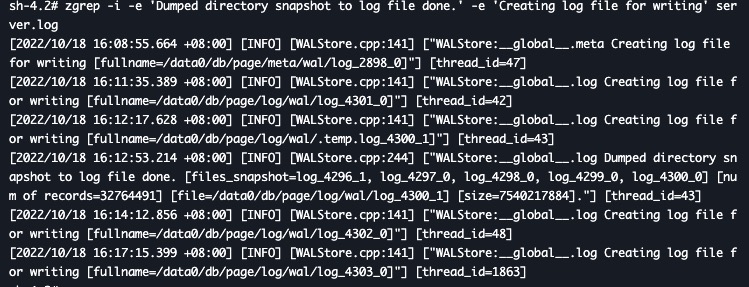
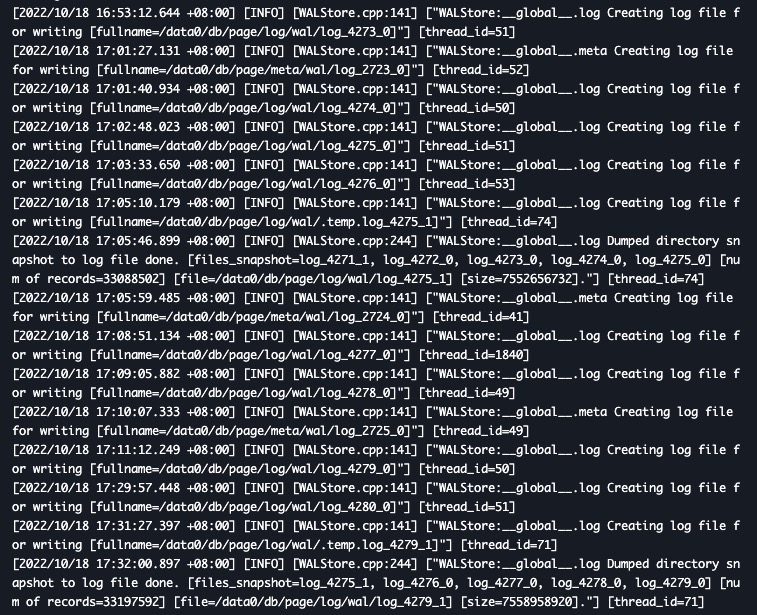
在最近的日志里面用下面的命令搜索下关键词,贴一下相关日志
zgrep -i -e 'Dumped directory snapshot to log file done.' -e 'Creating log file for writing' server.log
在最近的日志里面用下面的命令搜索下关键词,贴一下相关日志
zgrep -i -e 'Dumped directory snapshot to log file done.' -e 'Creating log file for writing' server.log
db/page/log/wal/log_xxx_1 里面存储的是持久化的 page index 信息。从日志看现在存储引擎的数据碎片没有得到整理,存储的 page 个数超过 3200万个,导致内存占用比较大。通过上面 ALTER TABLE xxx COMPACT TIFLASH REPLICA 的命令整理完之后,数据会得到整理,碎片量下来后,内存占用也会下降。
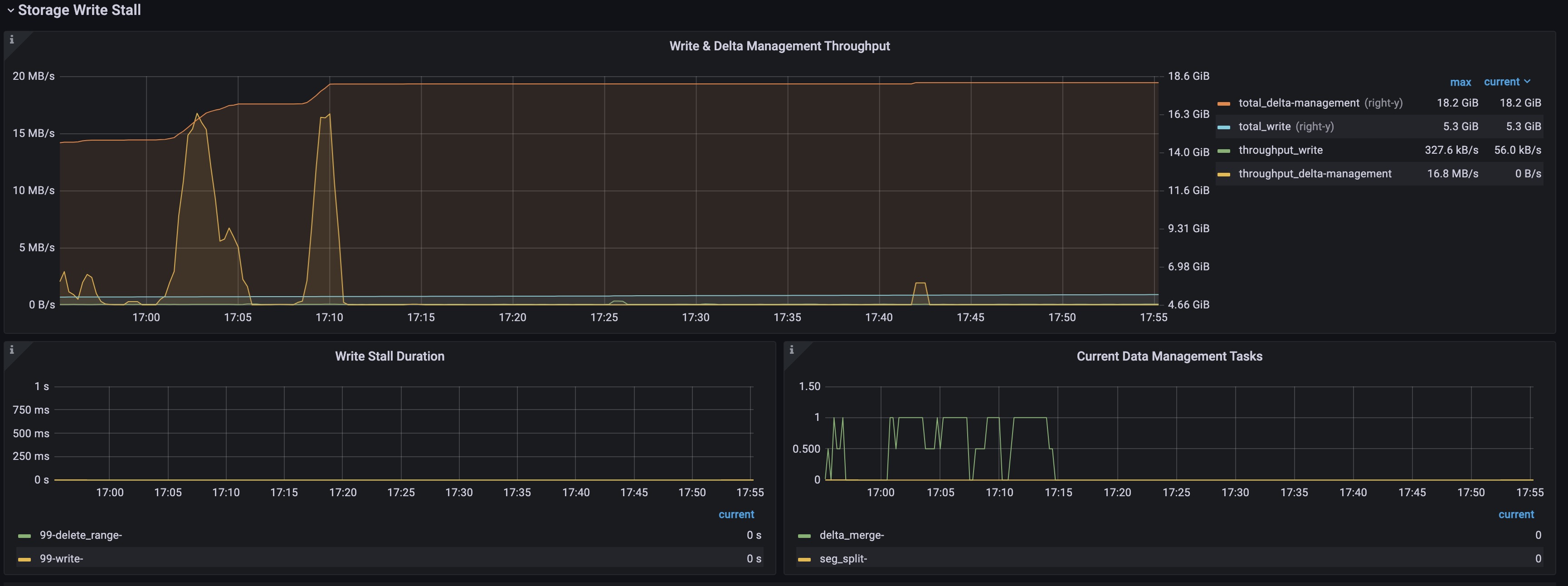
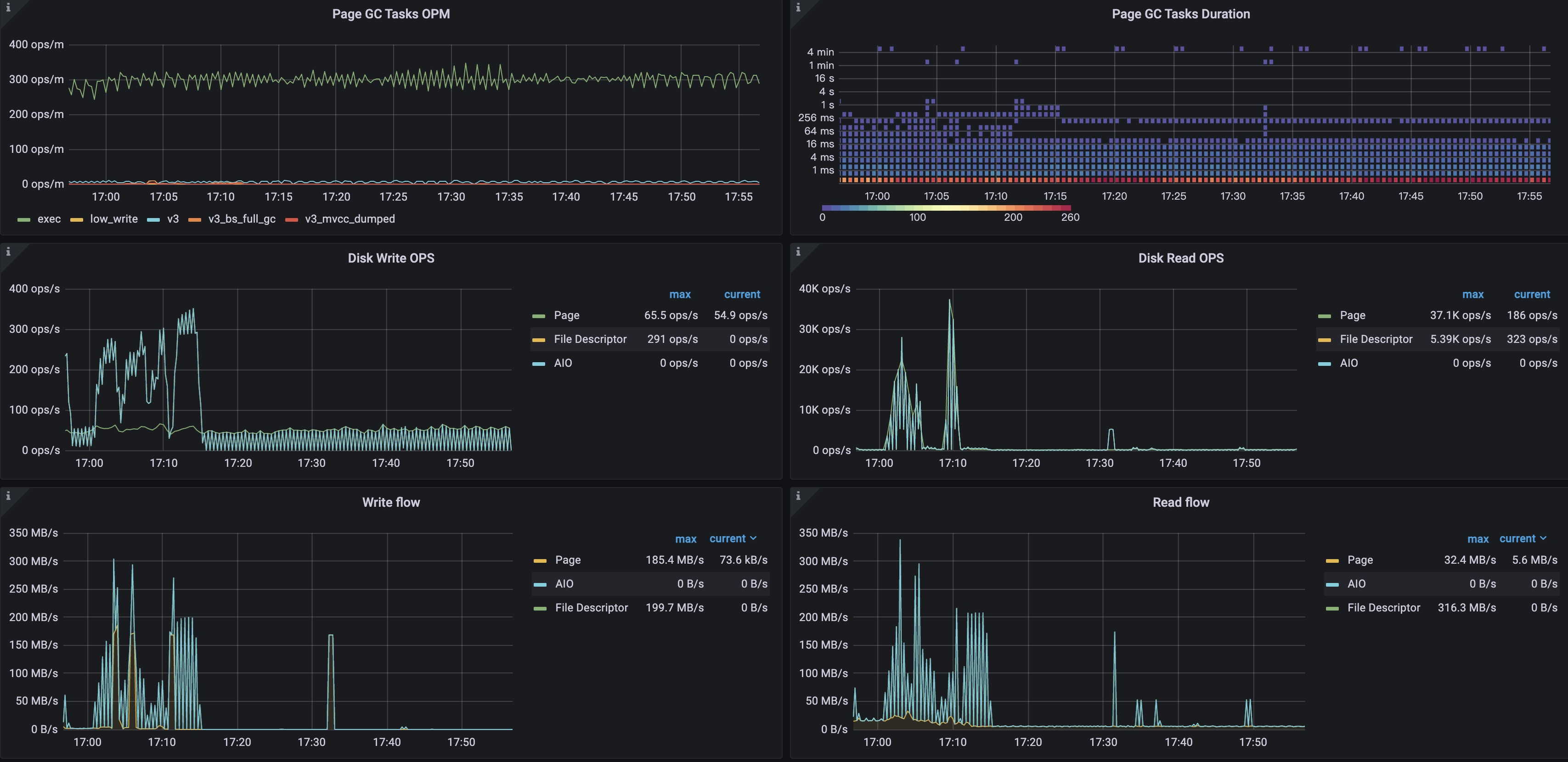
上面 grafana 截图中没能显示内存信息。请问之前 OOM 时候 tiflash 的内存上限是多大,以及现在 tiflash 的运行内存上限是多大?
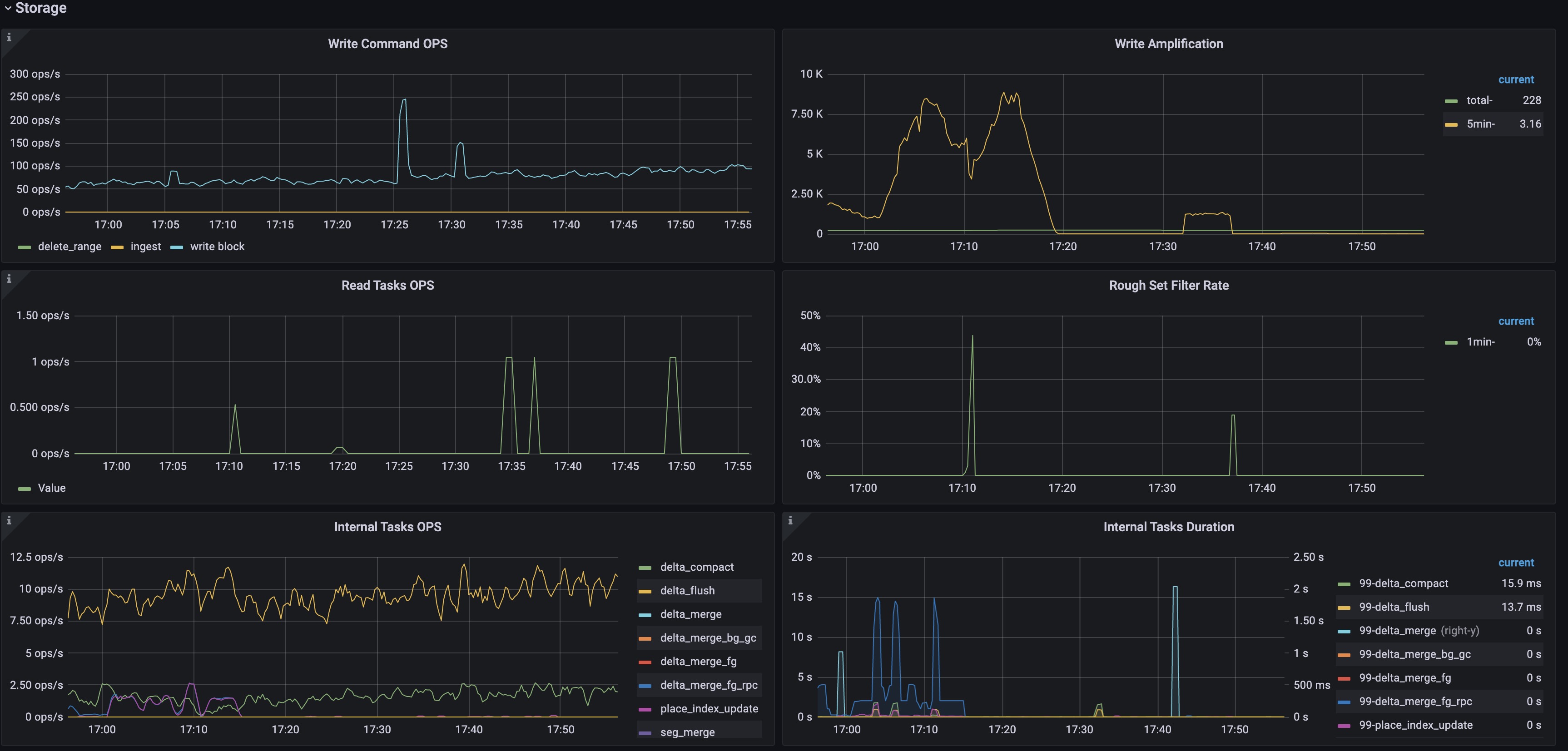
发现有清理后total_delta_rows依然不为0,即又继续增长
在表上持续有写入的情况下,total_delta_rows 在整理后依然不为 0 是正常的。继续整理其他表就可以了。
预期上面日志里面的 num of records 能够降下来,相应的文件也应该变小。现在的情况不是很符合预期。
在 tidb 中执行下面 sql
select table_id,tiflash_instance,total_pack_count_in_delta,storage_stable_oldest_snapshot_lifetime,storage_delta_oldest_snapshot_lifetime,storage_meta_oldest_snapshot_lifetime from information_schema.tiflash_tables where tidb_database not in ('mysql') order by total_pack_count_in_delta desc;
以及截图看下 Grafana 的 TiFlash-Summary 中 Storage->MVCC Snapshots 面板
请问上面最后一次内存激增的时间点是发生在 17:32 左右么?到目前还有再次出现内存激增的情况么?
另外整理完成后,一些表的total_delta_rows数量持续增加,属于只增不减
tiflash的内存也在逐步对增加,日常的内存目前已由6GB左右逐步增长至8GB左右
手动整理后,有数据写入的情况下,total_delta_rows 持续增长是符合预期的,并且预期最终会稳定在 3% 以内。从目前信息来看,基本确定内存激增和 delta 层的碎片文件太多,导致对应的 page 多(一个 delta 层文件对应一个 page),最终 page gc 过程占用太大内存。
预期之后 tiflash oom 问题会缓解,可以继续观察一下。另外因为导致 delta 层的碎片文件不整理的原因还没有找到,所以碎片文件可能还会变多,所以建议定时跑手动整理脚本,比如每天跑一次。
我们继续调查碎片文件不会自动整理的问题
好,我明天再持续观察一下,我们版本过程是v5.4.0 --> v6.1.0 --> v6.2.0,可以提供一下参考,此问题是在升级v6.2.0后遇到的
另外我们在升级至v6.2.0版本后,曾出现一次个别表索引异常情况,实际索引与查询到的索引数量不一致,索引不可用状态,删除索引重建顺利解决
感谢反馈,我们记录下来了
另外观察到你们 Grafana 的面板比较老旧了,应该是相应的 json 文件没有更新。可以尝试根据下面的步骤根据6.2 版本的 json 创建新的面板:
下载该 json 文件
https://raw.githubusercontent.com/pingcap/tiflash/v6.2.0/metrics/grafana/tiflash_summary.json
在 Grafana 中上传该 json 文件导入
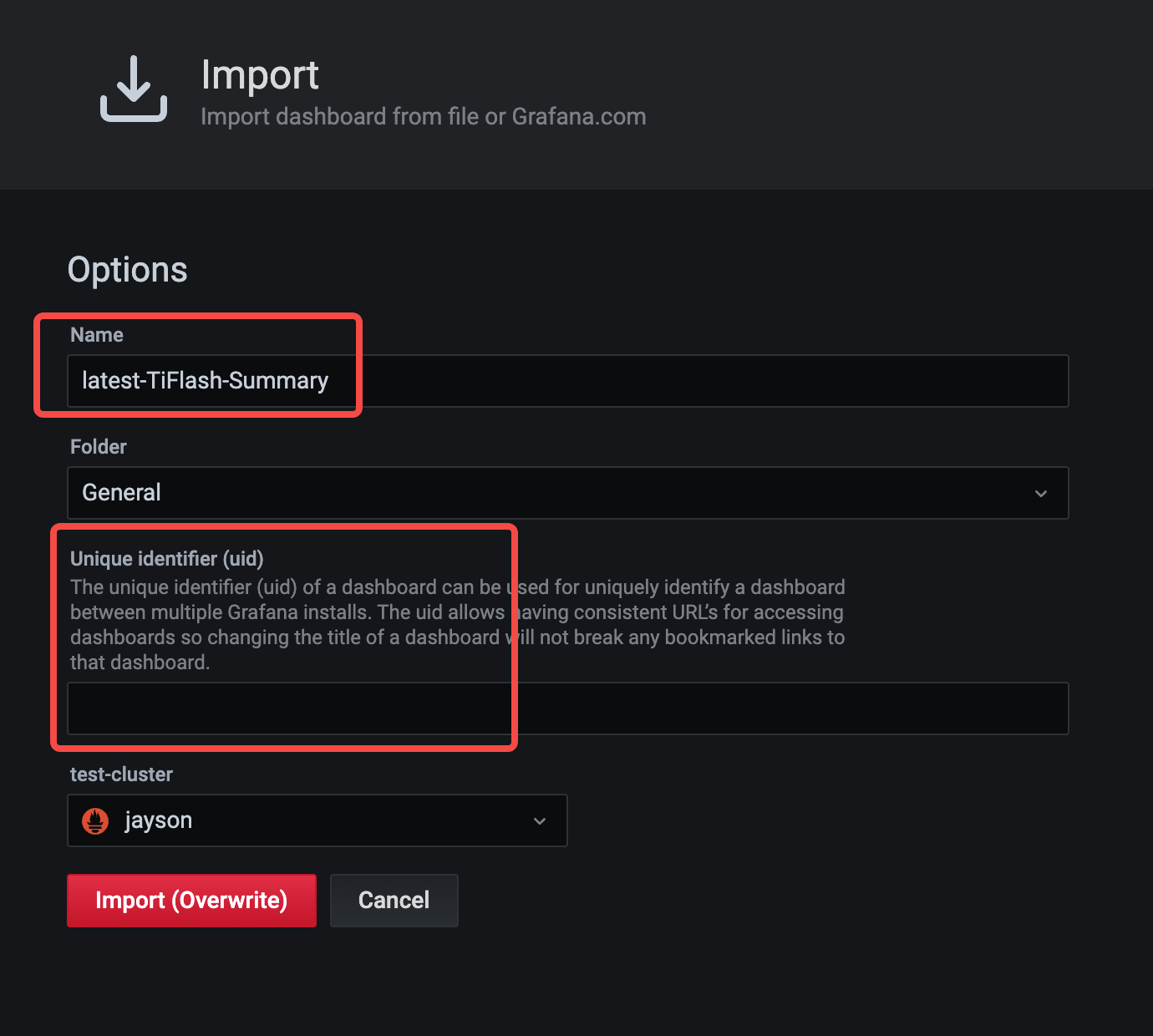
更新下 Name,并将 uid 置为空
delta 层的碎片文件不整理的相应 issue: https://github.com/pingcap/tiflash/issues/6159 。
已同步,感谢
你先需要解决慢sql 去dashboard看慢sql