【概述】
一条简单的查询语句:
SELECT
*
FROM
xz_device
WHERE
identifier = ‘f00e-df54-0181-f45f’;
数据量为1666条,查询耗时为1.9s。
执行计划为:
id task estRows operator info actRows execution info memory disk
TableReader_7 root 1.6620000000000001 data:Selection_6 1 time:1.874137382s, loops:2, cop_task: {num: 1, max:766.112249ms, proc_keys: 1662, rpc_num: 1, rpc_time: 766.107124ms, copr_cache_hit_ratio: 0.00} 930 Bytes N/A
└─Selection_6 cop[tikv] 1.6620000000000001 eq(xzzh.xz_device.identifier, “f00e-df54-0181-f45f”) 1 time:36ms, loops:6 N/A N/A
└─TableScan_5 cop[tikv] 1662 table:xz_device, keep order:false, stats:pseudo 1662 time:36ms, loops:6 N/A N/A
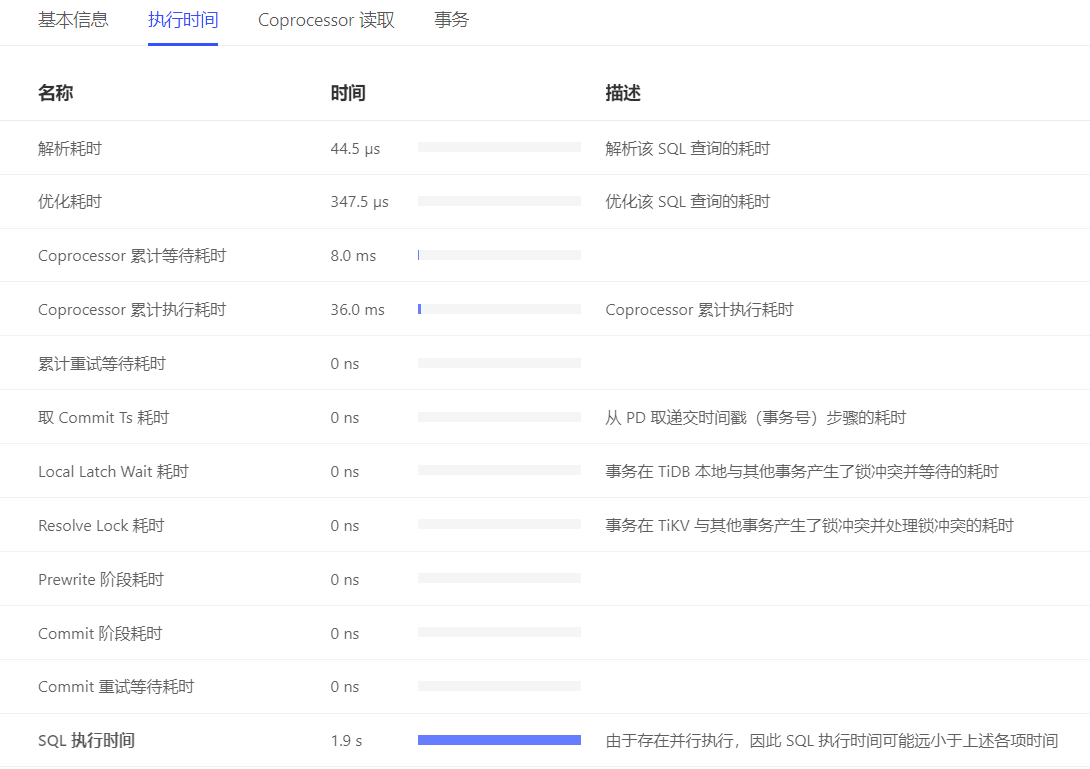
这种如何分析瓶颈或者是时间主要消耗在哪里呢?