TiDB 版本: v4.0.9
问题描述: 线上tidb 集群由于磁盘空间吃紧,扩容了一个tikv 节点。但是扩容开始后,集群整体响应耗时增加明显
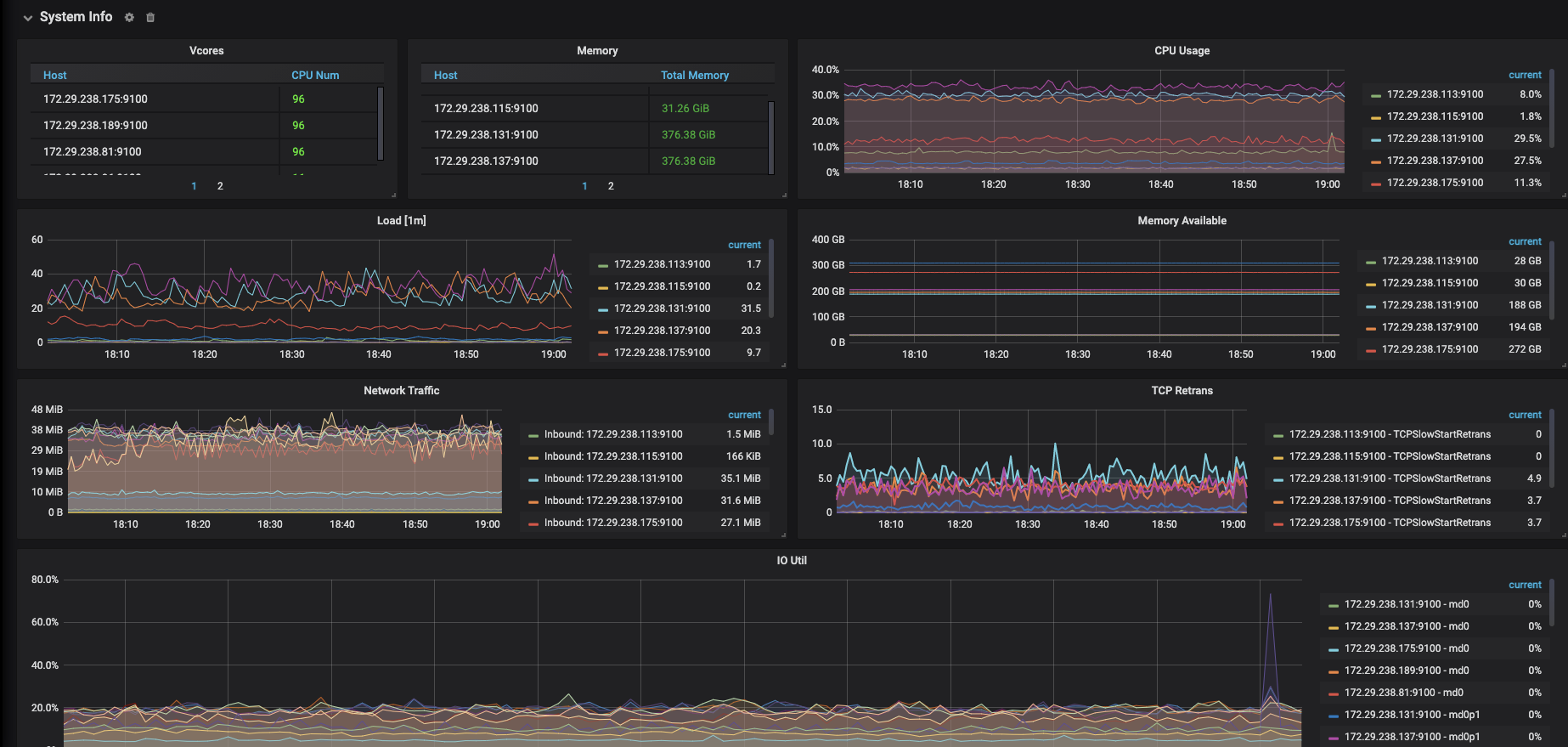
部分信息如下图所示
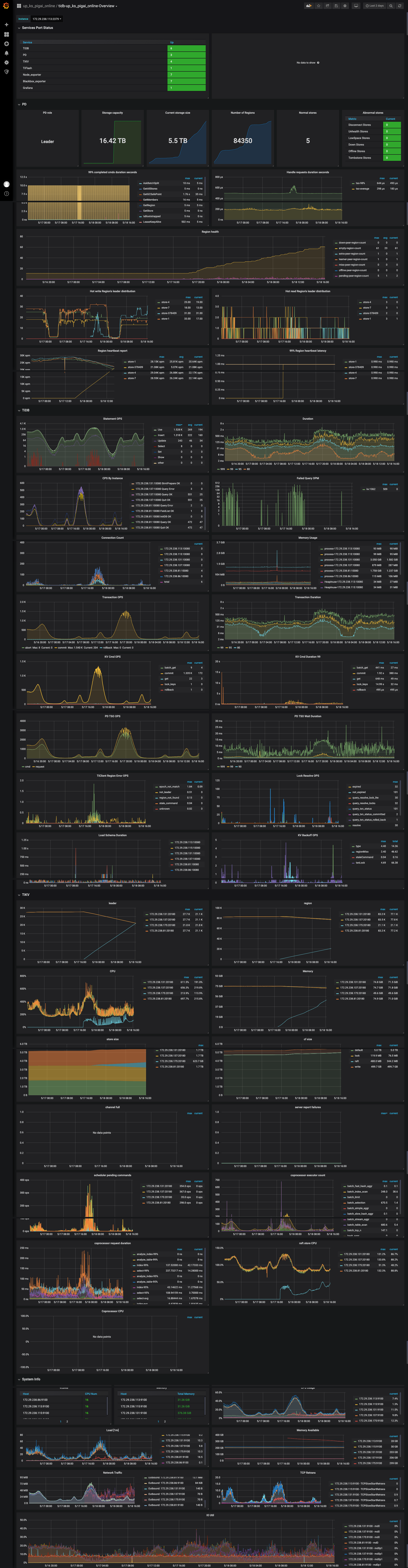
overview 整体截屏如下:
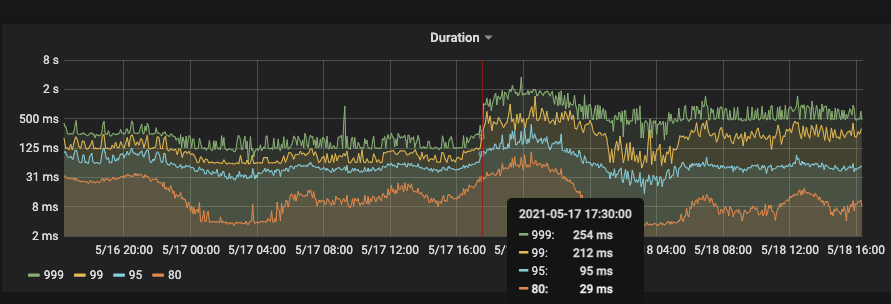
根据慢查询信息,发现耗时主要发生在prewrite 阶段(主要是insert 操作居多)

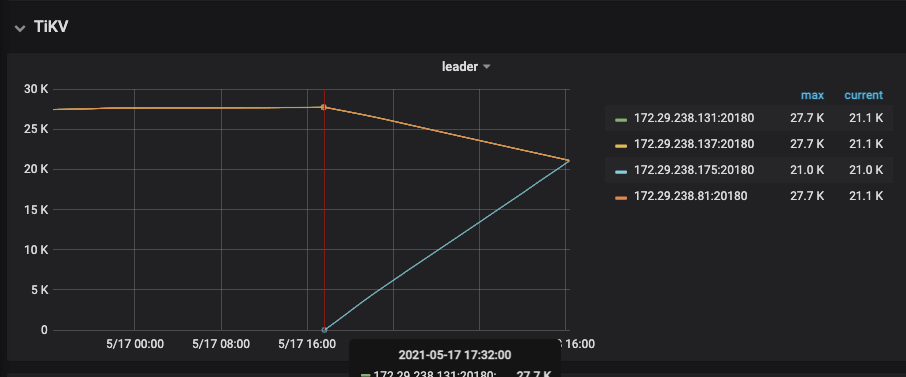
trouble shooting 相关监控:

请问下一步该如何处理 ??
TiDB 版本: v4.0.9
问题描述: 线上tidb 集群由于磁盘空间吃紧,扩容了一个tikv 节点。但是扩容开始后,集群整体响应耗时增加明显
部分信息如下图所示
overview 整体截屏如下:
根据慢查询信息,发现耗时主要发生在prewrite 阶段(主要是insert 操作居多)
trouble shooting 相关监控:
集群写入变慢可以参考下『写入慢流程排查』系列文档:
建议重点关注下因 PD 调度导致的写入慢的现象:
这是我之前扩缩容过程中遇到的问题,楼主可以参考下哈
![]()
![]()
![]()
按照文档中描述,从tidb-server 开始对照每一个流程,详细信息如下:
===>tidb-server 部分
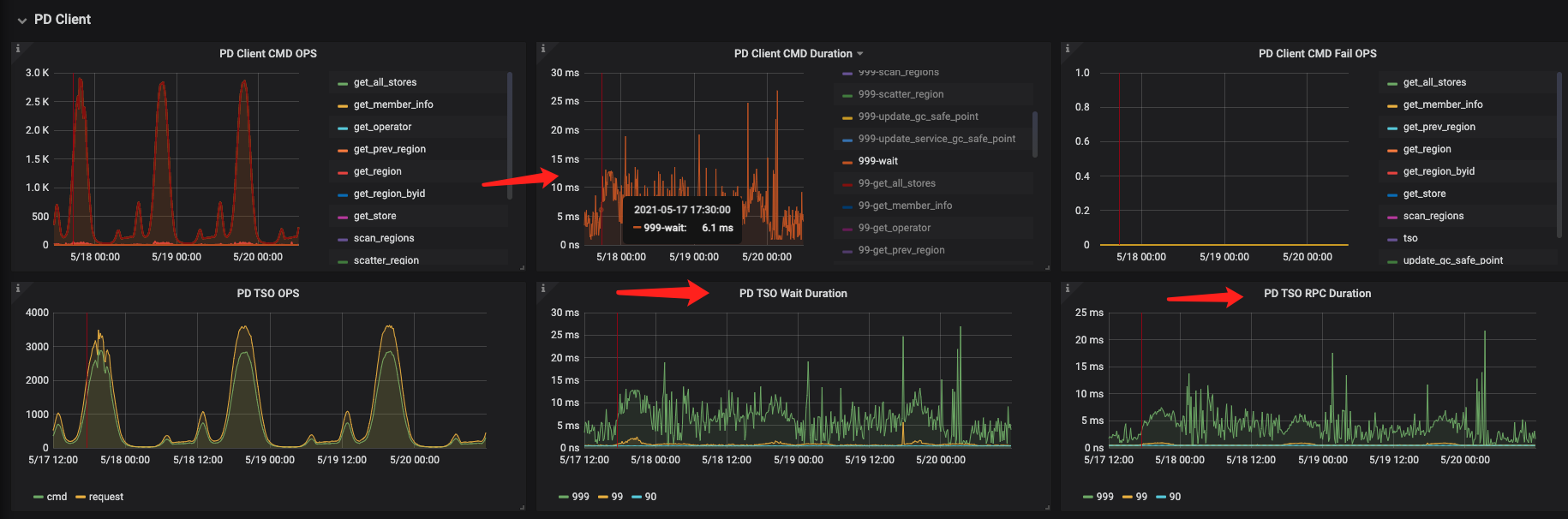
1.pd-client & executor 部分监控
2.KV REQUEST 部分耗时增加
===> tikv-server 部分
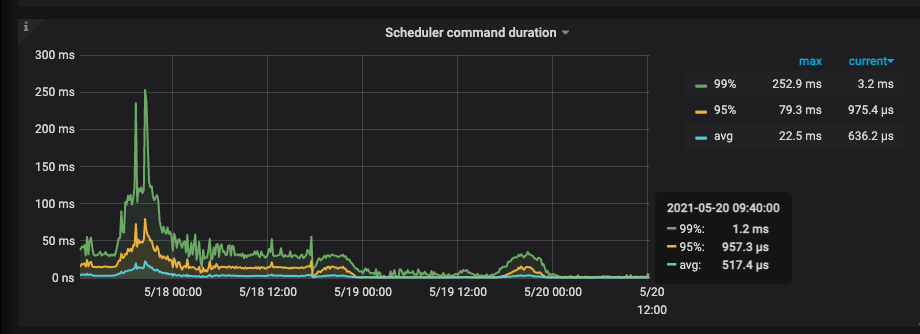
1.storage 部分: async write duration 耗时增加明显
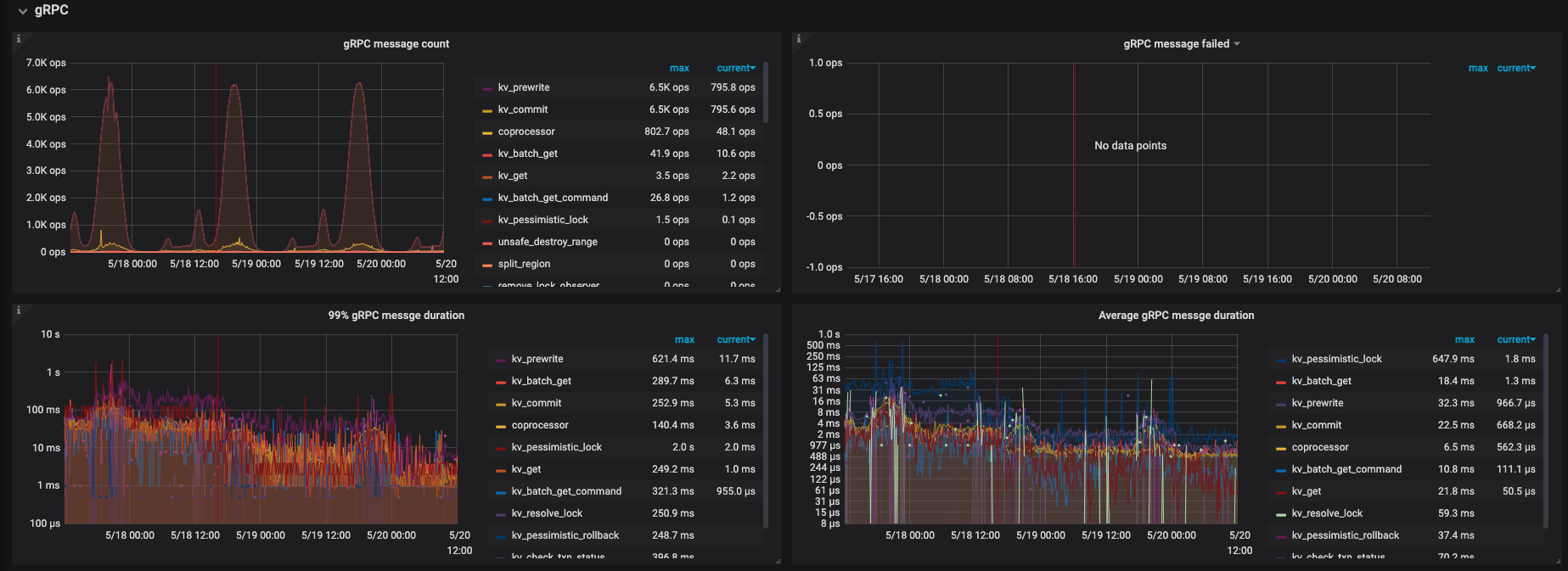
2.GRPC 部分: 耗时略有增加(包括了sheduler 部分的prewrite + commit 耗时)
{gRPC duration 的时间等于 gRPC 线程池将这个请求分发给 Scheduler 模块以及这个命令在 Scheduler 内部执行时间的总和}
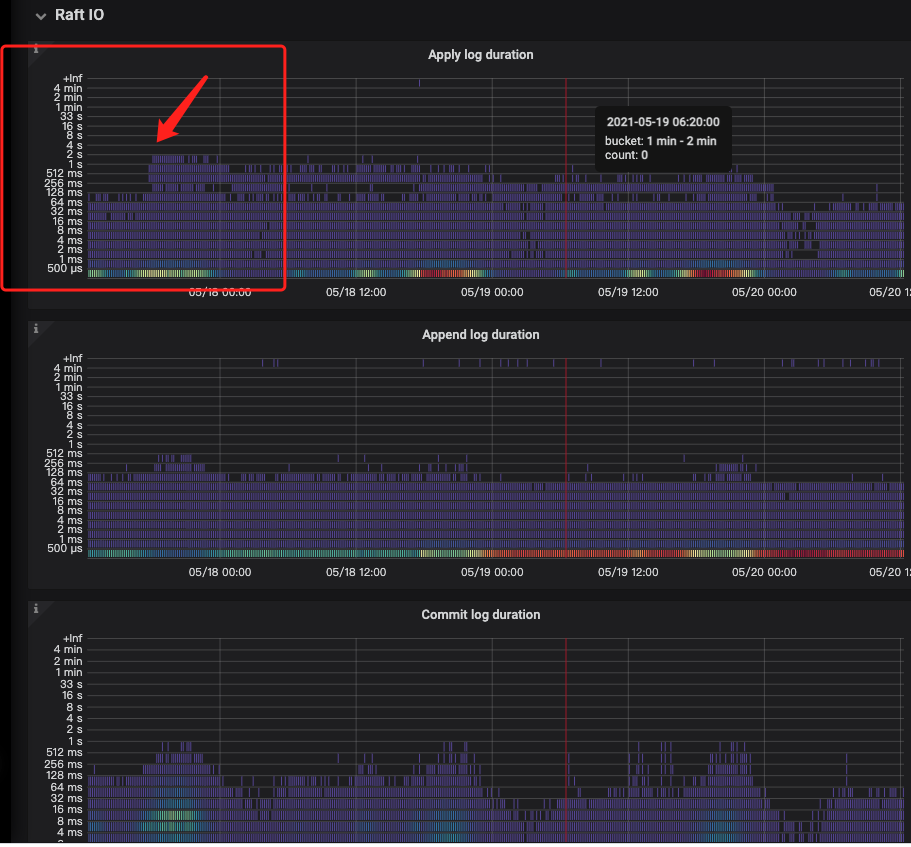
3.raft io 部分:apply log 耗时增加明显
4.rockdb 部分
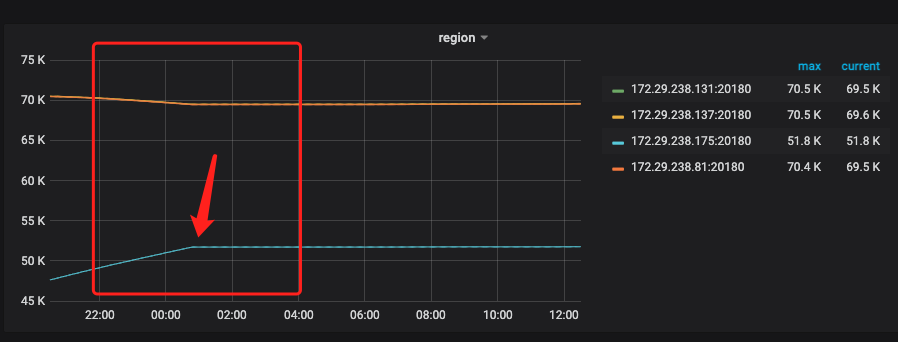
从扩容开始所进行的操作:
5.17-17:30 左右开始扩容 – 耗时增加
5.18-17:30 左右进行了store-pool-size 调整,reload 了tikv ,耗时有所下降(我估计不改参数直接reload 也会有效果)
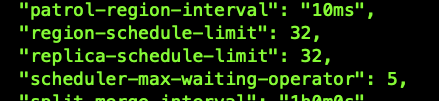
5.18-18:00 调整了pd 调度的limit 参数(效果不明显) ,调整后参数如下图
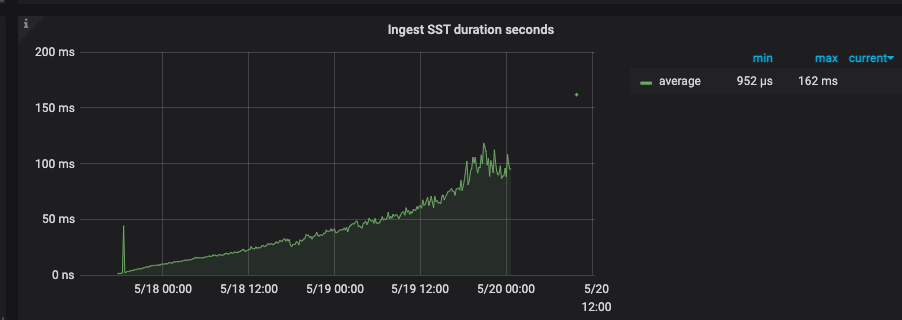
所以最后我的分析是由于均衡数据需要写入snapshot 数据(调度 Region 后,生成的 Snapshot 会使用 Ingest SST 的方式快速的将数据写入到 RocksDB 中)
影响了rocksdb 的写入(见最后rocksdb 部分监控) 进而导致了apply log 的耗时增加 ???
针对这种情况,应该如何调整才是最有效的?
1.继续调小pd 调度的参数 ??(扩容的一个tikv 节点,1.5T的数据均衡了3天)
2.修改tikv 的相关参数 ??
请给出跟针对性的建议,多谢。
![]()
![]() ,从上面的分析结果可以看到,扩容后的 Region Balance 对集群的性能影响比较明显。
,从上面的分析结果可以看到,扩容后的 Region Balance 对集群的性能影响比较明显。
在 Region Balance 的过程中,除了上面提到的 ingest sst 可能带来的写入问题外,可以同时关注下,TiKV-Details → Snapshot 面板下的监控项,调度时会基于已有 Region 生成 snapshot ,snapshot 生成同样会对集群造成压力,相关的参数见:
https://docs.pingcap.com/zh/tidb/v4.0/tikv-configuration-file#snap-max-write-bytes-per-sec
PD 在 3.0 版本引入 store-limit 特性,旨在能够更加细粒度地控制调度的速度,针对不同调度场景进行调优。具体介绍见下面的链接。如果后续在进行扩容操作时,可以考虑调低该参数,限制 operator 的消费速度。在业务低峰时可以调大,加速消费,业务高峰调小限制消费:
https://docs.pingcap.com/zh/tidb/stable/configure-store-limit#store-limit
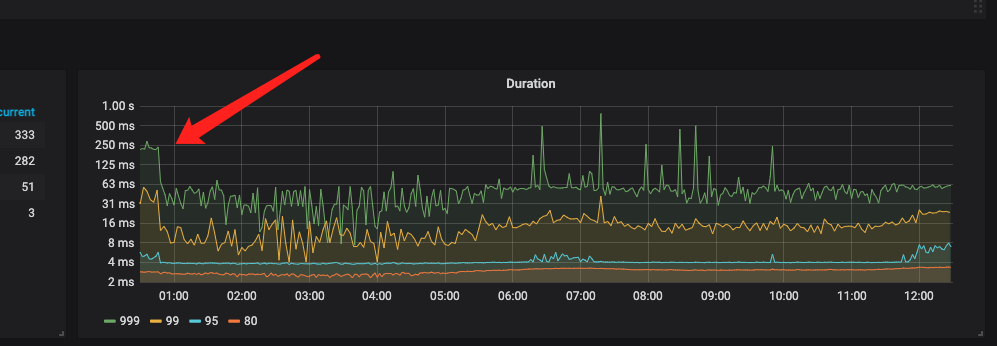
我调整了扩容的新节点的store-limit 的值,现在leader 均衡完成了,均衡region 的过程中响应耗时还是挺长的。
调整后响应耗时图如下:
请问还有其他优化的方法么 ?
我们的硬件资源是很充足的,在动态扩容中这个状态感觉有点尴尬。其他tidb 用户是否也是这种情况 ?
可以看下 Overview -> System Info 相关的监控
先梳理下问题:
1、当前的问题仍然是 『扩容 TiKV 节点后,TiDB Duration 明显升高』吗?
2、楼上提到的调整了目标 TiKV 节点的 store-limit 后,仍然没有缓解,TiDB Duration 仍然持续在较高水平吗?
1.只有在扩容时会增加明显。已经验证两次了
2.上面回复中调整过store-limit 以及region-limit 的值到比较小的数值,响应耗时缓解不适太明显,但是并未恢复到之前正常的水平
请问我这个是个例么?还是说其他用户也有这种状态 ?
如果是个例,我可以再找个其他集群验证下。
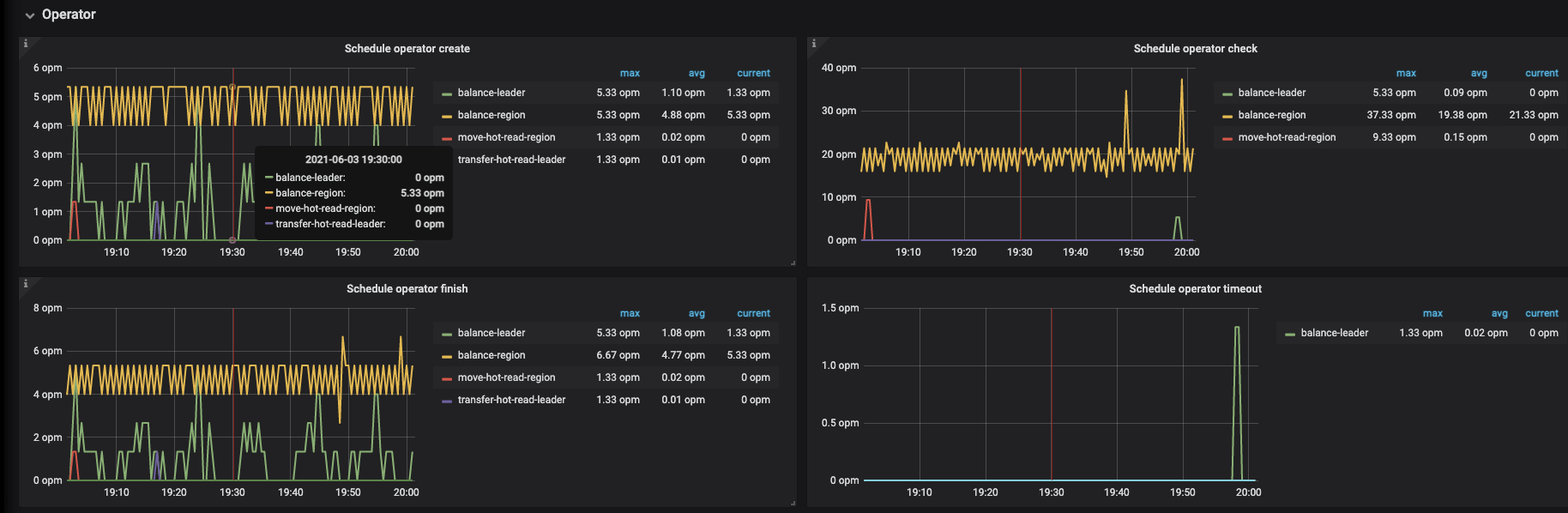
在扩容 TiKV 后,需要进行 leader transfter ,region balance 的操作。其中,可以通过某些配置来缓解对业务的影响,但是无法完全避免。毕竟是在已有业务负载的基础上,『额外增加』 了一部分操作。
leader transfter:后台会进行 backoff 重试,理论上不需要处理。但是 backoff 操作在一定程度上会拉长响应时间。这块的内容可以在论坛搜索『region cache』以及『backoff』关键字来找到。可以通过调整 leader-scheduler-limit 来适当降低调度的速度。
region balance:region 在 balance 时,leader 生成 snapshot,然后传送到目标 TiKV,然后以 ingest sst 的形式写入。这部分可以对两块进行限速:
综上,如果当前集群扩容了 TiKV 节点,建议通过上面的方式来降低影响。在业务高峰,尽可能的调低参数,在业务低峰调高参数,尽快完成调度。
感谢回复。下次我再试试这些操作
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。