为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
生产环境,版本5.7.25-TiDB-v6.1.0
【概述】 场景 + 问题概述
背景说明:该表总行数有约500亿行所有,按天分区,每个分区1亿多行。
分区表结构
主键索引: PRIMARY KEY ( dt , doc_id ) /*T![clustered_index] NONCLUSTERED */,
PRIMARY KEY ( dt , doc_id ) /*T![clustered_index] NONCLUSTERED */,
KEY updatetime ( updatetime ),
KEY newdate ( newdate )
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T![placement] PLACEMENT POLICY= storeonssd */
PARTITION BY RANGE (UNIX_TIMESTAMP( dt ))
(PARTITION p20210601 VALUES LESS THAN (1622563200),
…)
【背景】 做过哪些操作
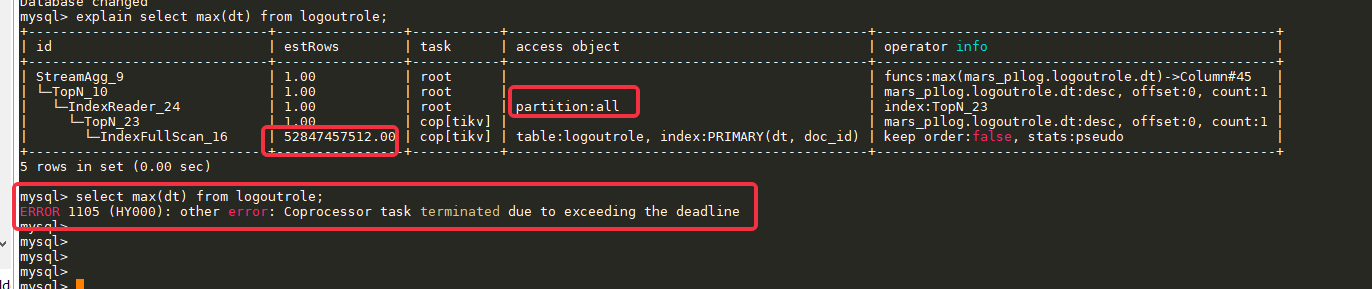
对该表执行max查询,其中dt为时间字段,是主键索引的左边第一个字段:
select max(dt) from logoutrole;
【现象】 业务和数据库现象
【问题】 当前遇到的问题
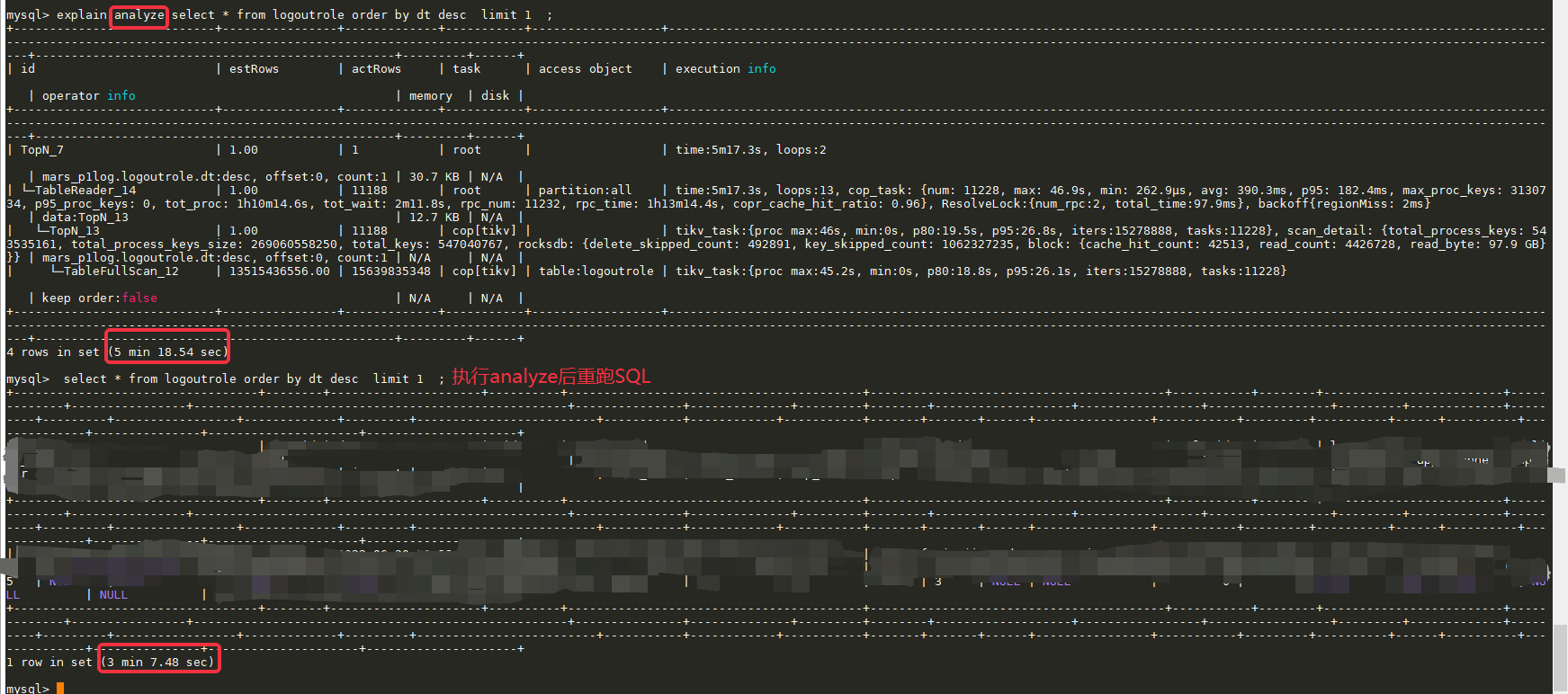
1.执行查询,报错 或长时间无返回,报错时信息如下:
mysql> select max(dt) from logoutrole;
ERROR 1105 (HY000): other error: Coprocessor task terminated due to exceeding the deadline
mysql>
2.执行计划
【业务影响】
无法正确获取内容
【TiDB 版本】
v6.1.0
【应用软件及版本】
5.7.25-TiDB-v6.1.0