无法挽回了吗?数据缺失?还有什么方法么
你按照下面的方法进行验证哈:
1.找出那两个offLine的store的reigon,用上面你回答的方法
region --jq=’.regions[] | {id: .id, peers: [.peers[]] | map(select(.is_learner != true ))} | {id: .id, peers: [.peers[].store_id] | select(. | contains([70002,70059]) and length==2)}’
{“id”:3673943,“start_key”:“748000000000002CFF0D00000000000000F8”,“end_key”:“748000000000002CFF1000000000000000F8”,“epoch”:{“conf_ver”:23,“version”:4083},“peers”:[{“id”:7535196,“store_id”:7332002},{“id”:8321873,“store_id”:7982622},{“id”:9901614,“store_id”:9235861}],“leader”:{“id”:8321873,“store_id”:7982622},“written_bytes”:0,“read_bytes”:0,“written_keys”:0,“read_keys”:0,“approximate_size”:1,“approximate_keys”:0}
{“id”:3663917,“start_key”:“7480000000000010FF8700000000000000F8”,“end_key”:“7480000000000010FF8A00000000000000F8”,“epoch”:{“conf_ver”:23,“version”:1623},“peers”:[{“id”:7431121,“store_id”:7332002},{“id”:8073449,“store_id”:7982622},{“id”:9437647,“store_id”:9235861}],“leader”:{“id”:9437647,“store_id”:9235861},“written_bytes”:0,“read_bytes”:0,“written_keys”:0,“read_keys”:0,“approximate_size”:1,“approximate_keys”:0}
2.比如这种,选择regionID:3673943
执行 curl http://tidbIP:statusport/regions/3673943
注意是 statusPort,不是4000,是10080
- 会显示个
“frames”: [
{
“db_name”: “db”,
“table_name”: “table”,
“table_id”: 467,
“is_record”: true,
“record_id”: 19894851
}
4.连接数据库执行
select count(1) from db.table;
估计这里就报错了。
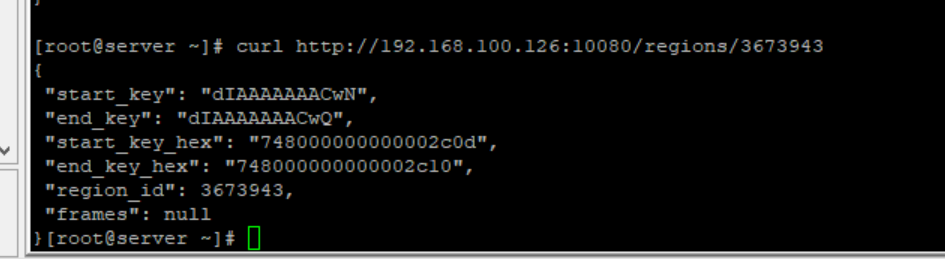
试了七八个 regionid 提示这个 frames 都是 null
再换个region,多试试。
估计因为数据丢失,frames都解析不出来。
或者你直接对数据库表进行 select count(1) 计算,也能验出来,但是要多试几次。
搜tidb日志,估计有报错。
你这数据坏了,有点多,补救补上来。
测试环境,重新安装吧。
找到一个有frame的表,执行count(1) 一直执行了…我明天看看
怎么避免这种问题呢?我 按照标准 scale-in 为啥一直就是这个就是 pending offline 好几天了.
就明明屁大的数据
虽说是测试环境,然而测试这边已经有很多测试的数据在里面
现在重做贼麻烦
非常抱歉,带来的不便,请问目前测试如何了,多谢。
哎,上面反馈说是数据已经损坏了.也没有办法恢复.我觉得都是按照指定操作执行.怎么会这样呢
现在线上有一个Scale In 也是 执行好久了.都不敢动了
症状一样, display没有这节点信息,dashboard一直都有这个节点

都无语了. 现在线上系统按照官方文档执行的缩容,
也是卡在这,也不知道能怎么操作
会不会丢失数据,听天由命嘛…
个人觉得安全下线要这样吧:
- 添加 evict leader 调度器,迁移出所有 leader
- 等待要下线的 store,leader 数为 0,集群没有异常的 region peer
- 执行下线操作, 等待 store 上的 region peer 被调度出去(要求剩余store数量不低于副本设置)
- 让 pd 将其设置为 tombstone.
5.0的下线,教程确实有大问题,我都被坑两次了,我是真尼玛服,官网让强制下线,然后被提出拓扑图了,pd中还有残留,还不让置为tombstone,666
正常安全下线,还是要交给系统来完成吧:
1.开始前确认集群正常,集群中没有异常 peer,例如 down、pending 等
2.保证下线后剩余的 store 数量满足数据副本数的要求
3.在 pd 执行 store delete storeId 命令开始下线
4.静静的等待下线 store 上的 region 数降为 0,然后 pd 将其设置为 stone。(要通过 granfana 面板上数据确认 store 上 region peer 为 0,pd 才会将其设置为 stone)
有没有异常 peer,通过 granfana pd 的面板关于 region peer d的统计信息查看。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。