Renne
2021 年5 月 8 日 02:23
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】4.0.9
【问题描述】
因为要做异地机房的灾备测试,所以将原本6KV6PD4TIDB的群集中的三个节点的网卡关闭。关闭后,从中控机上发现所有节点均显示down状态:
尝试进行scale-in操作踢出关闭网络的模拟异地机房3个节点,因为会进行物理删除,因此不成功。
尝试对群集拓扑结构进行编辑edit-config,报错无法更改。
尝试连接还在线的pd-server进行max-replica,member的修改,没有响应,日志报错failed to publish local member to cluster through raft
使用pd-recover进行pd群集的恢复,报错context deadline exceeded:
想请问下老师这种情况该怎么处理,因为3台pd server的模拟丢失,导致整个群集无法控制,无法更改,期望上应该是将副本数改为3之后直接拉起群集,感谢!
这个信息描述的不清晰, 3 个节点的网卡关闭,所有的节点都显示 down 或 inactive。所以你那里的部署拓扑是单机多实例混布吗?如果允许请将完整的拓扑信息提供下,在便于分析问起的前提下,可隐藏 IP 地址一部分信息,避免完整的信息外露 ~
在多 pd server 无法提供服务的情况下,无法修改 max-replica 以及 member,符合预期 ~
无法使用 tiup 编辑 edit-config 符合预期,目前的产品设计是这样的 ~
这边有几个问题需要确认下:
[image]
[image]
等待一段时间再次查看 da…
Renne
2021 年5 月 8 日 03:44
3
cluster: /root/.tiup/components/cluster/v1.3.2/tiup-cluster edit-config tidb
global:
host: 172.31.6.30
host: 172.31.6.31
host: 172.31.6.32
host: 172.29.6.30
host: 172.31.6.30
host: 172.31.6.31
host: 172.31.6.32
host: 172.29.6.30
host: 172.29.6.31
host: 172.29.6.32
host: 172.31.6.30
tidb的几个组件都是在同一个实例上的,方便测试
3、上面使用 pd-recover 恢复 pd 集群遇到报错,论坛有相关文档可以来参考:
另外,看上去只要有pd存活,pd-ctl就能work,但是为何这个情况下pd-ctl无法工作,并且tiup cluster无法感知仍然存活的tidb组件信息?
pd-ctl 操作的命令会发送给 pd leader,如果 pd 大多数节点无法提供服务,那么这个操作理论上会失败 ~
虽然 –initial-cluster 包含了网络有问题的 3 个 pd 节点,理论上 pd member 的信息会保存在 etcd 中的,单纯的修改 –initial-cluster 可能达不到恢复 pd cluster 的效果 ~
还是建议你那里按照这个文档操作 pd-recover 下,操作步骤中需要重新部署一套全新的 pd 集群,所以涉及到 data-dir 的数据清理(如果担心这个步骤会有风险,那么可以将 data-dir 的目录的数据 copy 一份,然后再清理)~
Renne
2021 年5 月 8 日 06:08
5
删除data目录后进行recover依然报连接错误
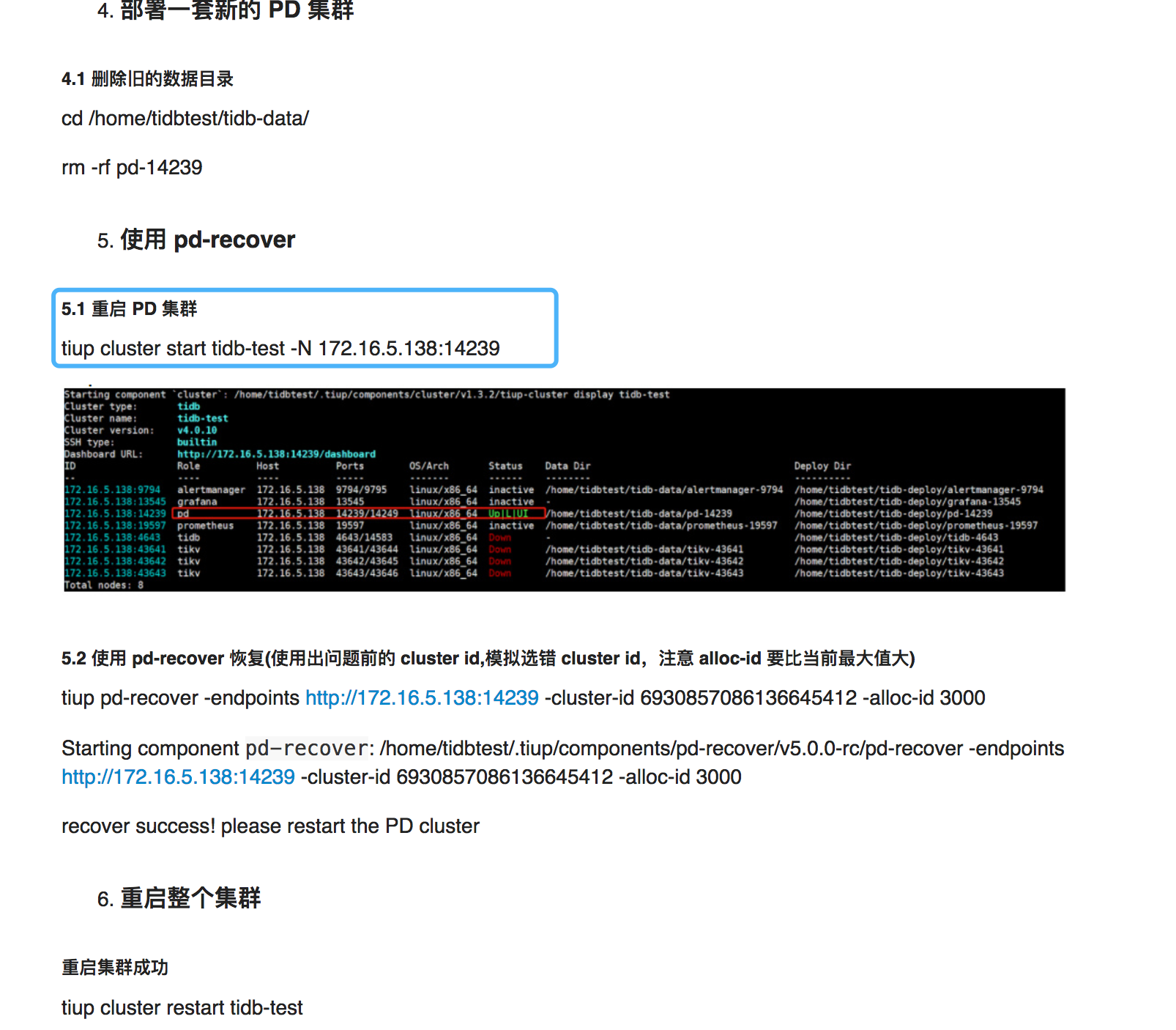
如果是先决定恢复 172.31.6.30:2379 ,那么需要先把这个 pd server start ,然后再用 pd-recover 哈,参考下面的步骤:
Renne
2021 年5 月 8 日 06:22
7
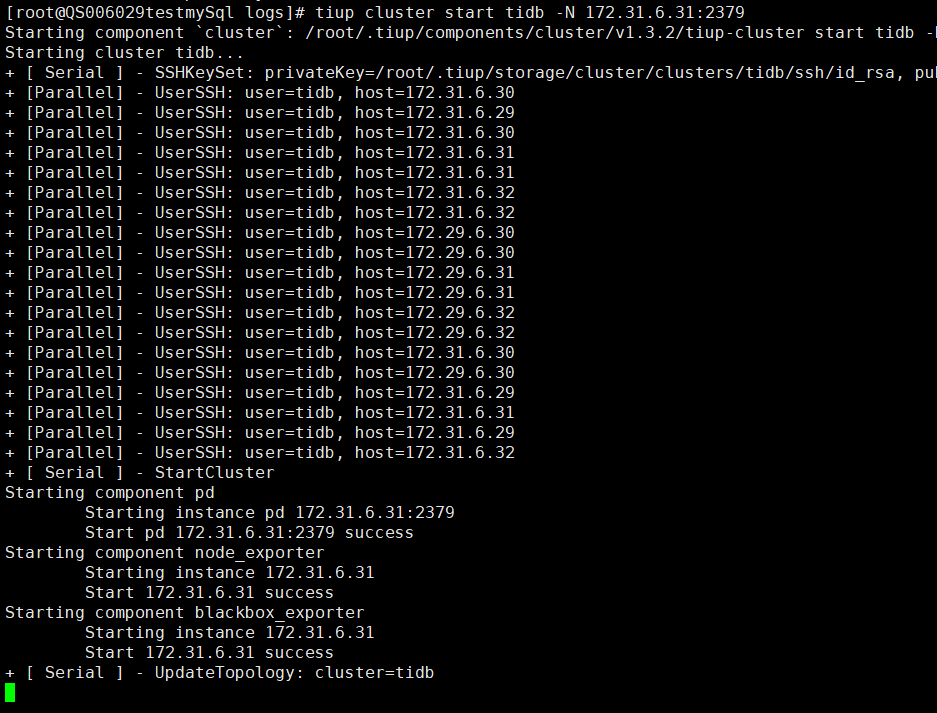
现在启动pd节点会一直hung在+ [ Serial ] - UpdateTopology: cluster=tidb这一步
这个是一个已知问题,请将 tiup 升级至最新版本,然后再尝试重启 pd server 看下:
tiup update --self
tiup update cluster
已打开 12:05PM - 19 May 20 UTC
已关闭 03:23AM - 22 Feb 21 UTC
status/discuss
`tiup cluster start` will statll at `updatetopology` stage and don't exit when s… erver can't connect to pd server.
Suggest to add timeout at `updatetopology`.
Renne
2021 年5 月 8 日 07:09
9
Renne
2021 年5 月 8 日 07:12
10
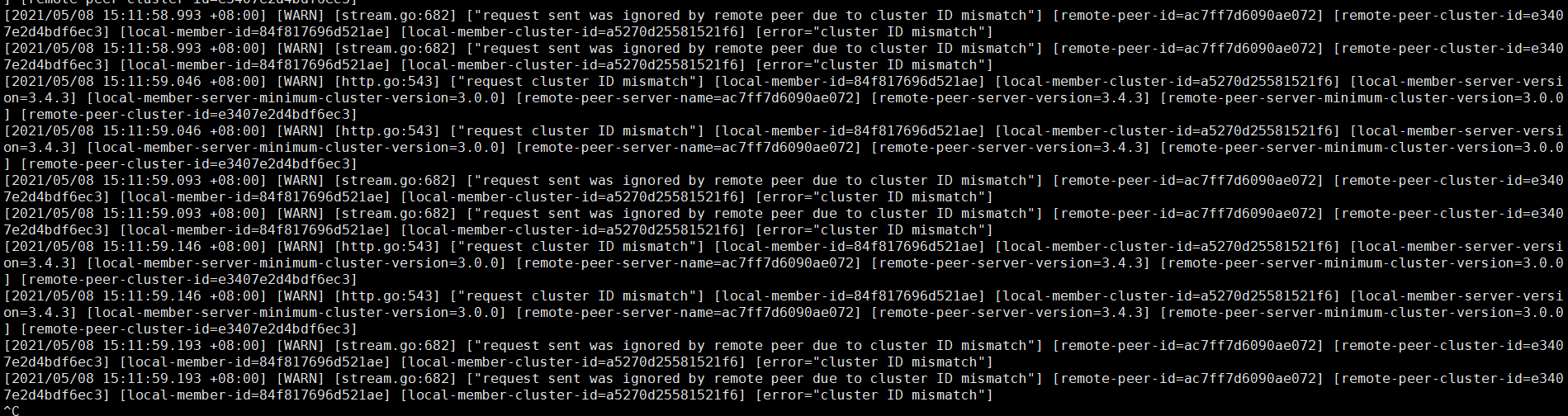
目前因为删除pd data数据,日志中出现大量cluster id not match错误
现在的操作到哪一个步骤了,现在是 pd recover 操作完成了吗?操作完成后,有重启整个 tidb 集群吗?
Renne
2021 年5 月 8 日 07:40
12
最新的情况是pd没法启动了,pd-recover一直没有成功过即丢掉一半的kv节点和pd的情况下,是否已经无法拉起群集 ,那么,如果调整为3pd,1+2或者0+3的分布,是否也会出现这种情况(pd存活数量不足,无法进行选举)?
pd 的选举是通过 etcd 来进行的,所以需要满足多数派。如果调整为 3 个 pd ,idc1 有 2 个 pd ,idc2 有一个 pd,当 idc2 异常无法提供服务时,idc1 仍然有 2 个 pd 节点,满足多数派(3 个 pd 节点存活 2 个)并且能够正常的选举出 leader。反之,如果 idc1 整体无法提供服务,那么 idc2 只有一个 pd,不满足多数派,此时如果想把 pd cluster 拉起,那么需要使用 pd-recover 来进行修复~
综上,一般生产环境理论上配置 3 个 pd 节点即可 ~
回到 pd-recover 问题处理 :
Renne
2021 年5 月 8 日 08:21
14
1.telnet是正常的:
2.另外的2个pd节点已经关闭
3.pd-30的日志文件如下(因为较大删除了部分日志,保留了最新的):pd.log (5.5 MB)
另外,我重新看了下例子的图,发现确实是1+2的pd配置:
1、请上传下 172.31.6.30 2379 这个 pd server 的 run_pd.sh 的内容
2、如果是要在 IDC 间 PD 也实现高可用,那么 3 IDC 部署可能是比较合适的选择。如果是两个 IDC 部署,3 个 PD 节点和 5 个 PD 节点的高可用性基本上没有差别,因为都不可避免一个 IDC 宕机异常无法提供服务,出现 PD 集群因为多数派而无法提供服务的现象,极端情况下都需要使用 PD-Recover 来进行修复 ~
Renne
2021 年5 月 8 日 08:32
16
好的,之前打标签失败误打误撞扩容了6个pd节点,目前看来比较鸡肋…run_pd.sh (884 字节)
确认几个信息:
2、现在的 tiup cluster edit-config {cluster-name} 的信息是怎样的?
另外,下面的这行信息,只保留 pd-172.31.6.30-2379=http://172.31.6.30:2380 ,然后再启动下这个 pd server,然后再使用 pd-recover 恢复看下:
--initial-cluster="pd-172.31.6.30-2379=http://172.31.6.30:2380,pd-172.31.6.31-2379=http://172.31.6.31:2380,pd-172.31.6.32-2379=http://172.31.6.32:2380,pd-172.29.6.30-2379=http://172.29.6.30:2380,pd-172.29.6.31-2379=http://172.29.6.31:2380,pd-172.29.6.32-2379=http://172.29.6.32:2380" \
Renne
2021 年5 月 8 日 09:26
19
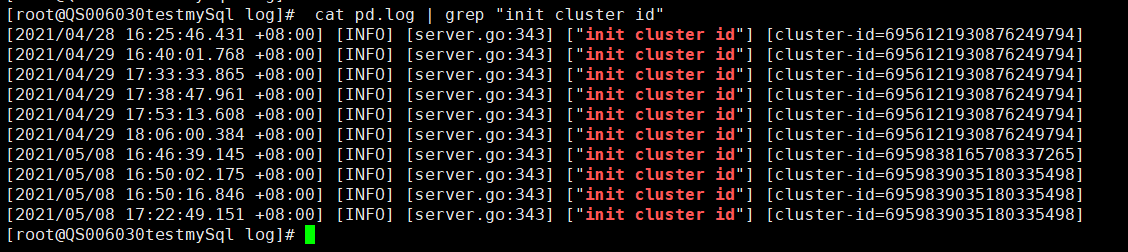
我将30上的run-pd脚本的initial-cluster改为30单个节点后,按照删除data-dir,启动30,pd-recover的顺序确实恢复成功了。pd有了leader之后,缩容操作可以进行,因此将另一个机房的3节点的所有组件缩容下线,修改kv标签为之前的标签,然后将同一机房的31和32的pd缩容,重新扩容,最后重启tidb群集,但是现在kv不认新的pd群集,报错[FATAL] [server.rs:590] [“failed to start node: "[src/server/node.rs:207]: cluster ID mismatch, local 6956121930876249794 != remote 6959839035180335498, you are trying to connect to another cluster, please reconnect to the correct PD"”]
1、你那里先确认下在最最最开始之前,即出现网络故障的时候,那个时间段之前的 pd log 中的 cluster ID 是什么,可以通过 cat pd.log | grep "init cluster id" ,来确认下集群的 cluster id
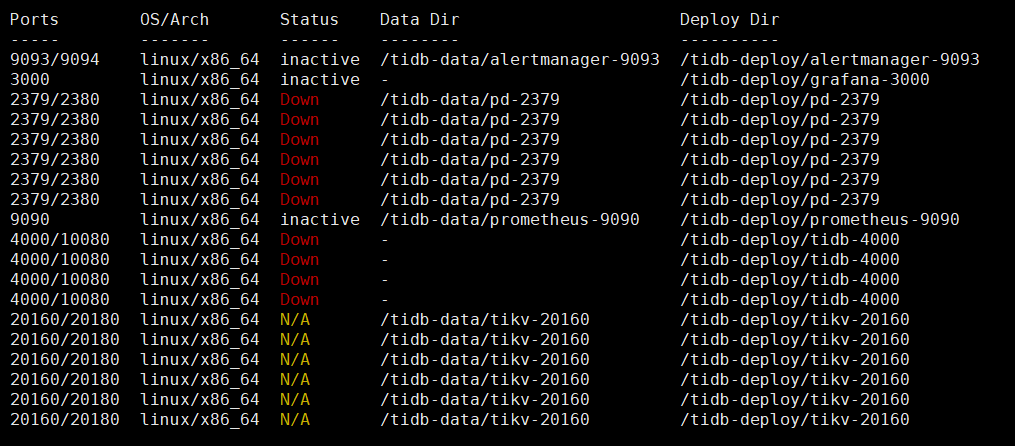
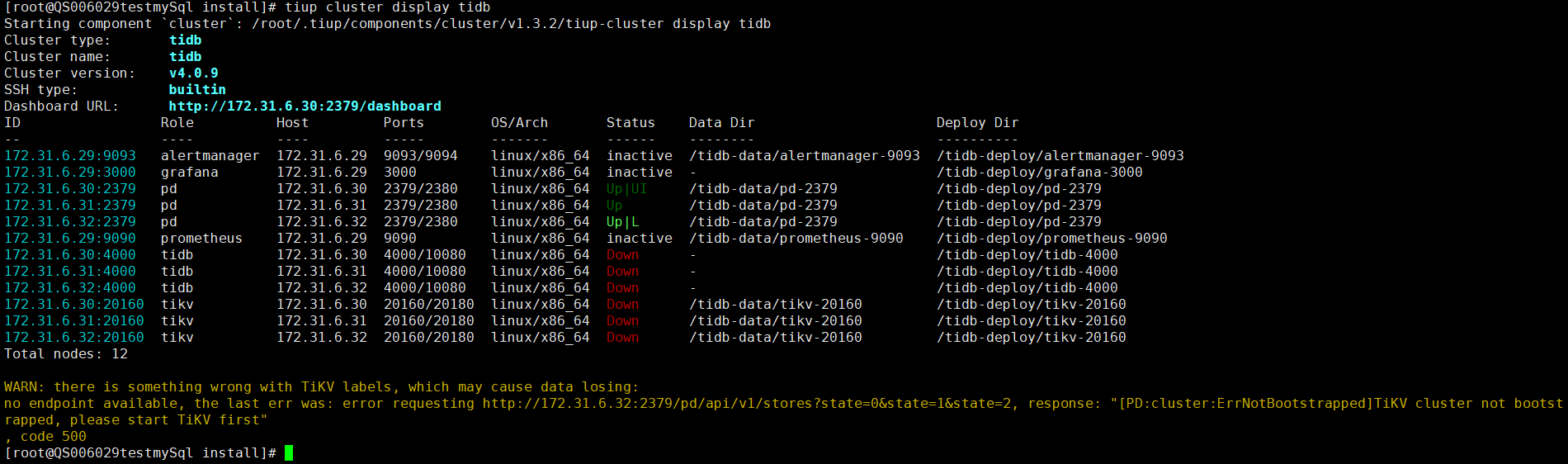
2、上面提到的缩容操作,是把故障的 pd ,tikv 这些节点都缩容掉了吗?tiup cluster display 看下现在的拓扑
Renne
2021 年5 月 8 日 09:40
21
看上去似乎是recover之前和之后都改变了一次,最开始肯定是kv里面那个
现在的拓扑: