【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.2.0
【遇到的问题】
【复现路径】目前无法复现
【问题现象及影响】
经常有内存徒增,接近十倍的落差,触发OOM事件,但重启后一直进入循环OOM,除非增加tiflash内存配置才可解决。
请问这有什么排查思路和方法
var/log/message 中的报错信息来一份
请问下业务上是否存在大事务的情况?事务大小有多大,以及 tiflash 内置增加了多少?
另外麻烦发一下
- tiflash-summary 的监控,用这个方式导出:https://metricstool.pingcap.com/
- 重启期间的 tiflash.log, tiflash-tikv.log
本地没有message,是部署在K8S里面的,有tiflash的日志
没有找到tiflash.log、tiflash-tikv.log,只在tiflash里面找到server.log日志,目前在db/page/log/wal目录下,定位到有大的文件,但是不太明白怎么去定位SQL
找大事务,可以看一下 TiDB Dashboard / Slow Queries,时间范围选择 OOM 发生之前一段时间,看看有没有 Max Memory 比较大的。
一直尝试在找大的事务,但是定位到有大内存的,偶尔会有大内存的查询,但是都是tikv的,并不是tiflash,或者有无日志的字段说明,可以从日志中分析一下
dashboard看看站内存多的sql,然后看看执行计划是不是cop[tiflash]
然后着重优化下这种sql
“大内存的查询” 有涉及数据更新操作吗?如果有,更新数据量大概有多大?
这边一直在追踪这个,但是大的内存的基本都是查询的SQL,并且有些时间对不上,其余的基本都是KB级,偶有MB的,tiflash oom后会一直重启,正常查询SQL重启后会应该不再执行的,但tiflash好像有绕不过去的任务,只有升配处理完才能结束OOM
目前已知的会触发类似 tiflash 反复 OOM,并且通过提升内存配置可以缓解的问题,只有 TiDB 跑大的更新事务。所以我想确认一下。
可以看看在 OOM 之前,业务是否有其他特殊的操作?
另外麻烦发一下包含 OOM 重启时间段的日志,包括 server.log,proxy.log
1.zip (26.0 MB)
包含有三个文件,上午9:30的文件是OOM中的,10:30左右升配置解决,server.log是下午的日志,出现了内存徒增的情况,但没有触发oom
收到。另外麻烦也导出 grafana
- tiflash-summary 的监控,用这个方式导出:https://metricstool.pingcap.com/


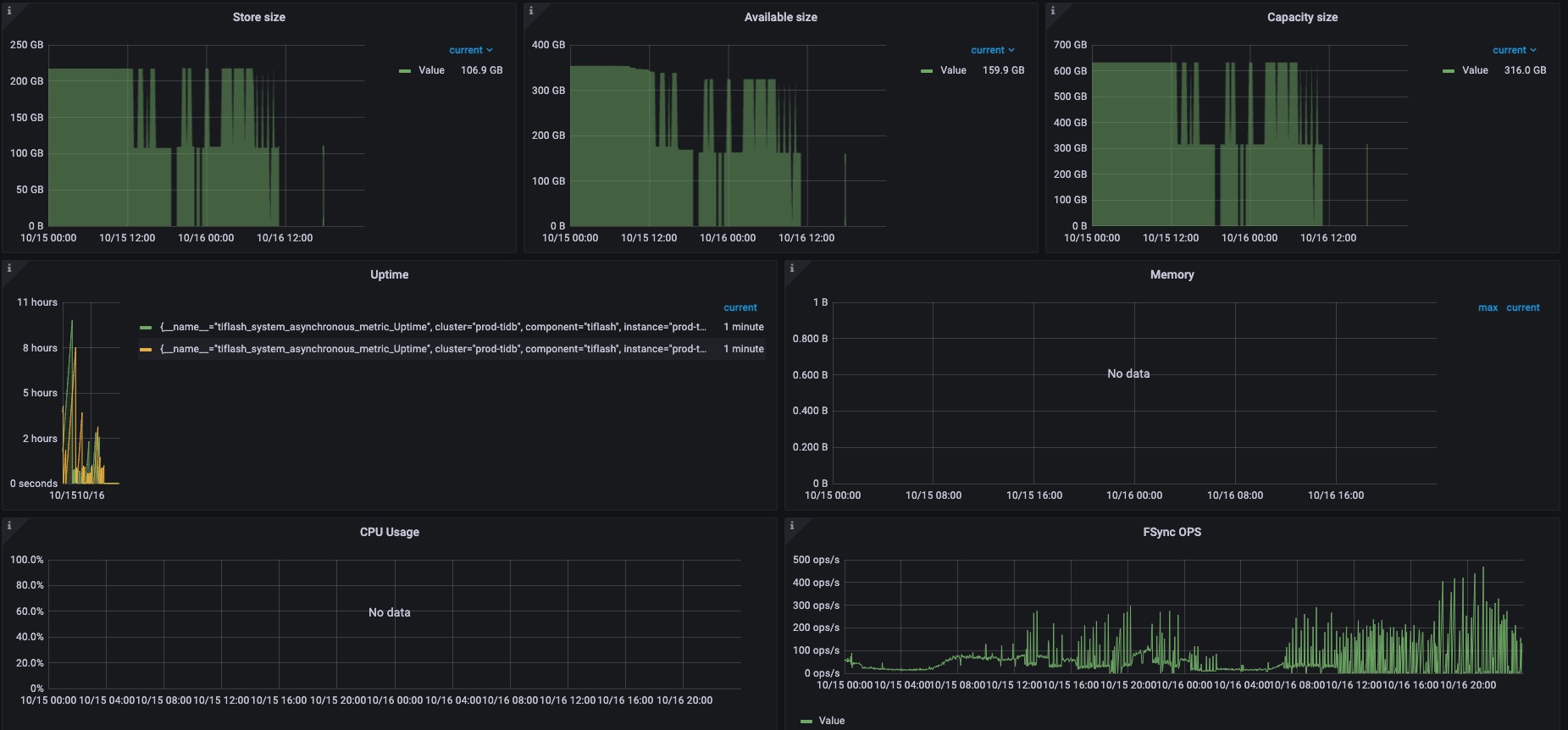
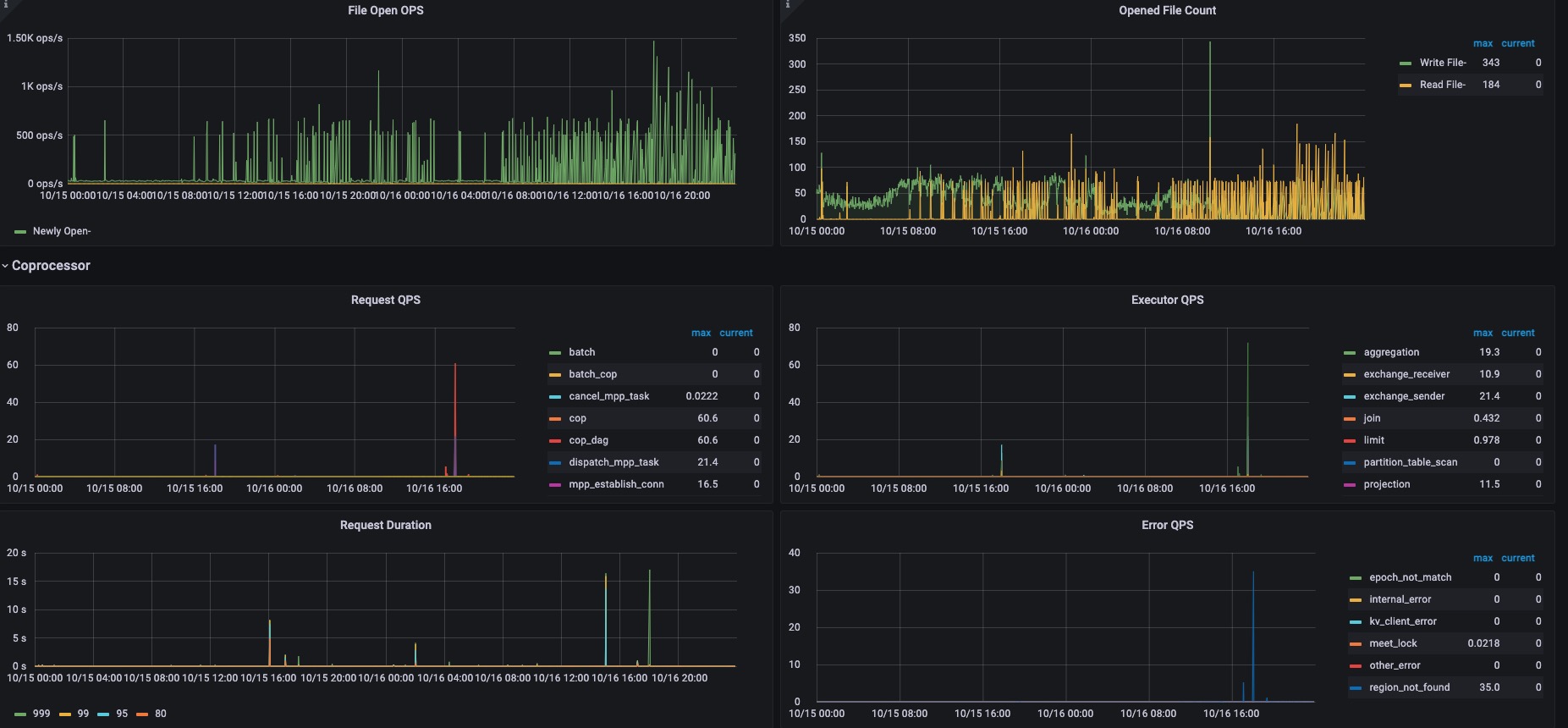
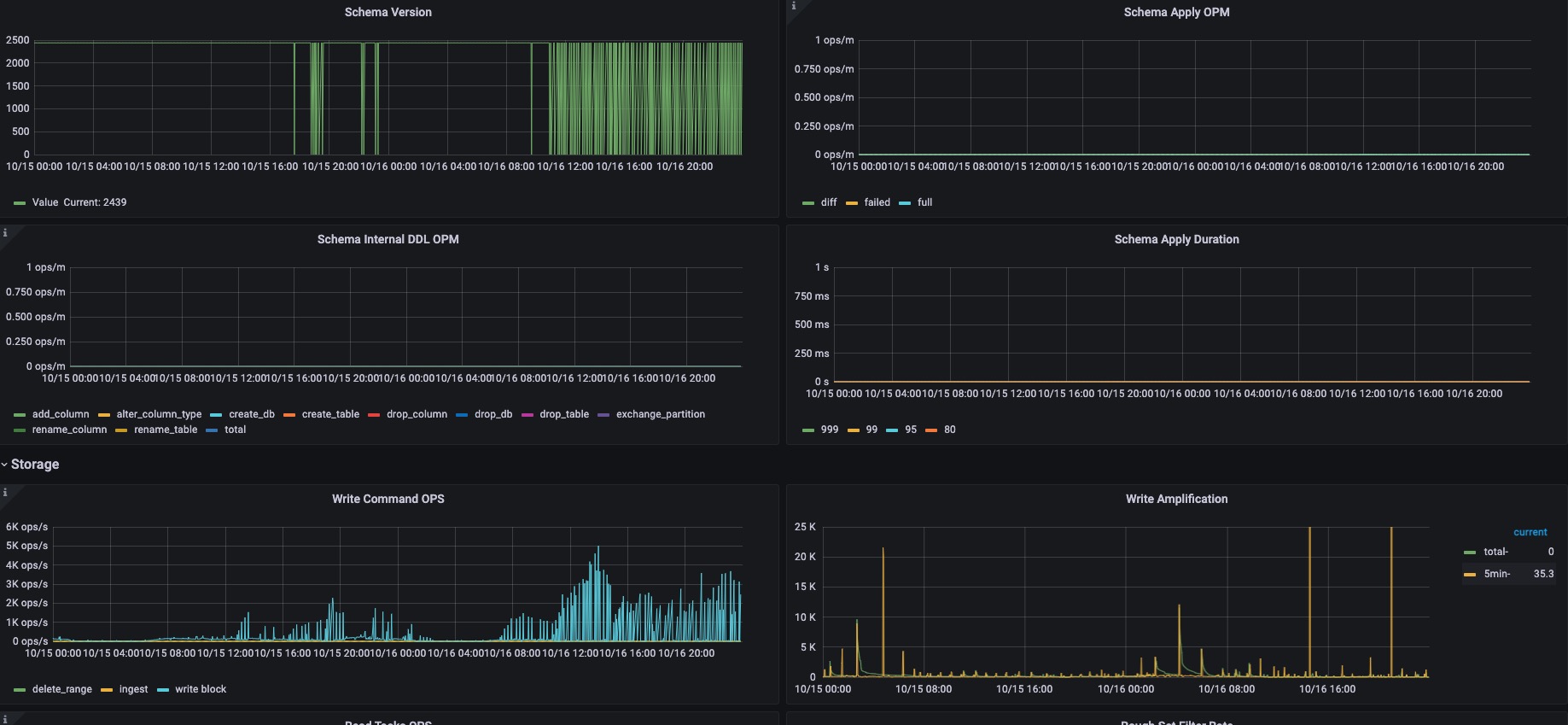
好的,我们先分析一下
有进展吗
还在调查中。目前从日志中发现了一个太多数据碎片没有整理的问题。至于是否会引起 OOM,以及出现的原因还在调查。
不过这个现象肯定会引起系统亚健康,所以可以尝试手动整理数据,看看是否有改善:ALTER TABLE xxx COMPACT TIFLASH REPLICA;
https://docs.pingcap.com/zh/tidb/v6.2/sql-statement-alter-table-compact

这个整理是需要对所有的tiflash表单独执行整理命令吗?还是说可以分析出是哪个表?
建议所有表都跑一遍吧,串行跑。