6.2.0 bugfix 分支,你可以考虑自己编译一下。
可以编译,但还是建议你们这边是否出一个封装好的docker image,这样更可靠一些,毕竟是这边是生产在用
sql是否走tiflash是在tidb server层路由的,是不是有些该走tiflash的走了tikv
https://github.com/pingcap/tiflash/issues/6163 相应的修复已经经过测试合入 master,目前在跑更多的端到端测试验证中。
会在 v6.4 中得到修复,解决内存波动导致 OOM 的问题。
1 个赞
有预计发版时间吗
有结果了嘛?
等待v6.4.0版本
6.4 计划 11 月中发布哈
居然需要新版本。。。是bug嘛?
学习了 tiflash得不断的整理碎片
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。