说了啊.执行结果如图
不知道你执行的什么,你最好贴下最新的日志。
curl -X DELETE http://192.168.100.94:2379/pd/api/v1/store/70059?force=1
这个命令执行后,是把 store 设置为 PhysicallyDestroyed,有下面两个结果:
在 dashboard 仍然可以看得到它。
以及
允许重新把 192.168.100.187:20160 地址的 store 加入集群。
加入之后,你可以看到 192.168.100.187:20160 地址的 store id 不再是 70059。
然后你把这个 192.168.100.187:20160 store 启动。
它就不是down 了。
如果启动不了,那就再看 tikv 报了什么错。
for _, store := range stores {
// the store has already been tombstone
if store.IsTombstone() {
continue
}
if store.IsUp() {
if !store.IsLowSpace(c.opt.GetLowSpaceRatio()) {
upStoreCount++
}
continue
}
offlineStore := store.GetMeta()
// If the store is empty, it can be buried.
regionCount := c.core.GetStoreRegionCount(offlineStore.GetId())
if regionCount == 0 {
if err := c.BuryStore(offlineStore.GetId(), false); err != nil {
log.Error("bury store failed",
zap.Stringer("store", offlineStore),
errs.ZapError(err))
}
} else {
offlineStores = append(offlineStores, offlineStore)
}
}
在dashboard查一下 pd 日志:
log.Error("bury store failed",
zap.Stringer("store", offlineStore),
errs.ZapError(err))
offline 的 region count = 0,而且不是 tombstone,只能是这里报错。
上面我也说了.没查到 bury 这个相关的
你说的这个
curl -X DELETE http://192.168.100.94:2379/pd/api/v1/store/70059?force=1
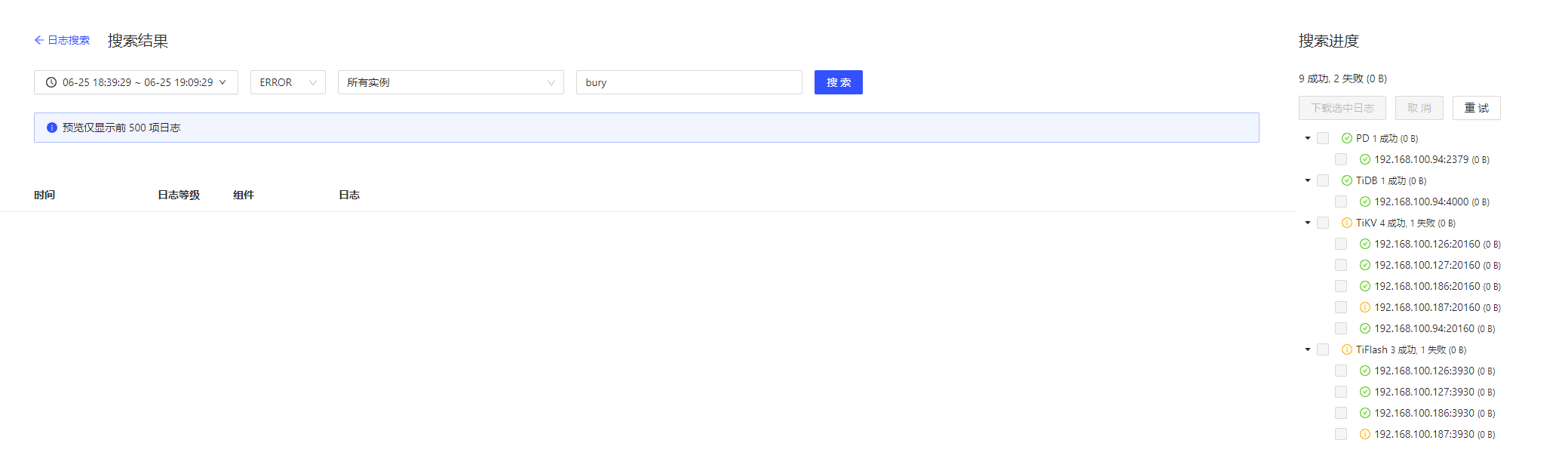
我已经把执行结果截图了
我再执行一遍你看看对不对

执行结果就是跟没执行一样, store 70059 依然还是这个
“允许重新把 192.168.100.187:20160 地址的 store 加入集群。”
这个就是现在根本就开不起来了,我重新这个服务器节点安装,扩容tikv
提示
[2021/06/17 16:56:04.574 +08:00] [FATAL] [server.rs:698] [“failed to start node: Grpc(RpcFailure(RpcStatus { status: 2-UNKNOWN, details: Some(“duplicated store address: id:9172667 address:\“192.168.100.187:20160\” version:\“5.0.1\” status_address:\“192.168.100.187:20180\” git_hash:\“e26389a278116b2f61addfa9f15ca25ecf38bc80\” start_timestamp:1623920159 deploy_path:\”/home/tidb-deploy/tikv-20160/bin\” , already registered by id:70059 address:\“192.168.100.187:20160\” state:Offline version:\“5.0.1\” status_address:\“192.168.100.187:20180\” git_hash:\“e26389a278116b2f61addfa9f15ca25ecf38bc80\” start_timestamp:1623136089 deploy_path:“/home/tidb-deploy/tikv-20160/bin” last_heartbeat:1623751882105124348 “) }))”]

-
执行上面的命令后,是把 store 设置为 PhysicallyDestroyed, store 应该是 offline的状态,但是store 存在
-
再执行扩容,应该可以添加上去。
这个提示日志日期是 2021/06/17啊,今天是6.25号
我最后一个截图,你i看下,刚刚新鲜出炉的执行
我再次扩容看看,稍等

这个结果是符合预期的:
1.新上线的store是相同的地址,新分配的storeID
2.旧 store 应该是等待 pd 设置它为 tombstone。
可以通过 pd 看看这两个 store 的情况。


那就是等他清除? 另外,我另外一个节点也是这个问题
就是 缩容,一直停留在 pending offline
已经两天了.我现在也不敢再搞 --force了.如上 截图所示 186
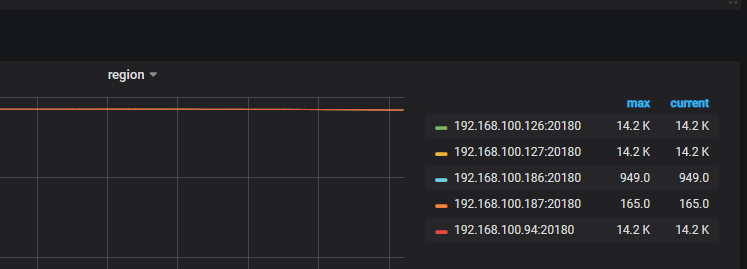
region一直停留在 949 ,愁得不行了.
上一次是,等了几天没动静,忍不住做了 --force
现在这次也已经两天了.我怕数据搞坏了…不敢动,
但她就是i一直这个 pending offline …
总共才 50G的数据

这里显示region 949,然后 pd 没有把它设置为 tombstone也正常。
问题在于为什么 pd 查询 store 个数显示为 0,grafana显示为 949。这是关键。
你把 pd 集群重启一下,试试能否解决问题,感觉是 region cache 问题哦
是的,我就是没懂这个,前次也是这样,一直无法下线节点
我能跟之前一样执行 curl -X DELETE http://192.168.100.94:2379/pd/api/v1/store/70002?force=1 吗
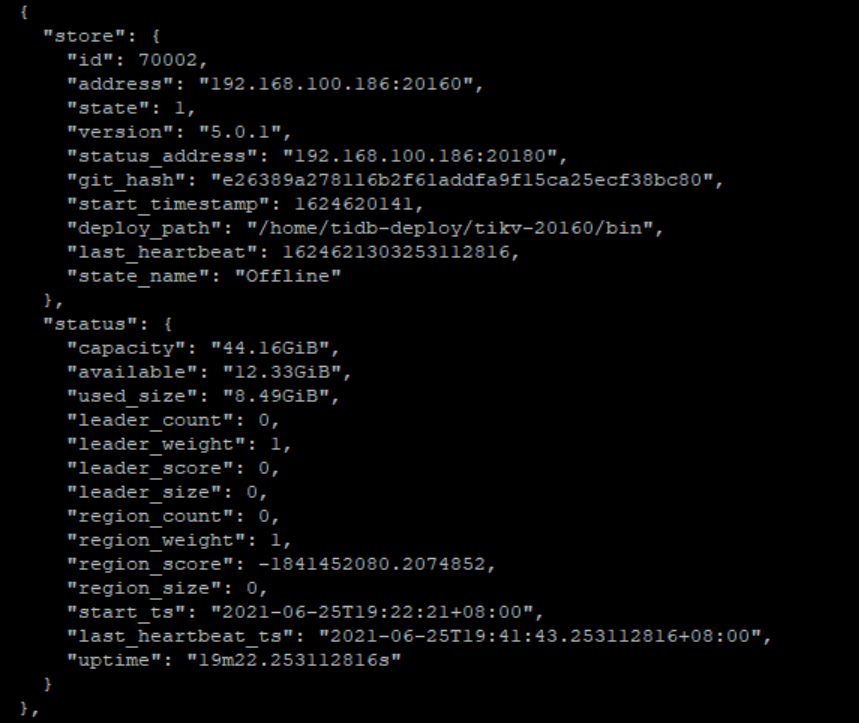
就这个状态.我也搞不懂了 这里面显示都是 0 ,但是 监控那边都是 949
我整个集群偷偷重启了好几趟了 没变化
因为regioncache有持久化,所以重启好像确实解决不了问题。
我推测,你现在数据已经有问题了。有的region原来恰好在你这两个 offLine 的 store 上面,你把它们下线了。然后这些region都是异常的。
因为这些region不在其他store上面,也就没有 store 作为 region 的 leader 上报 region 信息对它进行更新,导致 regioncache 内容一直不变,统计了 region 数量一直是949.
你目前的数据就是异常的啊。
哎,我缩容是一个个操作的
,187是等了好久,最后看到她都是 0 ,tiup display 显示也没这个节点了 ,仅仅是没从 面板消失 我才继续操作 186的缩容