版本v5.3.3
请问一下
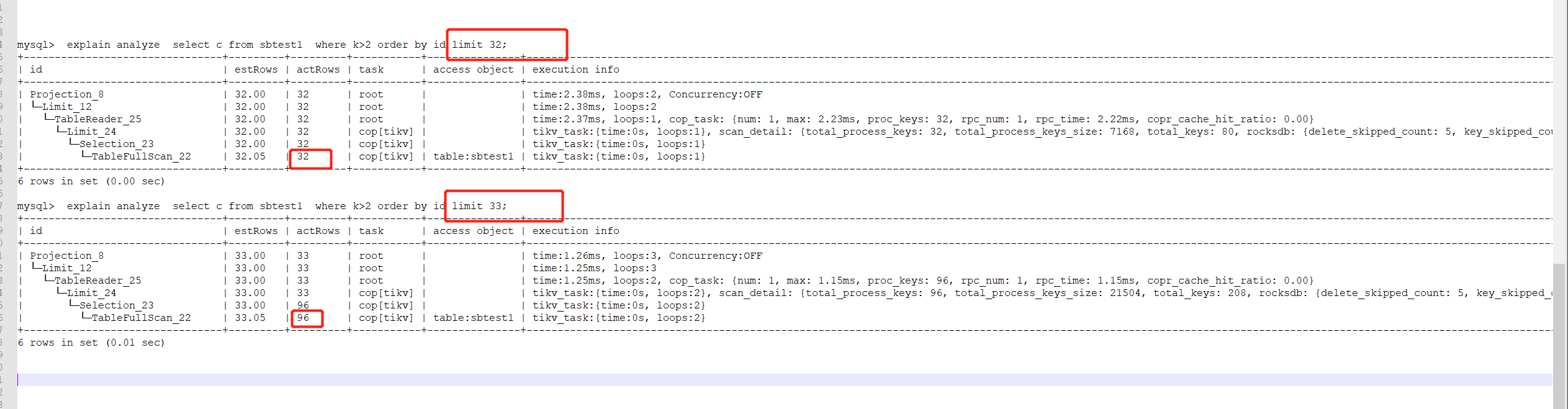
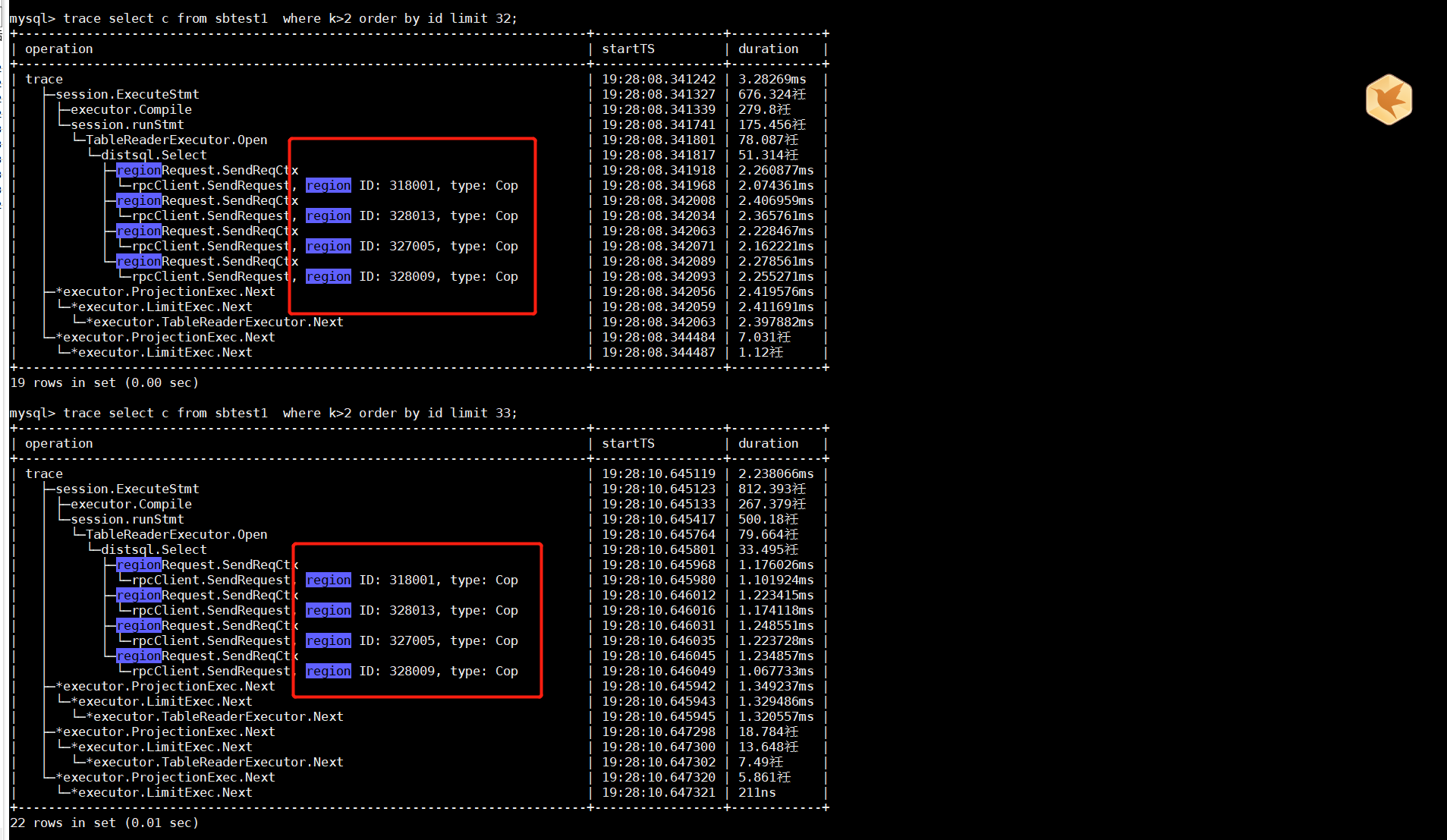
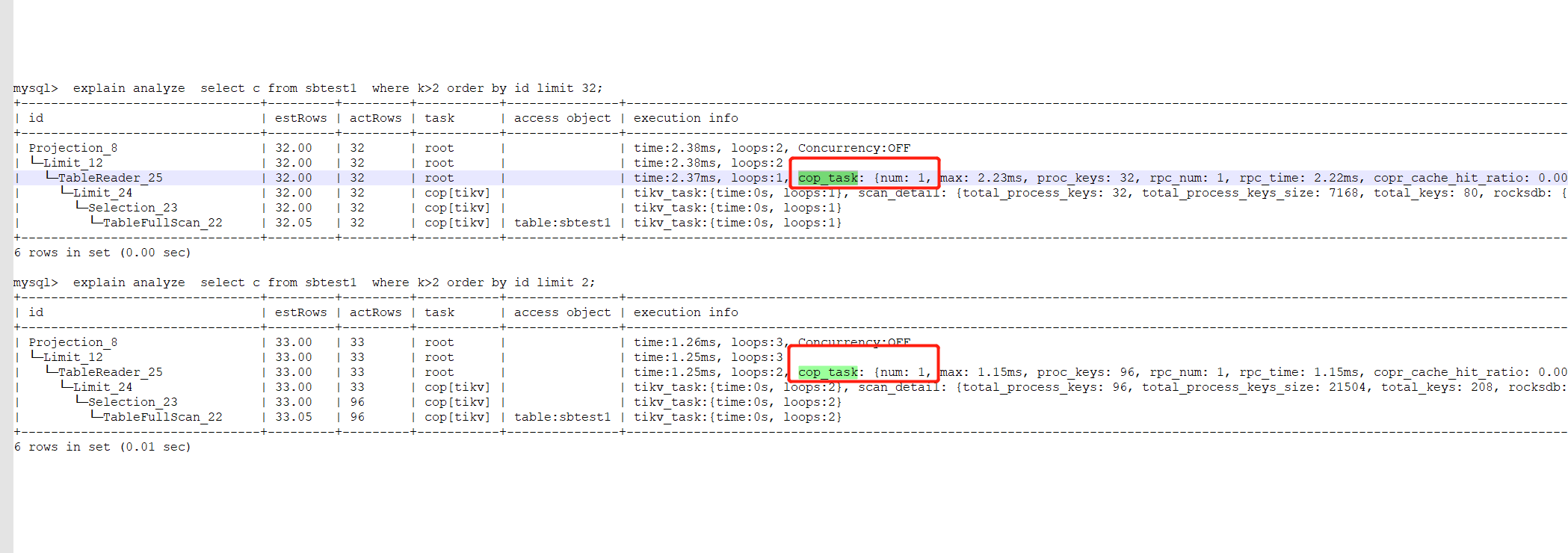
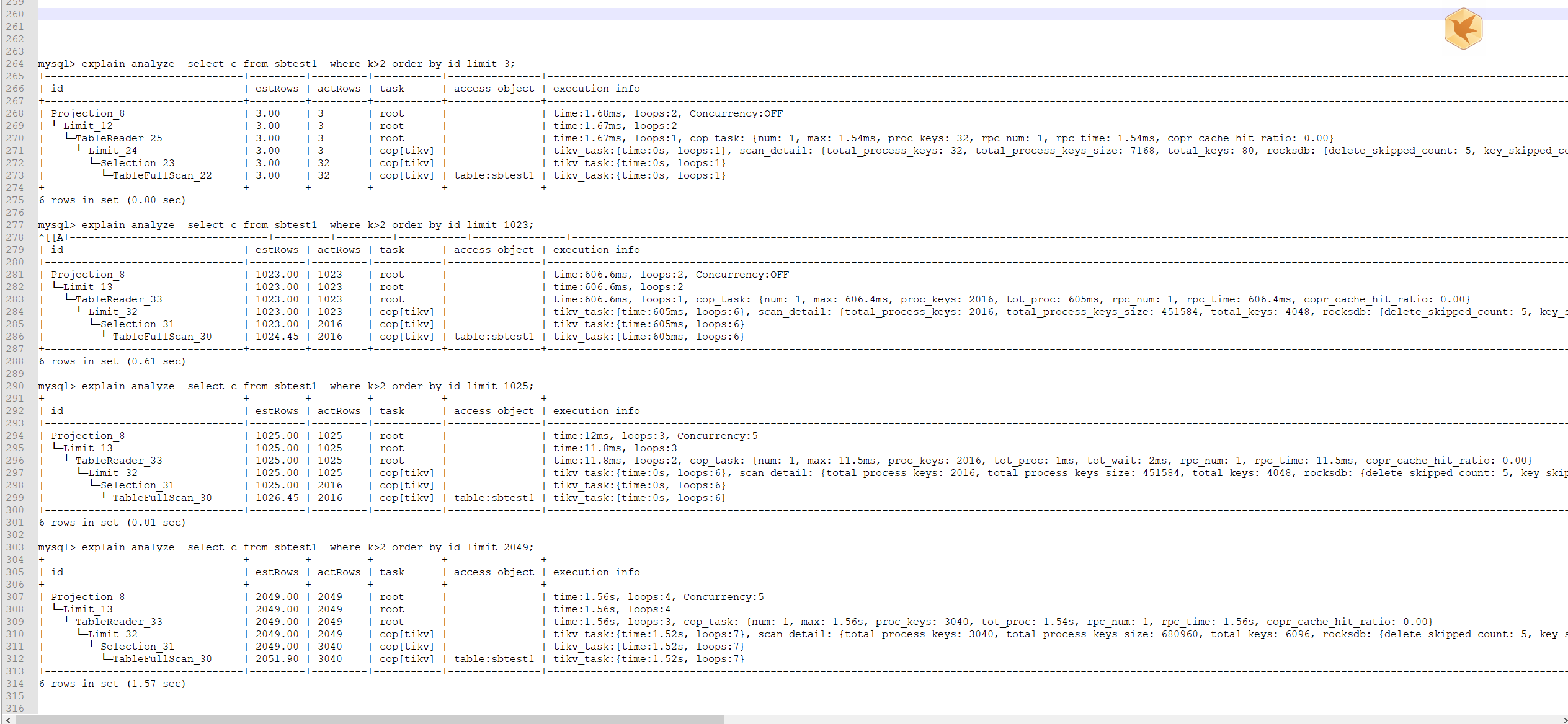
利用sysbench 导入了表数据到tidb以后,对sbtest1表进行了如下查询select c from sbtest1 where k>1 order by id limit 2;
表结构
执行计划
mysql> explain analyze select c from sbtest1 where k>1 order by id limit 2;
±-------------------------------±--------±--------±----------±--------------±----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------±------------------------±----------±-----+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
±-------------------------------±--------±--------±----------±--------------±----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------±------------------------±----------±-----+
| Projection_8 | 2.00 | 2 | root | | time:1.87ms, loops:2, Concurrency:OFF | sbtest.sbtest1.c | 646 Bytes | N/A |
| └─Limit_12 | 2.00 | 2 | root | | time:1.87ms, loops:2 | offset:0, count:2 | N/A | N/A |
| └─TableReader_25 | 2.00 | 2 | root | | time:1.86ms, loops:1, cop_task: {num: 1, max: 1.81ms, proc_keys: 32, rpc_num: 1, rpc_time: 1.8ms, copr_cache_hit_ratio: 0.00} | data:Limit_24 | 2.10 KB | N/A |
| └─Limit_24 | 2.00 | 2 | cop[tikv] | | tikv_task:{time:0s, loops:1}, scan_detail: {total_process_keys: 32, total_process_keys_size: 7168, total_keys: 80, rocksdb: {delete_skipped_count: 5, key_skipped_count: 84, block: {cache_hit_count: 2, read_count: 0, read_byte: 0 Bytes}}} | offset:0, count:2 | N/A | N/A |
| └─Selection_23 | 2.00 | 32 | cop[tikv] | | tikv_task:{time:0s, loops:1} | gt(sbtest.sbtest1.k, 1) | N/A | N/A |
| └─TableFullScan_22 | 2.00 | 32 | cop[tikv] | table:sbtest1 | tikv_task:{time:0s, loops:1} | keep order:true | N/A | N/A |
±-------------------------------±--------±--------±----------±--------------±----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------±------------------------±----------±-----+

这里为什么选择table full scan的原因我猜想如下
1.因为id是主键,在全表扫描的过程中如果遇到k>1的话,直接就可以取出c字段的值,这个时候id本身就是有序的了,不需要额外排序,所以只要遇到2次k>1的值,这条语句就可以跑完了,这个时候全表扫描并不慢,但我认为这是建立在k>1的值全表扫描很快就能找到
但是有可能存在这么一个情况,假设满足k>1的值需要全表扫描很久才能找到,那是不是说明这个时候全表扫描并不是最优的解决方案?这个时候,可能利用k字段的索引去查找反而是更优的解决方案,不知道这样的猜想对不对
对比MySQL的执行计划,MySQL优化器的默认行为也是类似tidb这种全表扫描(直接扫描整个主键索引),但是通过参数调整,可以让优化器选择走k字段索引
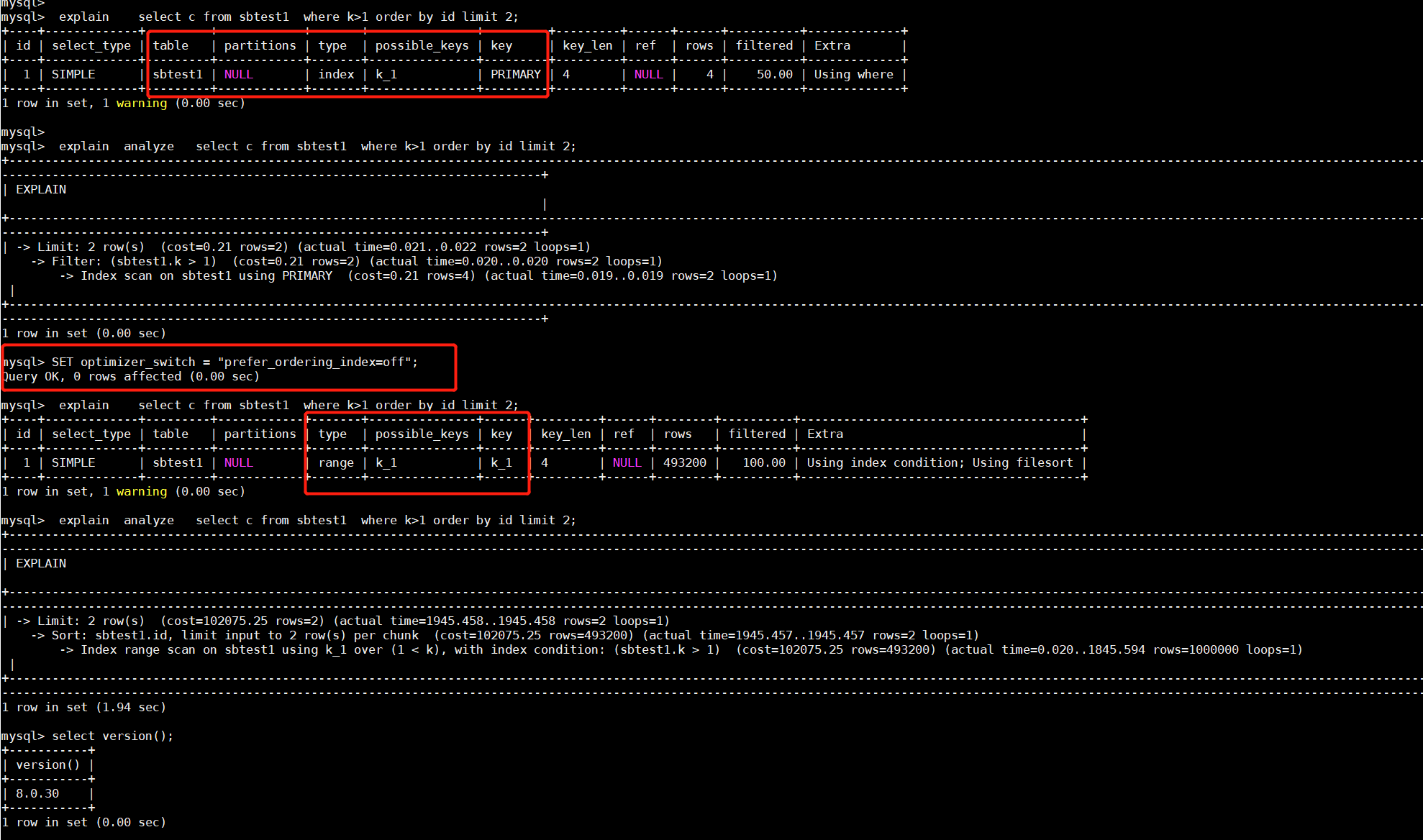
2.不是很能够理解,tidb的执行计划,actRows是32?这里请问怎么解释