Bug 反馈清晰准确地描述您发现的问题,提供任何可能复现问题的步骤有助于研发同学及时处理问题
【 Bug 的影响】
【可能的问题复现步骤】
分区表dt,doc_id) /*T![clustered_index] NONCLUSTERED */,dt,doc_id) /*T![clustered_index] NONCLUSTERED */,updatetime (updatetime),newdate (newdate)storeonssd */dt))p20210601 VALUES LESS THAN (1622563200),
explain
执行,长时间未返回
使用完整的主键索引order by ,也长时间未出结果
【看到的非预期行为】
【期望看到的行为】
【相关组件及具体版本】
【其他背景信息或者截图】如集群拓扑,系统和内核版本,应用 app 信息等;如果问题跟 SQL 有关,请提供 SQL 语句和相关表的 Schema 信息;如果节点日志存在关键报错,请提供相关节点的日志内容或文件;如果一些业务敏感信息不便提供,请留下联系方式,我们与您私下沟通。
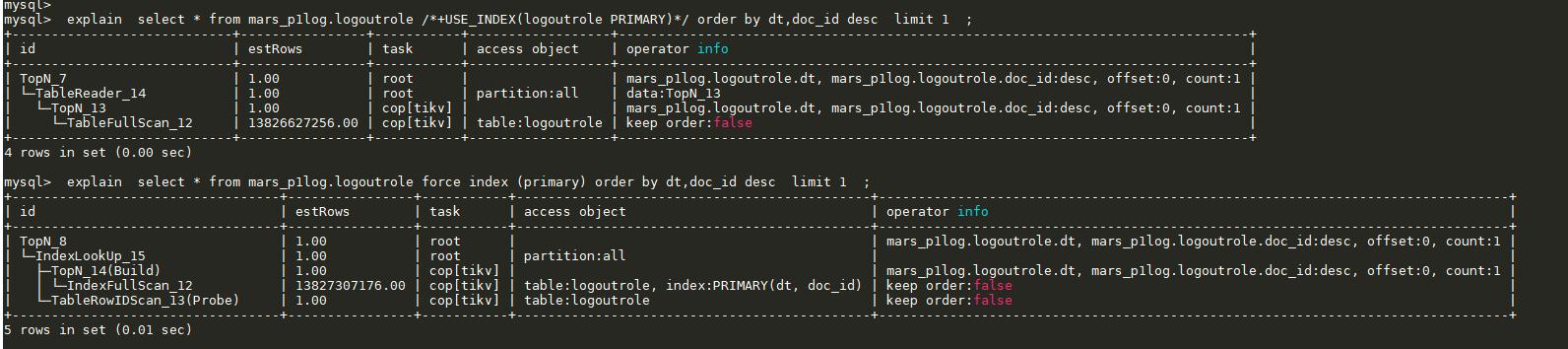
/*+USE_INDEX(logoutrole PRIMARY)*/是否有效?mysql客户端要加--comments
我看第二个force index生效了,也还是很慢吗
jiyf
2022 年6 月 29 日 11:29
8
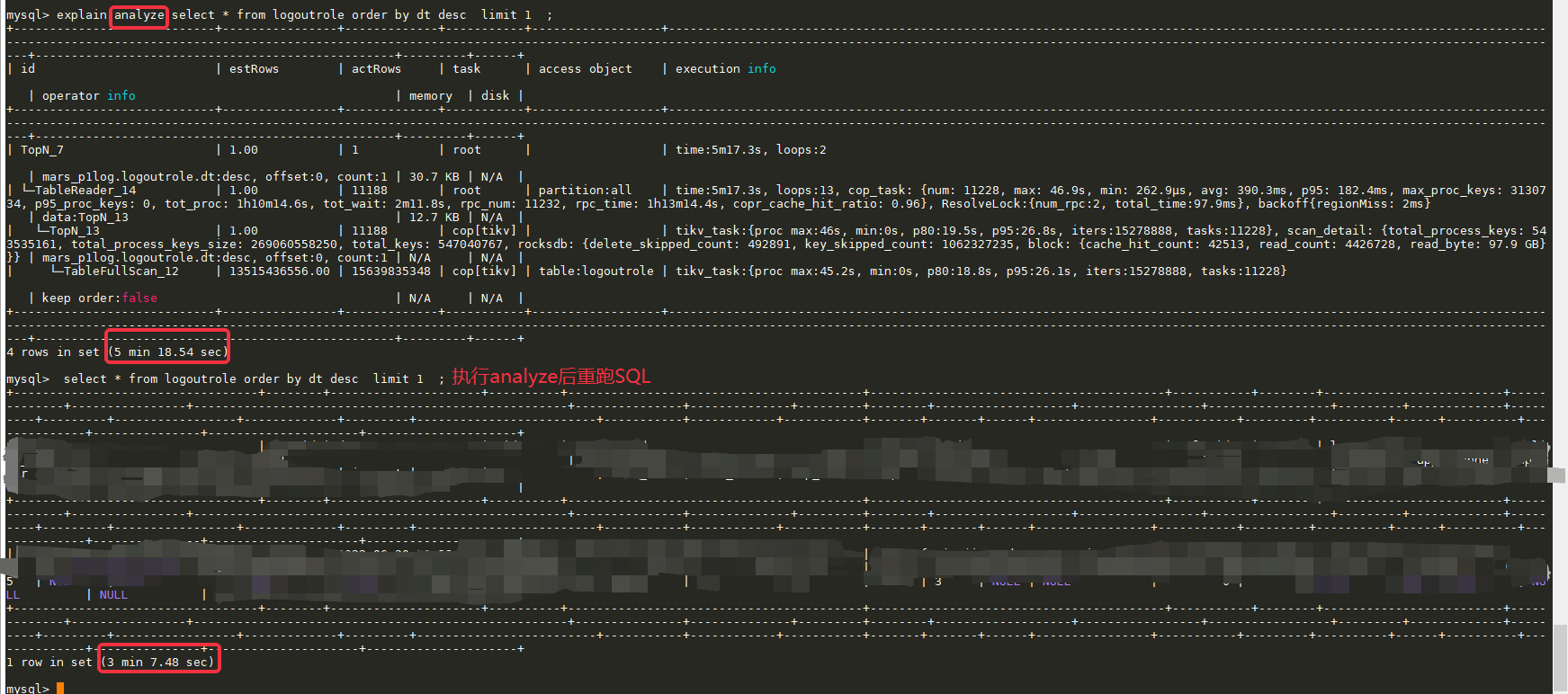
看着更像是 TiDB 对于分区表下 order by idx_col limit m, n 执行计划太差的问题。
当前的执行计划,是对每个分区计算出 topN 后,把各个分区的数据汇总计算 topN,得到的结果应当是正确的,但是没有用好索引的本身有序性。
因为当前排序的列是主键列 dt,理想的执行计划应该是按照这样的逻辑执行:
分区键是 dt,那么各个分区之间,基于 dt 有序,分区 p1 内的 dt 值都小于分区 p2 的 dt 值
分区内 dt 是索引(主键索引),那么按照 dt 的索引,分区内 dt 是有序的
基于以上的有序性,按照顺序扫描分区表,对于分区表内部,使用 dt 的索引就可以得到 order by dt limit m, n 的结果了,也就是跟使用非分区表类似的效率,使用 limit 算子就可以了。
对于当前的结果,因为不清楚这里 dt 的类型定义,有没有这种可能:
对所有分区表的结果执行 topN
对于分区表内部执行 limit
所以 TiDB 对于 range 分区,这种情况,生成的执行计划不够优秀感觉有很大关系。
基于当前的执行计划,耗时较久就要看下机器性能以及扫表相关相关的参数了,毕竟表数据量大,如果磁盘性能不佳,扫描并发参数较低,130亿的数据,耗时较久很有可能的。
1 个赞
h5n1
2022 年6 月 30 日 01:15
10
set session tidb_partition_prune_mode=‘dynamic’ 这样跑下试试,虽然你的SQL涉及不到裁剪的问题,但以前确实有因为不能动态裁剪导致用不了索引
这个集群一直都是dynamic的了,
mysql> show variables like ‘tidb_partition_prune_mode’ ;
mysql>
感谢回复。updatetime (updatetime), 执行计划也需要进行 TableFullScan_12:
jiyf
2022 年6 月 30 日 03:16
13
这里执行计划,那个 TopN_13 算子如果改为带有 keep order true 的 limit 算子就好了:
limit 走 updatetime 索引 keep order true,扫出来第一个(满足limit m, n)
TopN_7 对各个分区子表(各个分区)返回的 limit 结果,进行一个 topN 计算返回数据
那这个问题就稍微麻烦,如果有这种 order by limit m, n 查询的强需求,还真没有好的查询方法。
或者试着加范围查询,例如 where updatetime > “xx” and updatetime < “xxx” order by updatetime limit m, n,通过指定索引列范围,让它走 indexRangeScan 算子,这样速度可以加快。
但是要依赖能不能合理添加这个 updatetime 范围,如果不能好像就无办法。只能期望对这种查询,TiDB 执行计划优化,选择更优的执行计划,等新功能优化版本。
执行: select *from mars_p1log.logoutrole order by updatetime desc limit 1 \G
耗时:1 row in set (3 hours 16 min 56.07 sec)
如你所言,加了索引列的范围查询后,它不再是TableFulScan而且变为了IndexRangeScan_17,响应时间有所缩短
执行: select *from mars_p1log.logoutrole where updatetime>‘2022-06-30 00:00:00’ order by updatetime desc limit 1 ;
但执行计划里仍然要扫描大量的数据,这个问题还是未解决
这个表一直有数据在写入,目前有180亿行左右。
相关列的表结构和索引如下:logoutrole (doc_id varchar(255) NOT NULL DEFAULT ‘’,dt timestamp NOT NULL ,updatetime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ‘更新时间’,dt,doc_id) /*T![clustered_index] NONCLUSTERED */,updatetime (updatetime)storeonssd */dt))p20210601 VALUES LESS THAN (1622563200) /*T![placement] PLACEMENT POLICY=storeonhdd */,p20210602 VALUES LESS THAN (1622649600) /*T![placement] PLACEMENT POLICY=storeonhdd */,p20210805 VALUES LESS THAN (1628179200) /*T![placement] PLACEMENT POLICY=storeonhdd */,p20210806 VALUES LESS THAN (1628265600),p20220810 VALUES LESS THAN (1660147200),p20220811 VALUES LESS THAN (1660233600),p20220812 VALUES LESS THAN (1660320000))
是的,不desc 执行耗时也是很久,原因还是因为执行计划里有 TableFullScan_12
dt是 date time的含义,是时间。
所以,就是在执行这个 order by updatetime或dt limit 1时发现执行很慢的问题
Min_Chen
2022 年7 月 4 日 02:54
19
您好,麻烦 在执行这个 sql 后搜一下连接到的 tidb-server 日志中有没有 buildCopTasks takes too much time 的关键字,辛苦。
另外贴一下 slow.log 中该 sql 的慢日志 和 tidb_decode 的执行计划,感谢。
mysql> select *from mars_p1log.logoutrole order by updatetime desc limit 1 \G
ERROR 1105 (HY000): other error: Coprocessor task terminated due to exceeding the deadline