虚拟机还是物理机?看 TiDB 层流量特别小,但是 duration 很高,可以看下盘的 fio 怎么样
虚拟机,请问下盘fio指的是什么
执行 随机读测试与顺序写和随机读混合测试后的结果文件如下,txt文件超过了10个G所以就不放上来了
fio_randread_result.json (6.8 KB) fio_randread_write_test.json (7.1 KB)
可以自己判断下 fio 的结果哈,参考 https://github.com/pingcap/tidb-ansible/blob/d6b6390eaaf2bbc6b72d70b6caf414b95e882dc5/roles/machine_benchmark/defaults/main.yml 这里的值,如果差的不是特别多,可以看下 disk 的监控,比如延迟和 load。参考 https://docs.pingcap.com/zh/tidb/v4.0/troubleshoot-high-disk-io#第一类面板

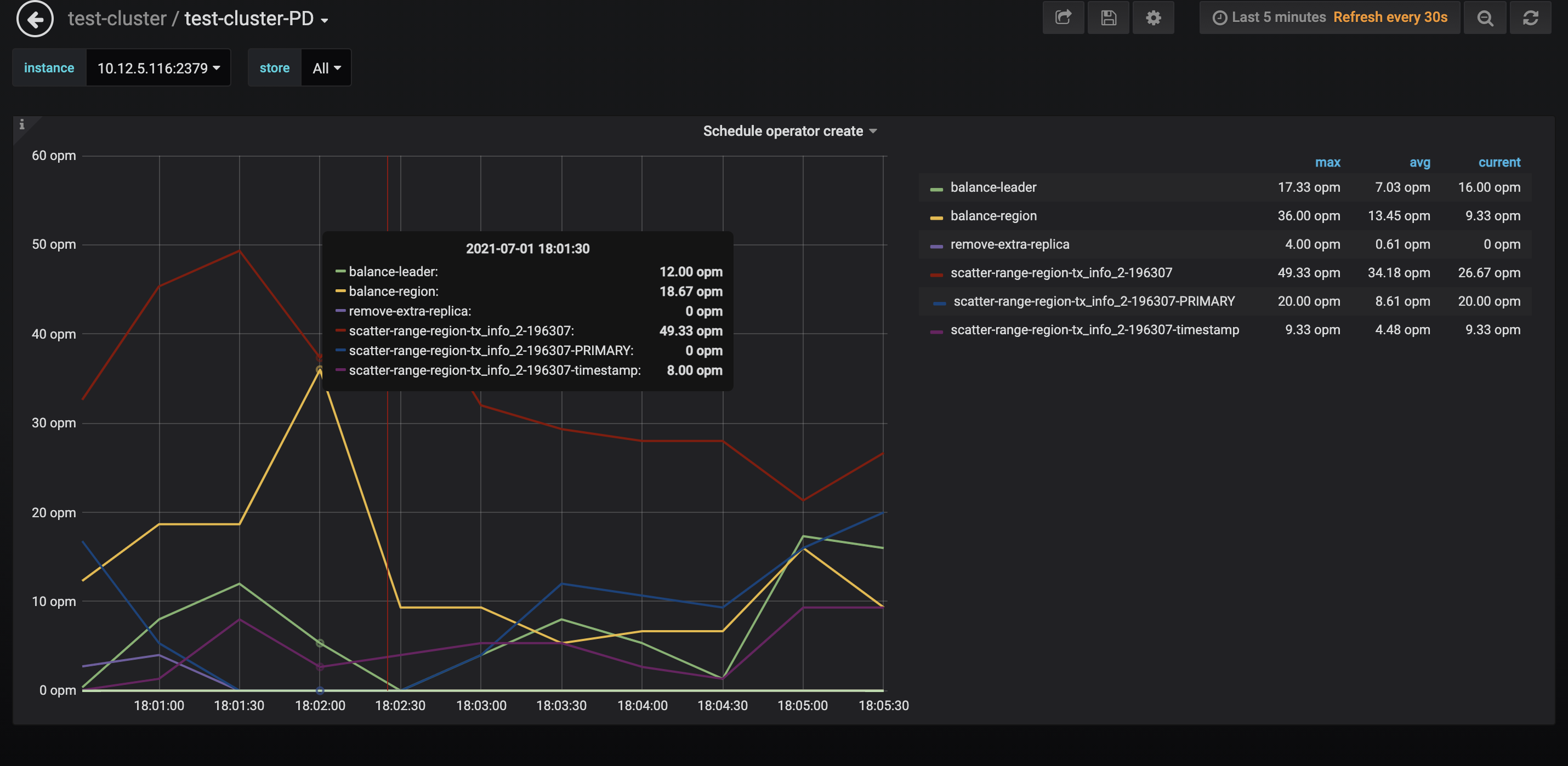
不用,后台自动会进行调度,可以跑着业务看看是否还有 io 高现象。
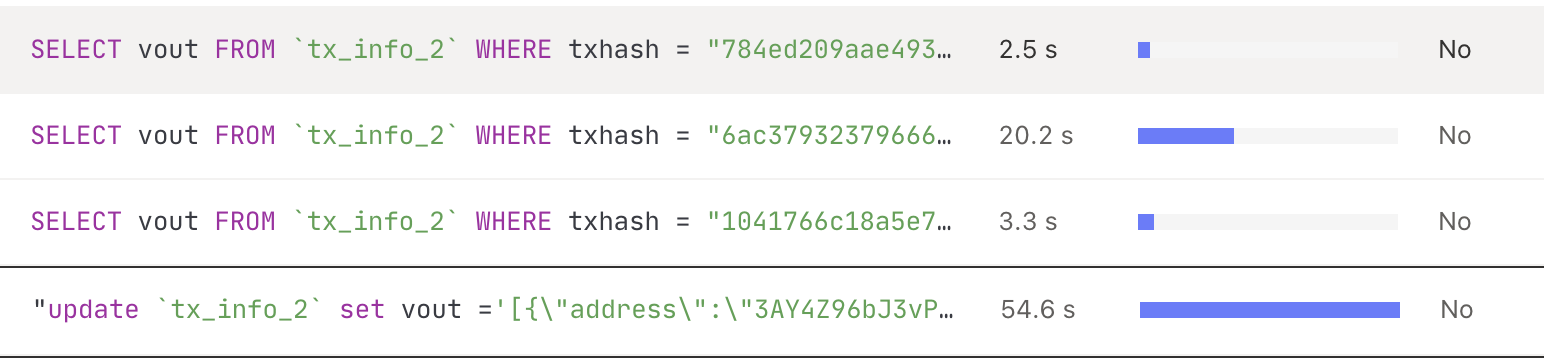
方便的话,拿下 SQL 执行计划或者看下对应语句的慢日志信息。

我们这里有针对读慢的一系列文档,可以参考看下 读性能慢-总纲
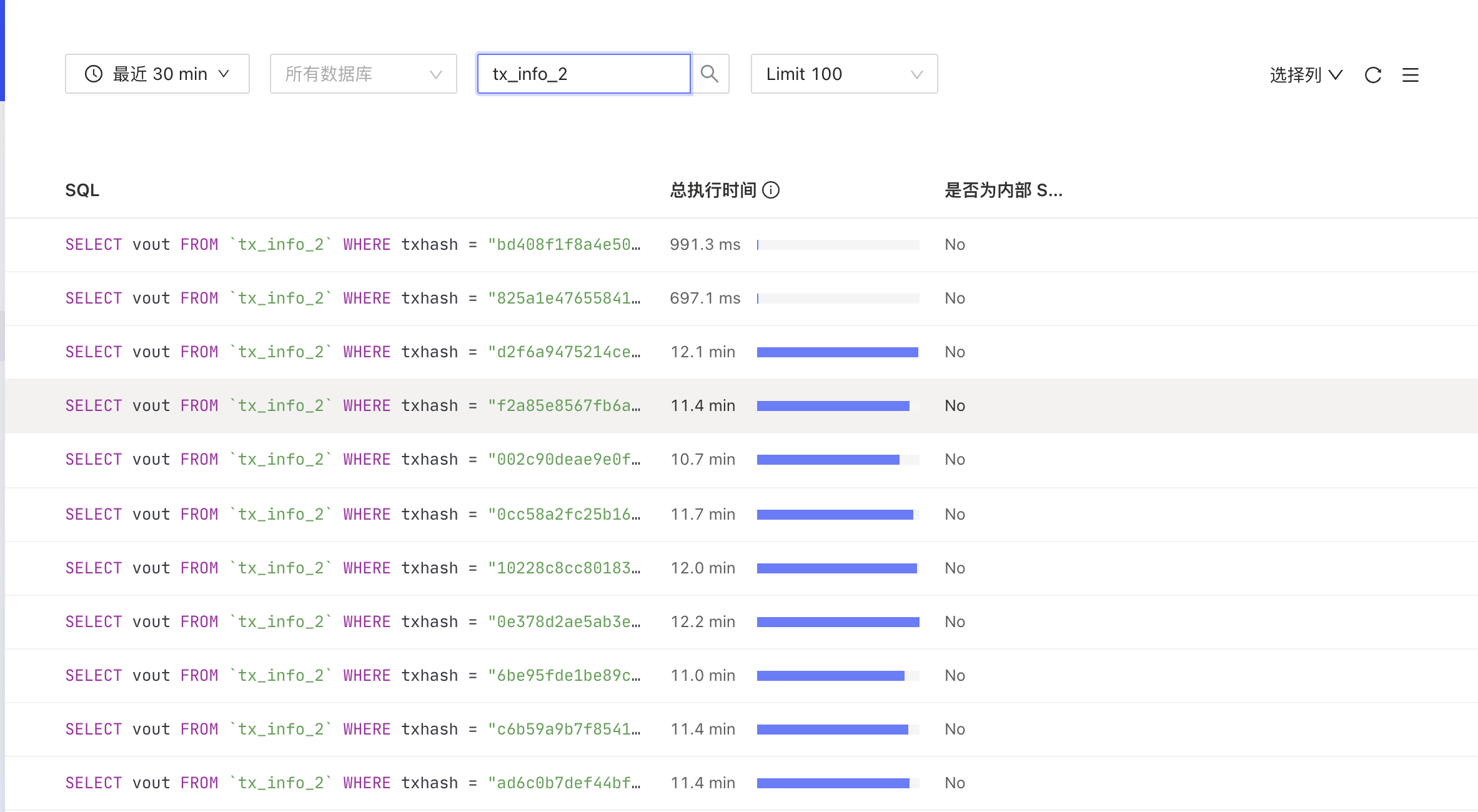
您给的文档我已经看过了,业务没有变更,热点问题也尝试过了,现在问题也定位的比较明确了,对于某张表的select语句执行异常,会出现执行超过10分钟且失败的情况,针对该状况没有搜索到相关资料,我不知道如何进一步分析,能否帮忙分析一下慢日志和执行计划找出原因?
看过给的 SQL,一个点查跑了 10min+,明显是有问题。从慢日志里面查看执行耗时,在 tidb-server 侧是没有问题,看起来时间都在 TiKV 侧。现在不确定 TiKV 侧发生了什么。如果可以,请提供下在执行 SQL 慢期间的 TiKV-detail 面板监控信息。另外,这个环境是测试环境?
该问题现在就有,以下是当前时间段tikv-details
test-cluster-TiKV-Details_2021-07-05T02_55_32.483Z.json.zip (788.1 KB)
该环境应该算是测试环境
1、TiDB 里面的 duration这 已经是将近 10min 级别,是一个 SQL 整体执行响应时间,太高了,但是集群的流量很小,怀疑是系统的负载太高了 2、这个环境的 KV 磁盘性能应该一般,不是官网的建议的 ssd,所以性能有损失。看 KV 耗时也是1-2min+,多出来的时间怀疑是数据返回过程中太慢,可能网络数据返回性能不佳。 3、每个节点的 region 数太多了,可以考虑开下静默 region,系统的负载会降下来 4、考虑调大 region merge 参数,集群里有大量的小 region,调大 merge 参数合并下小 merge ,降低下系统负载 5、KV 的磁盘大小最好都是一样,否则会频繁进行 region 调度(建议)。另外上次看 IO 打满是因为 compaction ,可以注意下看下每次慢的时候是不是同一个节点机器以及是否在进行 compaction,如果符合的话,推测是磁盘性能不足(已知 TiKV 为机械硬盘)
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。