是的。上面老哥们说的应该是tikv的行为。看现象是一个cop_task请求在tikv侧初始值是32,然后每次翻倍直到1024。
感谢老哥
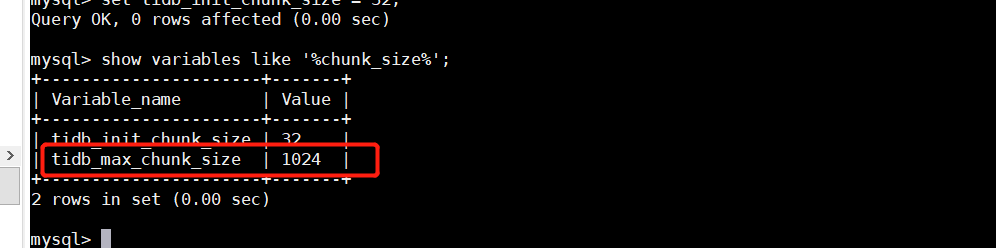
是这个. 初始化是
tidb_init_chunk_size
- 作用域:SESSION | GLOBAL
- 是否持久化到集群:是
- 默认值:
32 - 范围:
[1, 32] - 这个变量用来设置执行过程中初始 chunk 的行数。默认值是 32,可设置的范围是 1~32。
数据返回是以chunk为单位,32应该是默认初始大小当请求—>这个32就是tidb_init_chunk_size系统变量决定的吧,但我把tidb_init_chunk_size 设置为20,limit 2,actRows显示也是32?
我测试是tidb的系统参数:tidb_init_chunk_size,tidb_max_chunk_size对tikv的chunk不生效。tikv侧chunk的最小初始值一直是32行,最大值一直是1024行。具体测试过程可见附件:tikv侧chunk的行为.txt (19.4 KB)
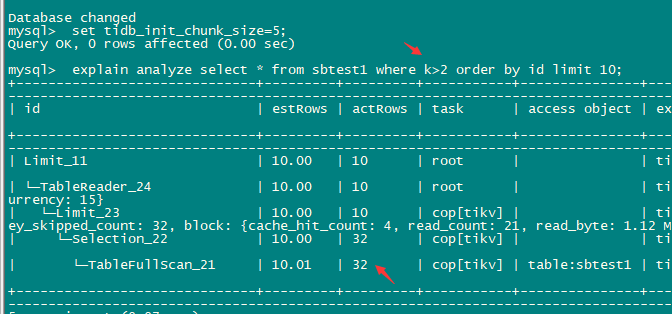
我刚试了下如过是SQL:select * from sbtest1 where k>2 order by id limit 10; 带有k>2 条件时tidb_init_chunk_size 不起作用仍然是actrows 32
如果是SQL:select * from sbtest1 order by id limit 10; tidb_init_chunk_size 是起作用的
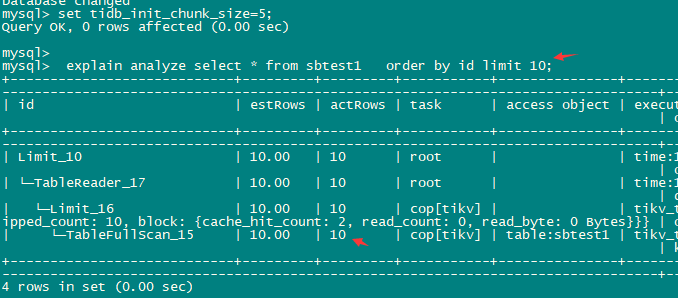
这个后面的loop是多少,我估计还是1吧?如果还是1就是没生效。因为小于32时候就按照requirRows来。
loops是1,那估计就是SQL变化的原因
把语句的limit 部分去了,actRows就是真实的了
追问一个关于limit的问题,假设全表扫描在 where col1 > ‘val’ limit N 这种场景下,虽然最终要N条记录,但是在做cop_task请求的时候并不知道有多少记录符合条件,因此需要把所有cop_task待下发给tikv去执行,为了提高效率这里存在并发,默认是15个,因此我理解应该会执行15个cop_task(因为在算子open的时候就开始异步取数据了),但是看这里只需要cop_task为3个,很是不理解,是在哪方面做了控制呢?

explain.txt (4.5 KB)
我看了下在执行信息中cop_task显示num=3是因为统计的是返回来的resultSubset请求数,并非没在tikv侧执行。当并行度是15的时候确实会在tikv侧做15个cop_task的并行执行,只是在tidb侧迭代resultSubset时候到3的时候,顶层算子完成了取数操作将执行信息merge到语句执行信息中然后关闭后面的取数操作。
因此执行信息中的cop_task的num代表tidb为了获取结果集所需要遍历的cop_task的ResultSubset(Response.Next)个数,但实际在tikv端需要都执行完kv.Request.Concurrency个任务(最大为region)。
疑问已经解决,多谢各位。
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。